

Discussions of business transformation increasingly centre on artificial intelligence, but much of the attention has gone to generative models that handle unstructured content such as text, images, and audio. A large share of core business processes, however, still runs on classical machine learning applied to structured, tabular data. TabPFN, a tabular foundation model from Prior Labs, aims to bring the “pre-trained, ready-to-use” approach of large language models to that structured-data world — and a Databricks commentary outlines how it fits into an enterprise data platform.
These days, it’s difficult to find a business magazine, quarterly earnings call, industry white paper, or strategy presentation on business transformation that doesn’t focus on Artificial Intelligence (AI). Modern AI represents a fundamental shift in how organizations approach content consumption, interpretation, and generation, enabling businesses to enhance and automate a wide range of tasks that previously required deep expertise and years of specialized knowledge.
But AI’s ability to understand and curate unstructured content has caught everyone’s attention. i.e, text, images, audio, etc.Many, many core business processes have long relied on classical machine learning (ML), a different, though related, technology that produces predictive labels from structured data inputs (Figure 1). Until now, the transformative power of AI has left classical ML largely unchanged.
The robustness of traditional ML workflows stems from their inherent complexity and labor intensity. Data scientists routinely spend more than 80% of their time on activities that occur before model training begins: structuring data input, preparing and validating engineering features, and selecting the right model class. Furthermore, since the underlying data distribution changes and model performance degrades over time, this work is not a one-time investment, but an ongoing cycle of monitoring, debugging, and retraining.
On a larger scale, this challenge becomes acute. Organizations deploying hundreds, if not thousands, of ML models rely on automated experimentation frameworks to evaluate thousands of parameter combinations. But even automation cannot overcome fundamental resource constraints.
The reality is clear: Companies must choose which models to focus on optimization and which models are “good enough” given limited resources and the need to quickly transform business results. But the emergence of new AI models focused on structured data inputs and predicted outputs may ultimately offer a way forward.
Video 1. Interaction with the TabPFN model as part of the Databricks Solution Accelerator
Introducing TabPFN, an AI Model for Machine Learning
One of the most promising developments in this field tabpfnA Foundation (AI) Model East Labs Which fundamentally reimagines the machine learning (ML) workflow for structured data. Unlike traditional ML approaches, which require building and training a unique model for each prediction task, TabPFN applies the same “pre-trained, ready-to-use” paradigm from ML to tabulated business data. The model was pre-trained on over 130 million synthetic datasets, effectively “learning how to learn” from structured data in virtually any domain or use case (Figure 1).
Collapsing ML Timeline
The implications for ML productivity are dramatic. Where traditional approaches require data scientists to invest hours or days in data preparation, feature engineering, model selection, and hyperparameter tuning, TabPFN provides production-grade predictions in a single forward pass, typically measured in seconds.
The model directly handles the raw input, automatically handling missing values, mixed data types, categorical and text features, and outliers without the need for extensive preprocessing that typically consumes most data science effort. Perhaps most importantly, TabPFN eliminates the ongoing maintenance burden of model retraining: as new data becomes available, organizations simply update the model context rather than starting a new training cycle.
Performance without trade-offs
TabPFN exceeds the accuracy of traditional methods that require hours of automated tuning. This performance profile fundamentally changes the economics described earlier: organizations no longer face a binary choice between model accuracy and resource allocation. Instead, they can rapidly deploy predictive capabilities across a wide range of use cases without proportionally growing their data science teams, democratizing ML beyond the handful of highest-value applications that typically justify dedicated optimization efforts (Figure 2).
