

While tech guys obsess over the latest Llama checkpoints, a very serious battle is being fought in the basements of data centers. As AI models reach trillions of parameters, the clusters needed to train them have become some of the most complex and delicate machines on the planet.
Meta AI Research Team Just Released GCM (GPU Cluster Monitoring)The ‘silent killer’ of AI progress: a specialized toolkit designed to solve hardware instability at scale. GCM is a blueprint for managing the hardware-to-software handshake in high-performance computing (HPC).
Problem: When ‘standard’ observation is not enough
In traditional web development, if a microservice lags, you check your dashboard and scale horizontally. In AI training, the rules are different. A single GPU in a 4,096-card cluster can experience a ‘silent failure’ – where it technically remains ‘up’ but its performance degrades – effectively poisoning the gradients for the entire training round.
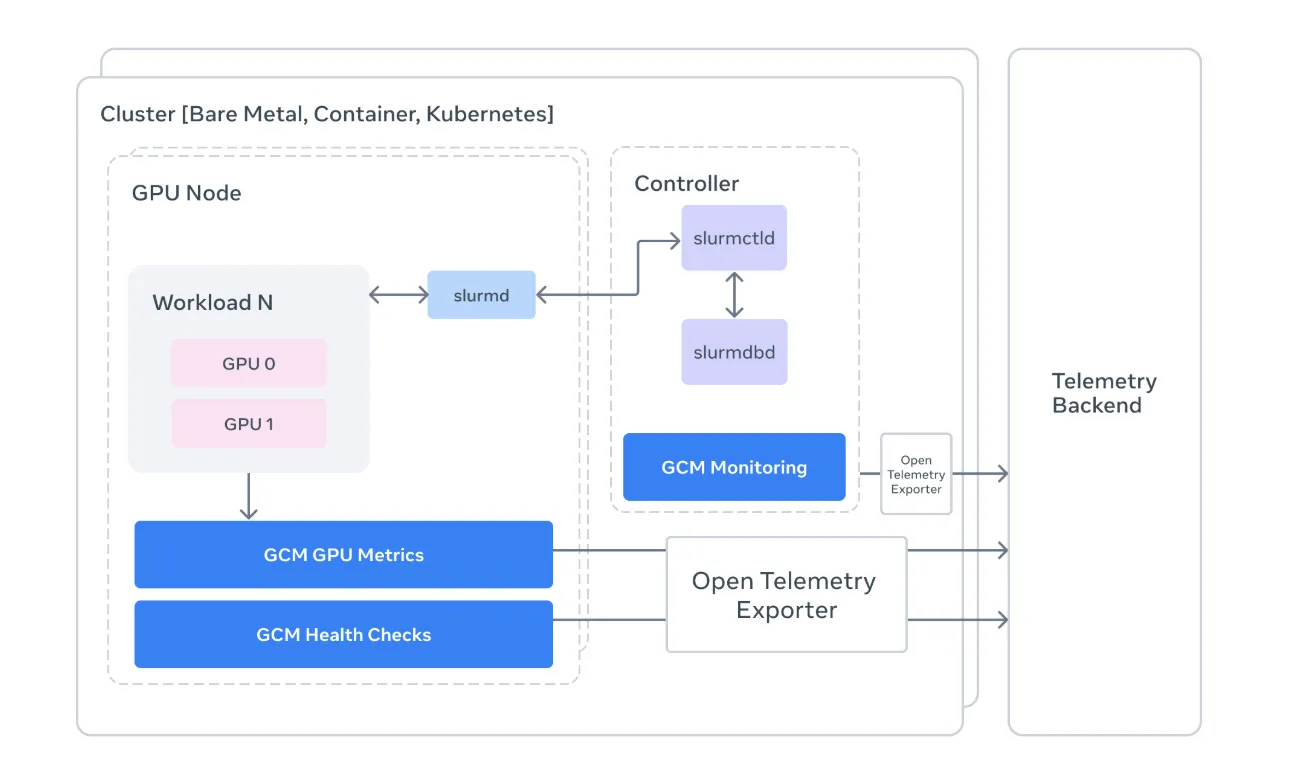
Standard monitoring tools are often too high-end to capture these nuances. of meta gcm Acts as a specialized bridge, connecting the raw hardware telemetry of the NVIDIA GPU to the orchestration logic of the cluster.
