

Writing fast GPU code is one of the hardest specializations in machine learning engineering. The researchers at RightNow AI want to automate this completely.
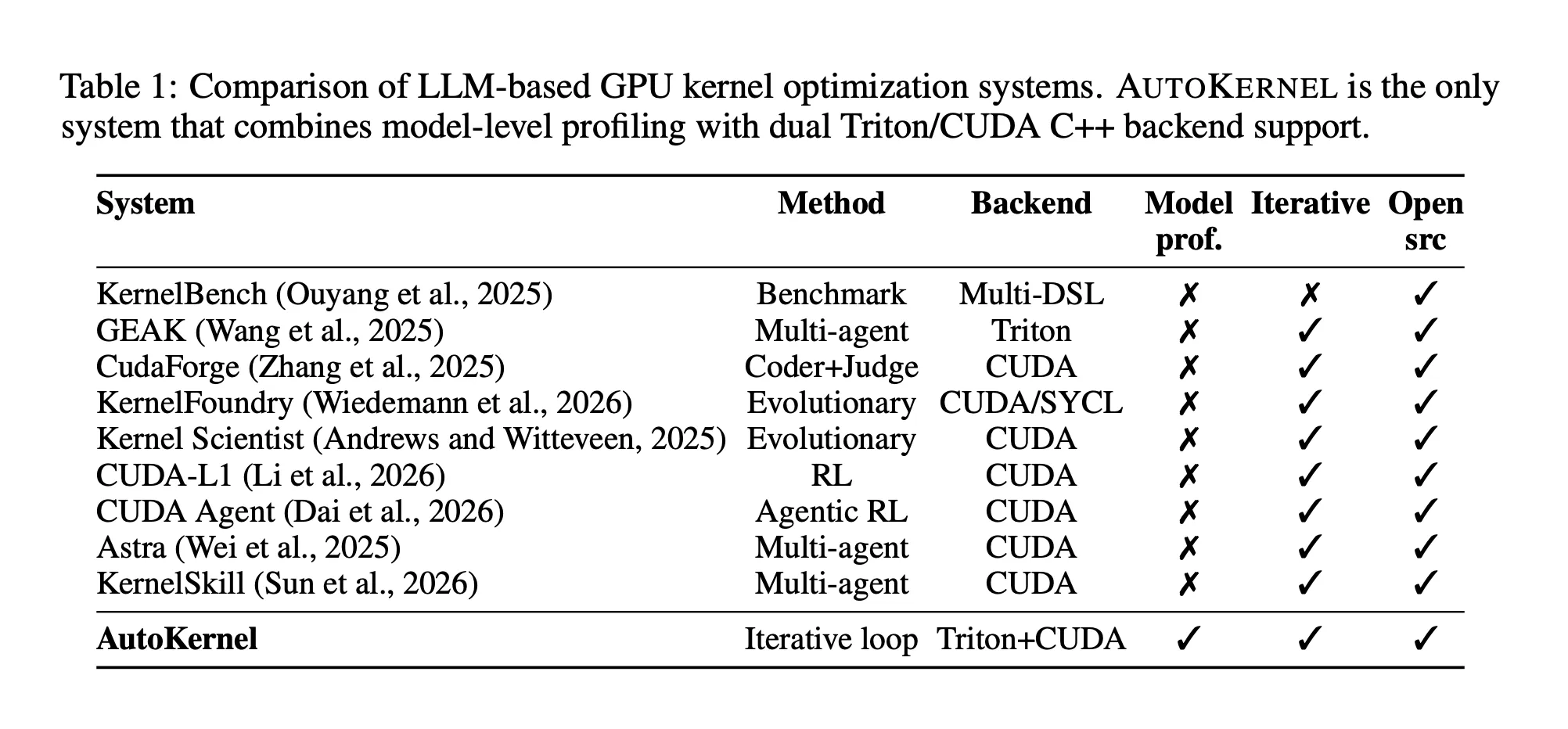
The RightNow AI research team has released AutoKernel, an open-source framework that implements an autonomous LLM agent loop for GPU kernel optimization for arbitrary PyTorch models. The approach is straightforward: given any model overnight, it produces a fast Triton kernel – no GPU expertise required.

Why is it so hard to optimize the GPU kernel?
A GPU kernel is a function that runs in parallel across thousands of GPU cores. When running Transformer models like LLaMA or GPT-2, the bulk of the computation time is spent inside the kernel for operations like matrix multiplication (Matmul), softmax, layer normalization, and attention. These kernels reside in libraries like cuBLAS and cuDNN, or are automatically generated by PyTorch’s compilation pipeline.
The problem is that squeezing maximum performance from these kernels requires simultaneous reasoning about arithmetic intensity, memory coalescing, register pressure, tile size, warp-level synchronization, and tensor core instruction selection – a combination of skills that takes years to develop. A single high-performance MatMull kernel can contain 200+ lines of CUDA or Triton code with dozens of interdependent parameters. This expertise is rare, and as model architectures evolve, the manual tuning process becomes worse.