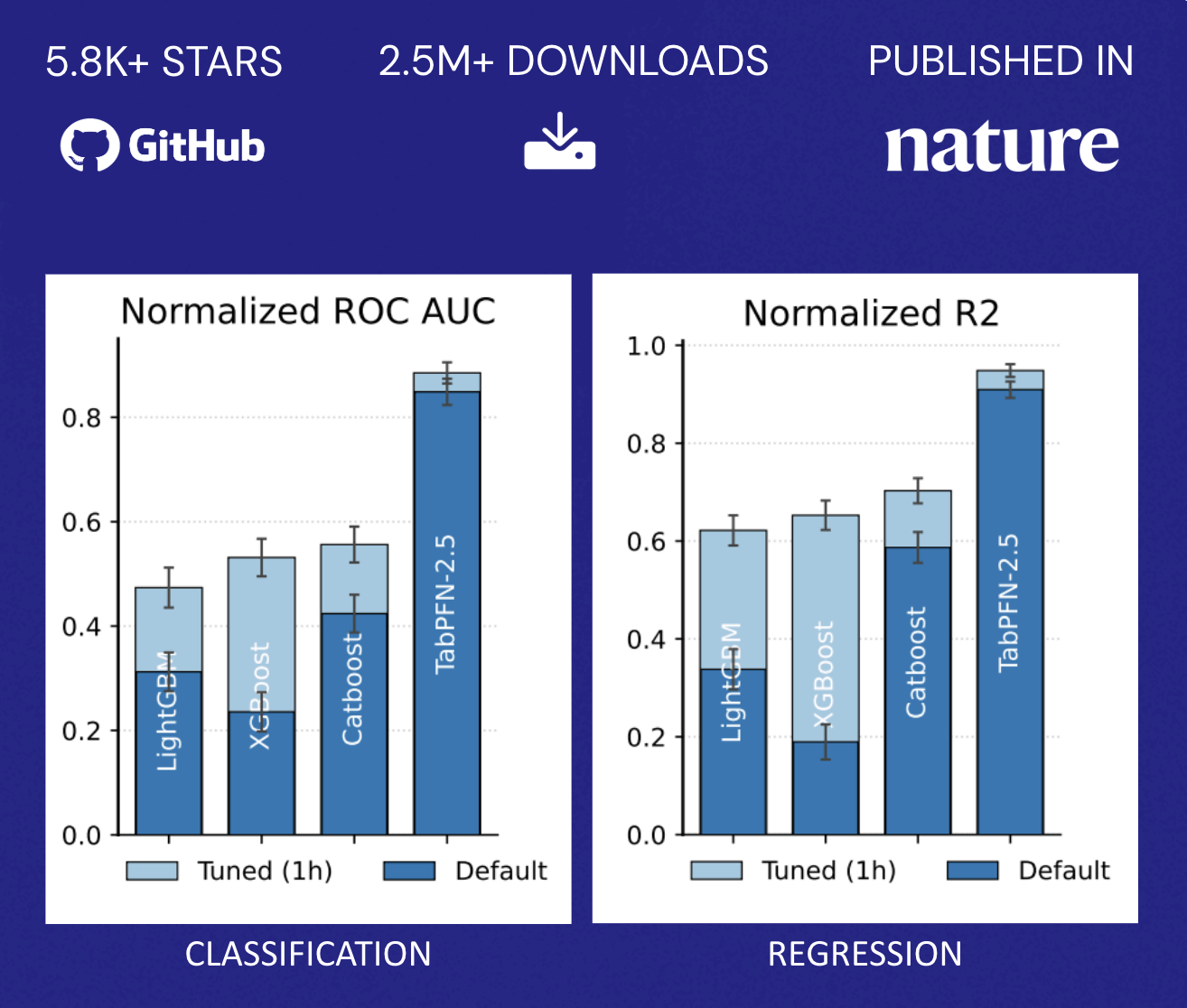
Scaling the impact of AI for structured prediction
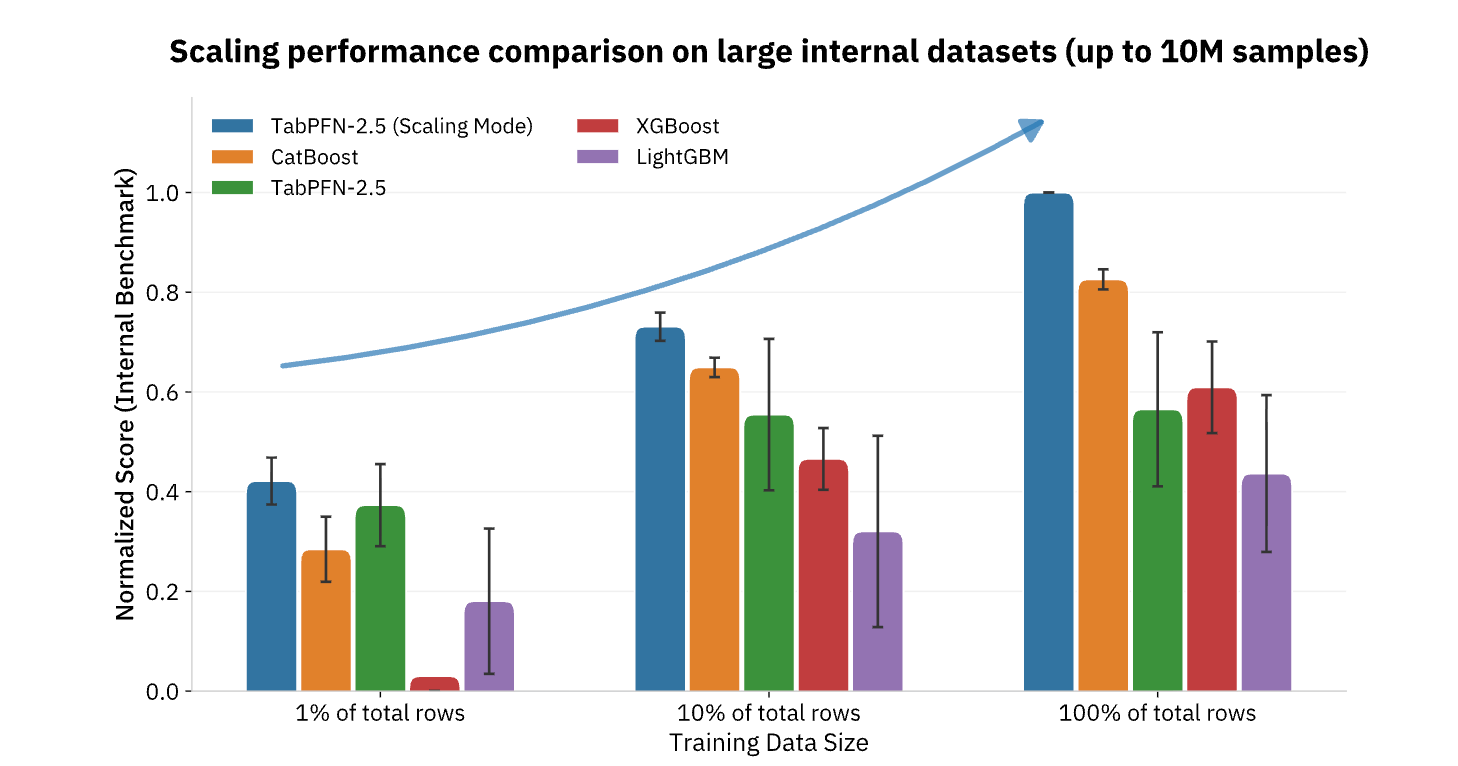
TabPFN currently supports datasets up to 100,000 rows and 2,000 features Enterprise Edition Expanded to 10 million rows, covering the vast majority of operational ML usage in retail, finance, healthcare, manufacturing and other industries. For organizations seeking to operationalize AI beyond content creation and natural language tasks, foundation models like TabPFN represent the missing piece, bringing the same step-function productivity improvements to structured data and predictive analytics that have long been the backbone of data-driven decision making (Figure 3).
TabPFN is already powering many real-world applications for companies around the world. From financial risk management to deployment in various sectors tactilewith health outcome assessment NHSand with predictive maintenance HitachiAn increase in both efficiency and quality of results has been observed. TabPFN consistently outperforms traditional ML methods, improving baselines by 10%-65% and speeding up data science workflows by up to 90%. Organizations are benefiting from increased revenues, improved health outcomes, maintenance cost savings, churn prevention and more.
Using TabPFN with Databricks
Databricks has long been the platform of choice for data scientists looking to build predictive capabilities with machine learning (ML). As an open platform, TabPFN is suitable for use within the Databricks platform.
Build where data lives
Most enterprises start with a classical ML lakehouse of data: transactions, operational telemetry, customer events, inventory signals, and risk indicators. Moving that data to external environments slows down teams, creating duplication, increasing security risks, and weakening reproducibility and auditability. Databricks enables TabPFN workflows with directly controlled data, so teams can minimize data movement while maintaining control. With Unity Catalog, organizations centralize access controls and auditing and preserve lineage across data and AI assets, which matters when teams need to prove what data was accessed, how features were obtained, and who had access at the time of the decision.
Implement results efficiently
