
In the field of visual-language models (VLM), the ability to bridge the gap between visual perception and logical code execution has traditionally faced performance trade-offs. Many models excel at describing an image but struggle to translate that visual information into the rigorous syntax required for software engineering. Zipu AI (Z.AI) GLM-5V-Turbo is a vision coding model specifically designed to address this through Native Multimodal Coding and customized training paths for agentic workflows.
Documented Training and Design Options: Basic Multimodal Fusion
One main technical difference of GLM-5V-Turbo is Native Multimodal Fusion. In many previous generation systems, vision and language were treated as separate pipelines, where a vision encoder would generate a text description for a language model to process. GLM-5V-Turbo uses a native approach, meaning it is designed to understand multimodal inputs including images, videos, design drafts, and complex document layouts as primary data during its training phases.
Model performance is supported by two specific documented design options:
- CogViT Vision Encoder: This component is responsible for processing visual input, ensuring that spatial hierarchy and fine visual details are preserved.
- MTP (Multi-Token Prediction) Architecture: This option is intended to improve inference efficiency and reasoning, which is important when the model must output long sequences of code or navigate complex GUI environments.
These options allow the model to maintain 200K reference windowThat enables it to process large amounts of data, such as extensive technical documentation or long video recordings of software interactions, while supporting high output capacity for code generation.
30+ Tasks to Learn Joint Reinforcement
One of the key challenges in VLM development is the ‘see-saw’ effect, where improving the visual identity of a model can lead to degradation of its programming logic. To mitigate this, GLM-5V-Turbo was developed using 30+ Tasks Joint Reinforcement Learning (RL).
This training method involves optimizing the model to thirty different tasks simultaneously. These functions span multiple domains essential to engineering:
- STEM Argument: Maintain the logical and mathematical foundations necessary for programming.
- Visual grounding: The ability to accurately identify coordinates and properties of elements within a visual interface.
- Video Analysis: Interpreting temporal changes, which is necessary for debugging animations or understanding user flow in a recorded session.
- Use of equipment: Enabling models to interact with external software tools and APIs.
By using combined RL, the model achieves a balance between visualization and programming capabilities. This is particularly relevant gui agent-AI systems that must “see” a graphical user interface and then generate the code or commands necessary to interact with it.
Integration with OpenGL and Cloud Code
The utility of GLM-5V-Turbo is highlighted by its adaptation to specific agentive ecosystems. Rather than acting as general purpose AI, the model is built for deep optimization included within the workflow open paw And cloud code.
Optimized for OpenGL workflows
OpenClaw is an open-source framework designed for building agents that work within graphical user interfaces. GLM-5V-Turbo Integrated and optimized for OpenClaw workflowsThe environment serves as a basis for tasks such as deployment, development, and analysis. In these scenarios, the model’s ability to process design drafts and document layouts is used to automate the setup and manipulation of the software environment.
Visually Grounded Coding with Cloud Code
model also Works with frameworks like Cloud Code for a visually grounded coding workflow. This is especially useful in ‘claw scenarios’, where the developer may need to provide a screenshot of a bug or a mockup of a new feature. Because GLM-5V-Turbo natively understands multimodal input, it can interpret visual layouts and provide code suggestions that are based on visual evidence provided by the user.