The benchmark suite KernelBench, which evaluates Frontier LLM on 250 GPU kernel problems, found that even the best models using one-shot generation match PyTorch baseline performance in less than 20% of the cases. Autokernel was created in direct response to that gap.
Loop: Edit, Benchmark, Keep or Revert
The key insight of Autokernel is that the workflow of an expert kernel engineer is itself a simple loop: write a candidate, benchmark it, keep improving, discard regressions, repeat. The framework orchestrates this loop. An LLM agent modifies a single file – the kernel.xml – harnesses a certain benchmark to verify correctness and measure throughput, and the result determines whether the change persists or not. The important thing is that each experiment maps to a Git commit. The experiments kept move the branch forward; Reverse experiments are clearly deleted git reset. The entire history is browsable with standard Git tools, and the results of the experiment are logged to a plain tab-separated results.tsv file – dependency-free, human-readable, and trivially parseable by the agent.
Each iteration takes about 90 seconds – 30 seconds for correctness checking, 30 seconds for performance benchmarking via Triton’s do_bench, and 30 seconds for agent logic and code modification. At about 40 experiments per hour, a 10-hour overnight run yields 300 to 400 experiments across multiple kernels.
This design is taken directly from Andrej Karpathy’s AutoResearch project, which showed that an AI agent running keep/revert loops on LLM training code could find 20 optimizations in 700 experiments over two days on a single GPU. The autokernel transplants this loop into the kernel code, with a separate search space and purity-gated benchmarks as the evaluation function instead of the validation loss.
The agent reads a 909-line instruction document called program.md, which encodes expert knowledge into a six-level optimization playbook. Levels progress from block size tuning (wider tile dimensions via powers of 2, adjusting num_warps and num_stages), through memory access patterns (coalesced load, software prefetching, L2 swizzling), compute optimizations (TF32 accumulation, epilogue fusion), advanced techniques (split-k, persistent kernels, Triton autotune, warp specialization), architecture-specific strategies (TMAs on Hoppers). cp.async on Ampere, size adjusted for L4/RTX), and finally kernel-specific algorithms like online softmax for attention and Welford’s algorithm for normalization. The instruction document is intentionally comprehensive so that the agent can work for 10+ hours without getting stuck.
Profiling first, optimizing where it counts
Unlike previous work, which considers kernel problems in isolation, AutoKernel starts from a complete PyTorch model. It uses Torch.Profiler with size recording to capture per-kernel GPU time, then ranks optimization targets using Amdahl’s law – the mathematical principle that the overall speedup achievable is limited by how much of the total runtime that component represents. A 1.5× speedup on a kernel consuming 60% of the total runtime gives a 1.25× end-to-end gain. The same speedup on a kernel consuming 5% of runtime yields only 1.03×.
The profiler detects GPU hardware from a database of known specifications covering both NVIDIA (H100, A100, L40S, L4, A10, RTX 4090/4080/3090/3080) and AMD (MI300X, MI325X, MI350X, MI355X) accelerators. For unknown GPUs, it estimates peak FP16 throughput from SM count, clock rate and compute capacity – making the system usable across a wider range of hardware than just the latest NVIDIA offerings.
Orchestrator (orchesstrate.py) transitions from one kernel to another when one of four conditions is met: five consecutive reverts, reaching 90% of GPU peak utilization, two hours of elapsed time budget, or a 2× speedup already achieved on that kernel. This prevents the agent from spending excessive time on low-return kernels while high-impact targets wait.
Five-Step Correction Harness
Performance is useless without correctness, and the autokernel is particularly thorough on this front. Each candidate kernel goes through five validation steps before any speedup is recorded. Stage 1 runs a smoke test on a small input to catch compilation errors and size mismatches within a second. Stage 2 sweeps in 8 to 10 input configurations and three data types – FP16, BF16 and FP32 – to catch size-dependent bugs such as border handling and tile remainder logic. Stage 3 tests numerical stability under adversarial inputs: for softmax, rows of large similar values; For Mutmul, extreme dynamic range; For generalization, near-zero variance. Step 4 verifies determinism by running the same input three times and requiring bitwise identical outputs, which captures race conditions in parallel reduction and non-deterministic atoms. Step 5 tests non-power-of-two dimensions such as 1023, 4097, and 1537 to uncover masking bugs and tile remainder errors.
Tolerances are dtype-specific: FP16 uses atol = 10⁻², BF16 uses 2 × 10⁻², and FP32 uses 10⁻⁴. In the paper’s full evaluation across 34 configurations on an NVIDIA H100, all 34 eager, compiled, and custom kernels proved correct with zero failures in output.