TabPFN is a modeling approach. To create production impact, it needs to be integrated with repeatable enterprise patterns like batch and real-time scoring, evaluation, administration, and monitoring. Databricks is a robust platform for these workflows, with scalable computation and real-time estimation infrastructure that can turn TabPFN into a reliable operational process. For evaluation and monitoring, MLflow provides experiment tracking and a model registry to manage versioning, lineage and promotion workflows in an auditable manner.
Provide sustainable model governance
Databricks provides continuous monitoring of TabPFN model performance, detecting when predictions begin to diverge from actual business outcomes. When adjustments are needed, TabPFN’s architecture eliminates traditional week-long retraining cycles: teams update the model context with recent data and redeploy within minutes instead of days. This combination of automated monitoring and rapid refresh capability ensures that forecast quality remains consistent with changing market conditions, while dramatically reducing the data science resources typically required for ongoing model maintenance.
To help teams test TabPFN with minimal setup, we published a publicly available solution accelerator This shows how to run TabPFN end-to-end on Databricks with governed Lakehouse data. The accelerator consists of a series of notebooks that realistically simulate data from various industry scenarios and make predictions using TabPFN (Video 1).
Get started today, bring the transformative power of AI to their ML workloads and drive complete business process transformation.
Limitations and what to watch
TabPFN’s strengths come with important boundaries. The model, published in Nature in 2025, was designed and benchmarked primarily for small-to-medium tabular datasets — roughly up to the order of ten thousand samples and a limited number of features — so claims about broad, trade-off-free performance should be read with that scope in mind; very large datasets may still favour established methods such as gradient-boosted trees. Performance comparisons and efficiency figures originate largely from the model’s authors and from Databricks, and warrant independent validation on a given organization’s own data. As with any model, in-context updating reduces but does not remove the need to monitor for data drift and to govern how predictions are used. The transferable point is that foundation models for tabular data are a genuinely new option worth testing, not an automatic replacement for existing pipelines.
The model is documented by Prior Labs and in the peer-reviewed paper in Nature. For related reading on this site, see coverage of choosing the right modelling approach and building on Databricks.