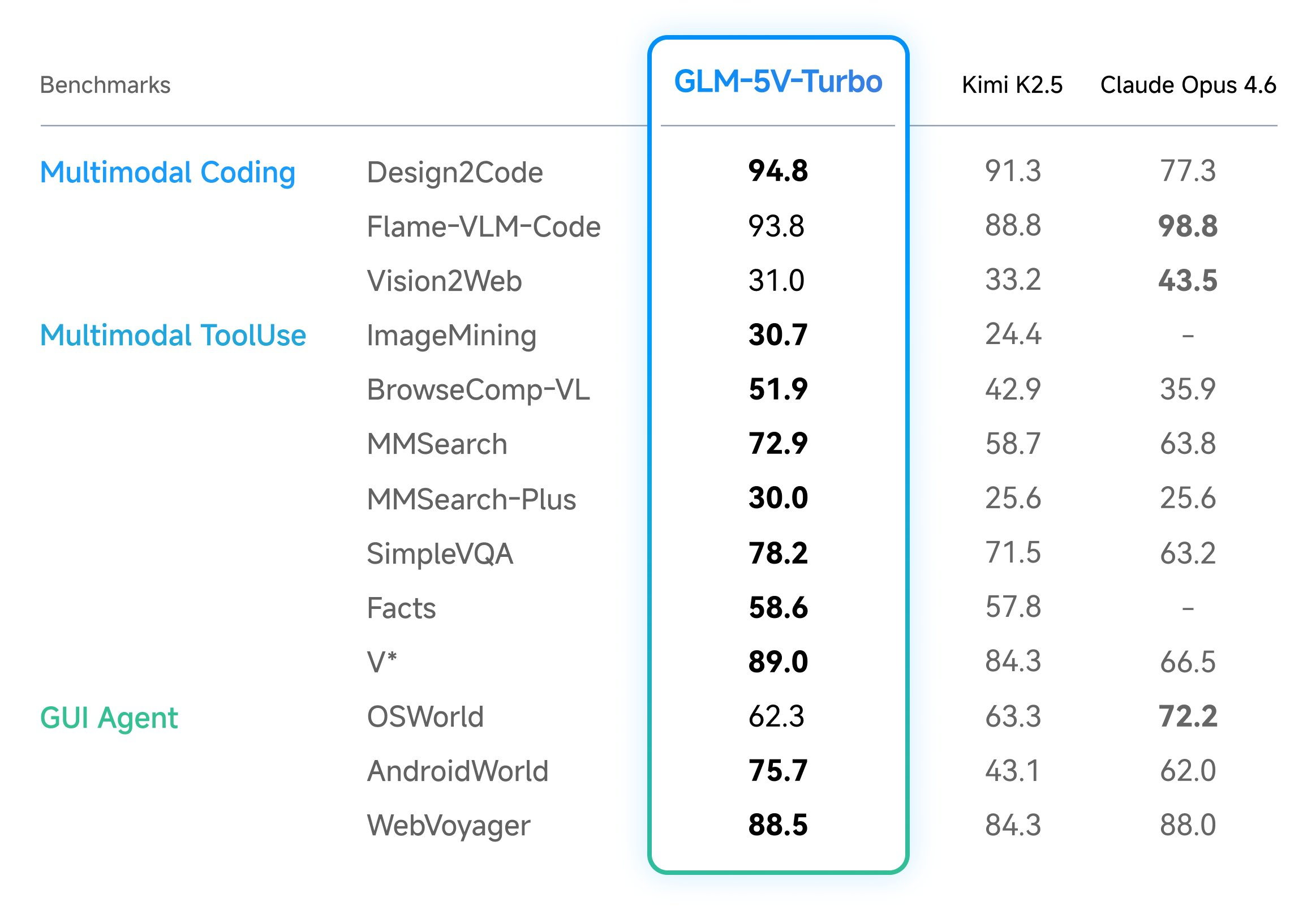
Benchmarks and Performance Verification
The effectiveness of these design choices is measured through a suite of core benchmarks that focus on multimodal coding and tool usage. For engineers evaluating models, Three documented benchmarks are central:
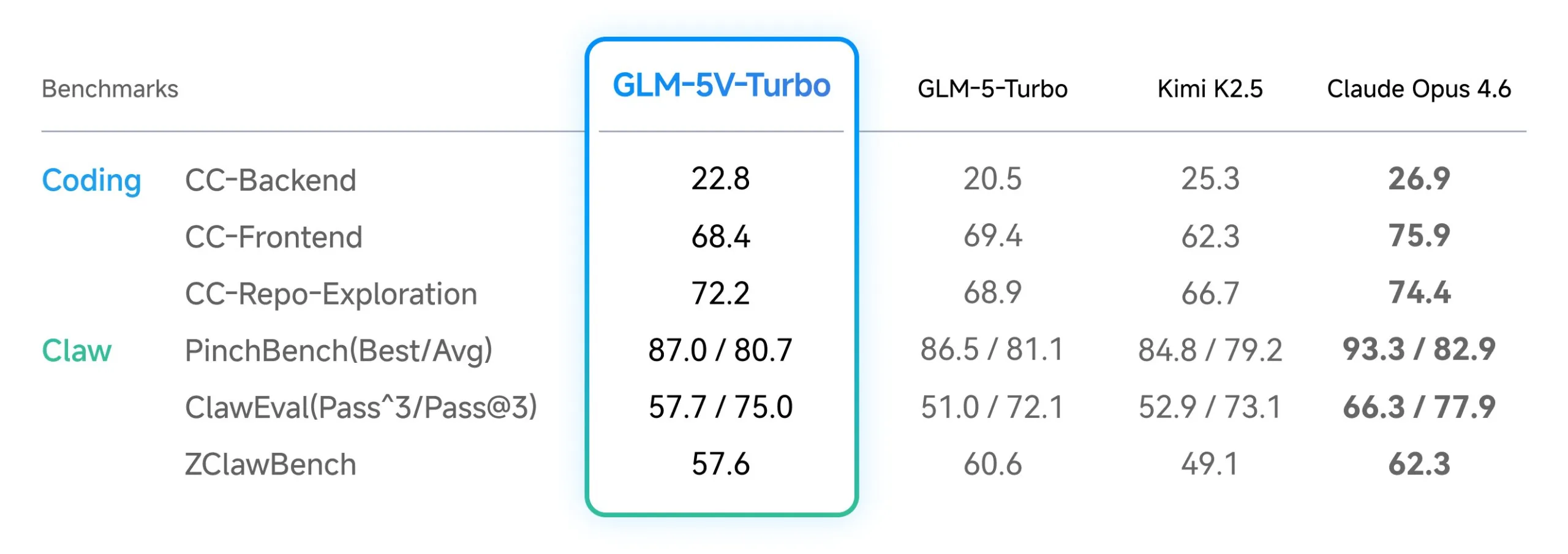
| benchmark | technical focus |
| cc-bench-v2 | Evaluates multimodal coding across backend, frontend, and repository-level tasks. |
| ZClawBench | Measures the effectiveness of the model in OpenClaw-specific agent scenarios. |
| ClawEval | Tests model performance in multi-step execution and environment interactions. |
These metrics indicate that the GLM-5V-Turbo maintains leading performance in tasks that require high-fidelity document layout understanding and the ability to visually navigate complex interfaces.
key takeaways
- Native Multimodal Fusion: It natively understands images, videos, and document layouts CogViT Vision EncoderEnabling direct ‘vision-to-code’ execution without intermediate textual descriptions.
- Agentic Adaptation: The model is specially integrated open paw And cloud code Mastering the ‘perceive → plan → execute’ loop for workflows, autonomous environment interactions.
- High-Throughput Architecture: It uses an estimate-friendly MTP (Multi-Token Prediction) architecture, support of one 200K reference window and by 128K output token For repository-scale tasks.
- Balanced Training: Through 30+ Tasks to Learn Joint ReinforcementIt maintains rigorous programming logic and STEM logic while enhancing its visual perception capabilities.
- Benchmark: It provides SOTA performance including exclusive agentive leaderboards cc-bench-v2 (coding/repo exploration) and ZClawBench (GUI agent interaction).
check it out technical details And try it here. Also, feel free to follow us Twitter And don’t forget to join us 120k+ ml subreddit and subscribe our newsletter. wait! Are you on Telegram? Now you can also connect with us on Telegram.