Dual Backend: Triton and CUDA C++
Autokernel supports both Triton and CUDA C++ backends within the same framework. Triton is a Python-like domain-specific language that JIT compiles in 1 to 5 seconds, making it ideal for fast iteration – the agent can modify block size, warp count, pipeline stages, accumulator precision, and loop structure. Triton routinely reaches 80 to 95% of cuBLAS throughput for Matmul. CUDA C++ is included for cases that require direct access to warp-level primitives, WMMA tensor core instructions (using 16×16×16 pieces), vectorized loads via Float4 and Half2, bank-conflict-free shared memory layout, and double buffering. Both backends expose the same kernel_fn() interface, so the benchmark runs identically regardless of the infrastructure backend.
The system covers nine kernel types covering the major operations in modern Transformer architectures: matmul, flash_attention, fused_mlp, softmax, layernorm, rmsnorm, cross_entropy, rotary_embedding and less. Each has a PyTorch reference implementation in reference.py that acts as a correctness oracle, and benchmarks the roofline utilization against detected GPU peaks, as well as calculating throughput in TFLOPS or GB/s.
Benchmark results on H100
Measured against torch.compile with PyTorch eager and max-autotune on an NVIDIA H100 80GB HBM3 GPU (132 SMs, compute capability 9.0, CUDA 12.8), the results for the memory-bound kernel are significant. RMSNorm achieves 5.29× over eager and 2.83× over torch.compile at the largest test size, reaching 2,788 GB/sec – 83% of the H100’s 3,352 GB/sec peak bandwidth. Softmax reaches 2,800 GB/s with 2.82× speedup over eager and 3.44× over torch.compile. Cross-entropy achieves 2.21× over eager and 2.94× over torch.compile, reaching 2,070 GB/s. The advantage over these kernels comes from fusing multi-operation Aten decomposition into a single-pass Triton kernel that reduces HBM (high bandwidth memory) traffic.
The auto kernel performs better on 12 of the 16 representative configurations benchmarked in the paper, while torch.compile with max-autotune is running its own Triton autotuning. TorchInductor’s general fusion and autotuning does not always get the specific tiling and reduction strategies that kernel-specific implementations exploit.
MatMull is particularly tough – PyTorch’s cuBLAS backend is largely tuned according to GPU architecture. Triton Starter reaches 278 TFLOPS, which is well below cuBLAS. However, at size 2048³, AutoKernel beats torch.compile by 1.55×, showing that TorchInductor’s matmul autotuning is not always optimal. Closing the cuBLAS gap for continued agent iteration remains the primary goal.
In the community deployment, an AutoKernel-optimized kernel took first place on the Vectorsum_v2 B200 leaderboard with a latency of 44.086µs, a second-place entry at 44.249µs, and a third-place entry at 46.553µs. A community user also reported that a single auto kernel prompt – requiring about three minutes of agent interaction – produced a Triton FP4 matrix multiplication kernel that outperformed CUTLASS by 1.63× to 2.15× across multiple shapes on the H100. CUTLASS represents hand-optimized C++ template code designed specifically for NVIDIA tensor cores, which makes this result particularly noteworthy.
Key Takeaways
- Autokernel turns weeks of expert GPU tuning into an autonomous process overnight. By mechanizing the write-benchmark-keep/revert loop already followed by expert kernel engineers, the system runs 300 to 400 experiments per nightly session on a single GPU without any human intervention.
- Accuracy cannot be compromised before any speedup is recorded. Each candidate kernel must pass a five-step harness covering smoke testing, size sweep in 10+ configurations, numerical stability under adversarial inputs, determinism verification, and non-power-of-two-edge cases – eliminating the risk of the agent “adapting” to incorrect outputs.
- Memory-bound kernels get the biggest advantage over both PyTorch eager and torch.compile. On the NVIDIA H100, Autokernel’s Triton kernels achieve 5.29× on RMSNorm, 2.82× on softmax, and 2.21× on cross-entropy – with the benefit coming from fusing the multi-operation Aten decomposition into a single-pass kernel that reduces HBM traffic.
- Amdahl’s law operates where the agent spends his time. Instead of optimizing kernels separately, AutoKernel profiles the entire PyTorch model and allocates effort proportionally to each kernel’s share of the total GPU runtime – ensuring that improvements are made not just at the kernel level, but also at the model level.
AutoKernel limitations and what to watch
The reported figures come with important context. The headline speed-ups — for example, large multiples over PyTorch eager on operations such as RMSNorm, softmax and cross-entropy — were measured on a specific NVIDIA H100 setup against particular baselines, and results will differ on other GPUs, data types and problem shapes. Because the agent runs hundreds of experiments per session, generated kernels are only as trustworthy as the validation harness that screens them, which is why correctness checks across shapes, numerical stability and determinism matter as much as raw timing. An autonomous, LLM-driven search can also produce kernels that are fast on the tested configurations but brittle on inputs outside that range, so independent benchmarking on representative workloads remains essential before production use. As an open-source project, capabilities and supported kernel types are likely to change over time. Full method details are available in the project’s research paper and its open-source repository.