1. Monitoring the ‘slum’ route
For the gods, slum There’s the ubiquitous (if sometimes frustrating) workload manager. GCM integrates directly with Slurm to provide context-aware monitoring.
- Task-level attribution: Instead of looking at a general increase in power consumption, GCM allows you to categorize metrics as specific job ID.
- State Tracking: pulls data from it
sacct,sinfoAndsqueueCreating a real-time map of cluster health. If a node is marked asDRAINGCM helps you understand Why Before it ruins a researcher’s weekend.
2. ‘Prologue’ and ‘Epilogue’ Strategy
One of the most technically important parts of the GCM framework is its suite of health checkup. In HPC environments, timing is everything. GCM uses two important windows:
- Preface: These scripts are run First A work begins. GCM checks whether the InfiniBand network is healthy and whether the GPUs are actually accessible. If a node fails the pre-check, the work is diverted, saving hours of ‘dead’ compute time.
- Epilogue: here we go after One task has been completed. GCM uses this window to run in-depth diagnostics NVIDIA’s DCGM (Data Center GPU Manager) To ensure that the hardware does not get damaged while lifting heavy items.
3. Telemetry and OTLP Bridge
For developers and AI researchers who need to justify their compute budget, GCM telemetry processor Is the star of the show. It converts raw cluster data Open Telemetry (OTLP) Format.
By standardizing telemetry, GCM allows teams to pipe hardware-specific data (like GPU temperatures, NVLink errors, and XID events) into a modern observing stack. This means you can finally correlate the drop in training throughput with a specific hardware throttled event, from ‘model is slow’ to ‘GPU 3 on node 50 is overheating.’
Under the Hood: The Tech Stack
The implementation of META is a masterclass in practical engineering. The repository is mainly Python (94%), making it highly extensible for AI developers with performance-critical logic Go.
- Collector: Modular components that collect telemetry from sources
nvidia-smiAnd Slurm API. - sink: ‘Output’ layer. GCM supports multiple syncs, including
stdoutFor local debugging and otlp For production-grade monitoring. - DCGM and NVML: GCM takes advantage of Nvidia Management Library (NVML) To talk directly to the hardware, bypassing higher-level abstractions that may hide errors.
key takeaways
- Bridging the gap of ‘silent failure’: GCM solves a critical AI infrastructure problem: identifying ‘zombie’ GPUs that appear online but crash training runs or produce corrupted gradients due to hardware instability.
- Deep Slum Integration: Unlike general cloud monitoring, GCM is purpose-built for high-performance computing (HPC). It uniquely anchors hardware metrics slum job idAllows engineers to attribute performance degradation or power spikes to specific models and users.
- Automated Health ‘Prolog’ and ‘Epilog’: The framework uses a proactive diagnostic strategy, through which specialized health checks are conducted nvidia dcgm Before a task starts (prolog) and after it ends (epilog) to ensure that faulty nodes are eliminated before wasting costly computation time.
- Standardized Telemetry via OTLP: GCM converts low-level hardware data (temperature, NVLink errors, XID events) Open Telemetry (OTLP) Format. This allows teams to pipe complex cluster data into a modern observability stack like Prometheus or Grafana for real-time visualization.
- Modular, language-agnostic design: Whereas in the original logic it is written Python For access, GCM uses Go For performance-critical sections. Its ‘collector-and-sink’ architecture allows developers to easily plug in new data sources or export metrics to custom backend systems.
check it out repo And project page. Also, feel free to follow us Twitter And don’t forget to join us 120k+ ml subreddit and subscribe our newsletter. wait! Are you on Telegram? Now you can also connect with us on Telegram.
