

In the high-stakes world of AI, ‘context engineering’ has emerged as the latest frontier to squeeze the performance of LLMs. Industry leaders have said AGENTS.md (and its cousins like CLAUDE.md) as the final configuration point for coding agents – a repository-level ‘north star’ injected into every interaction to guide the AI through the complex codebase.
But a recent study by researchers ETH Zurich Just got a massive reality check. The findings are crystal clear: If you’re not brainstorming your reference files, you’re hurting your agent’s performance while paying a 20% premium for the privilege.
Data: More Tokens, Less Success
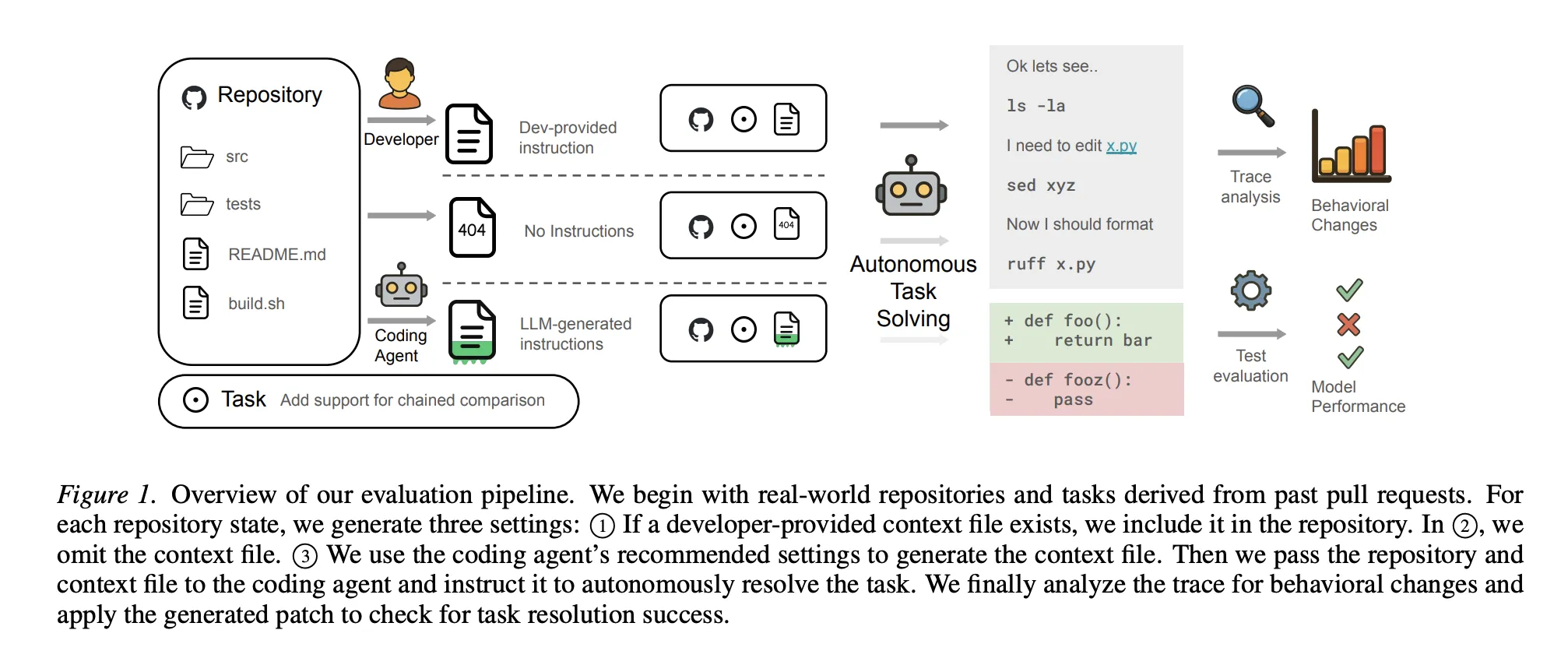
The ETH Zurich research team analyzed coding agents such as Sonnet-4.5, GPT-5.2And QUEN3-30B A new set of established standards and real-world tasks is called agentbench. The results were surprisingly unbalanced:
- generate automatically: actually automatically generated reference files Success rate reduced by about 3%.
- price of help‘: These files increased the estimated cost more than 20% And solving similar tasks required more logical steps.
- human margin: Even human-written files provide only one marginal 4% performance gain.
- intelligence cap: Interestingly, using stronger models (such as GPT-5.2) to generate these files did not yield better results. Strong models often have so much ‘parametric knowledge’ of common libraries that the additional context becomes unnecessary noise.
Why does a ‘good’ context fail?
The research team highlights one behavioral trap: AI agents are very obedient. Coding agents respect the instructions found in reference files, but when those requirements are unnecessary, they make the task harder.
For example, researchers found that codebase overview and directory listings—a major part of most AGENTS.md Files—do not help agents navigate faster. The agents themselves are surprisingly good at discovering file structures; Reading the list manually just consumes reasoning power and adds ‘mental’ overhead. Furthermore, LLM-generated files are often unnecessary if you already have good documentation elsewhere in the repo.

New Rules of Reference Engineering
To make reference files truly useful, you need to move from ‘comprehensive documentation’ to ‘surgical intervention’.
1. What to include (‘something important’)
- Technical Stack and Intent: Explain the ‘what’ and ‘why’. Help the agent understand the purpose of the project and its architecture (for example, a monorepo structure).
- non-obvious tooling: right here
AGENTS.mdShines. Specify how to build, test, and verify changes using specific toolsuvinstead ofpipOrbuninstead ofnpm. - multiplier effect:data refers to that instruction Are followed; Tools mentioned in a reference file are used more frequently. For example, equipment
uvused 160x more times (1.6 times per example vs 0.01) when explicitly mentioned.+1
2. What to keep out (‘noise’)
- detailed directory tree: Leave them. Agents can find the files they need without a map.
- style guides: Don’t waste tokens by telling an agent to “use CamelCase”. Use deterministic linters and formatter instead—they’re cheaper, faster, and more reliable.
- task-specific instructions: Avoid rules that apply to only a fraction of your problems.
- Uncertified Auto-Content: Don’t let an agent write your own reference file without human review. The study proves that ‘stronger’ models do not necessarily make better guides.
3. How to structure it
- keep it lean: Consensus for high-performance reference files under 300 lines. Professional teams often keep their lines even more restrictive—less than 60 lines. Every line counts because every line is included in every session.
- progressive disclosure: Don’t put everything in the root file. Use the master file to point the agent to separate task-specific documents (for example,
agent_docs/testing.md) only when relevant. - pointer on copies: Instead of embedding code snippets that will eventually become stale, use this Signal (As,
file:line) to show the agent where to find a design pattern or specific interface.
key takeaways
- Negative impact of auto-generation:LLM-generated reference files reduce task success rates by approx. 3% On average compared to not providing any repository references at all.
- significant cost increases: Including reference files increases estimation cost more than 20% And the number of steps required for agents to complete tasks becomes greater.
- minimum human benefit: While human-written (developer-provided) reference files perform better than automatically generated files, they provide only minor improvements 4% Without using any reference file.
- Redundancy and navigation: Detailed codebase overviews in reference files are largely redundant with existing documentation and do not help agents find relevant files faster.
- follow strict instructions: Agents generally respect the instructions given in these files, but unnecessary or overly restrictive requirements often make it hard for the model to solve real-world tasks.
check it out paper. Also, feel free to follow us Twitter And don’t forget to join us 120k+ ml subreddit and subscribe our newsletter. wait! Are you on Telegram? Now you can also connect with us on Telegram.
