

Creating production-grade voice AI agents is one of the most difficult engineering challenges in applied machine learning today. It’s not just about transcription accuracy. You need a system that can maintain context across a five-minute conversation, invoke external APIs in the middle of a call without awkward interruptions, recover gracefully when the caller corrects themselves, and do all this reliably when the audio degrades due to background noise, heavy accents, or a dropped word. Most existing systems meet one or two of those requirements. New release of xAI grok-voice-think-fast-1.0 Making serious claims of handling them all – and the benchmark numbers back it up.
Available through XAI API, grok-voice-think-fast-1.0 xAI’s new flagship voice model. It is purpose-built for complex, ambiguous, multi-step workflows in customer support, sales and enterprise applications, and is already deployed extensively powering Starlink’s live phone operations.
What makes a voice agent full-duplex?
Before opening the benchmark results, it is worth understanding what type of model grok-voice-think-fast-1.0 Is. It is evaluated (tau) on the τ-voice bench as a Full-duplex voice agent. The system processes incoming speech and generates responses simultaneously, rather than waiting for the speaker to pause before thinking. This is how humans communicate in real conversation. This is why dealing with interruptions is actually a difficult technical problem: the model must decide in real time whether the mid-sentence utterance is a correction, a clarification, or just a filler word, and adjust its behavior accordingly.
The τ-Voice Bench specifically evaluates agents under these realistic conditions: noise, accents, interruptions, and natural inflections, making it a more relevant measure for production deployments than traditional clean-audio ASR benchmarks.
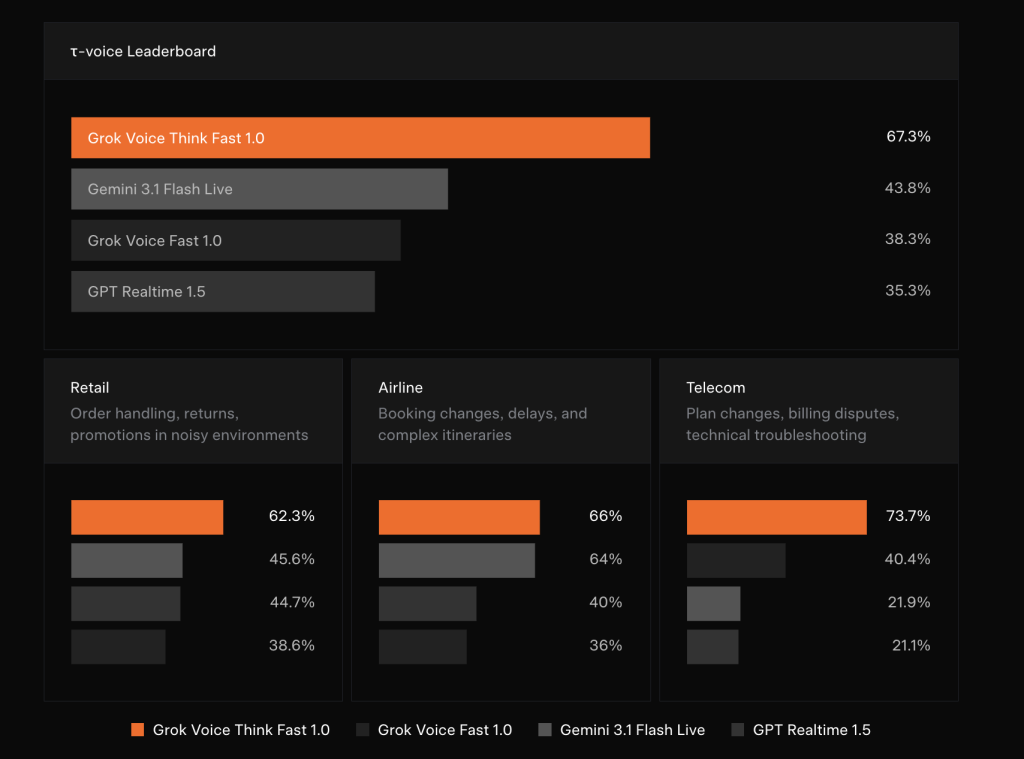
Numbers: An Important Lead
The benchmark results published by XAI show just how big the gaps are. τ-Voice Bench on the overall leaderboard, grok-voice-think-fast-1.0 Score 67.3%Compared to 43.8% For Gemini 3.1 Flash Live, 38.3% for Grok Voice Fast 1.0 (xAI’s own previous model), and 35.3% For GPT Realtime 1.5.
Breaking it down vertically tells an even clearer story:
In retail – Covering order handling, returns and promotions in a noisy environment – grok-voice-think-fast-1.0 Score 62.3%Next is Grok Voice Fast 1.0 45.6%Gemini 3.1 on Flash Live 44.7%And on GPT Realtime 1.5 38.6%.
In airline – Booking changes, delays, and complex itineraries – are the score 66% For Grok Voice Think Fast 1.0, 64% For Grok Voice Fast 1.0, 40% Gemini 3.1 for Flash Live, and 36% For GPT Realtime 1.5.
The most dramatic difference is visible telecommunication: Plan changes, billing disputes and technical troubleshooting – Where grok-voice-think-fast-1.0 is received 73.7%While Grok Voice Fast 1.0 Score 40.4%gemini 3.1 flash live 21.9%and GPT Realtime 1.5 21.1%. A 33 percentage point lead over the next competitor in a single domain is no mean improvement. This is an architectural advantage.
Real-time logic with zero additional latency
One of the most technically important design decisions in this model is how the logic is handled. grok-voice-think-fast-1.0 Reasons in the background, considers challenging questions, and performs workflows in real-time without any impact on response latency. For AI teams, building this is the hard part: reasoning models traditionally increase response times because they generate intermediate ‘thinking’ tokens before providing an answer. Hiding that computation from the conversation latency budget, while still benefiting from it, requires careful architectural work.
The practical benefit is accuracy without slack. The XAI team demonstrates this with a representative edge case: When asked “Which months of the year are spelled with the letter X?” grok-voice-think-fast-1.0 Correctly answers that there is no letter X in any month. Competing models, on the other hand, confidently and incorrectly answered “February.” This class of error, where a model seems reliable but gives the wrong answer with high confidence, is particularly harmful in voice interfaces because users have no text output to cross-check.
Accurate data entry and read-back
A core workflow capability of grok-voice-think-fast-1.0 Structured data capture and read-back. The model can seamlessly collect email addresses, physical street addresses, phone numbers, full names, account numbers and other structured data, even when the information is spoken quickly or with a strong accent. It handles speech errors gracefully and accepts natural corrections like a human would, then reads confirmed data back to the user.
xAI shows this with a concrete example. A caller says: “Yeah, it’s 1410, uh wait, 1450 Page Mill Street. No sorry actually, that’s Page Mill Road.” The model processes spoken corrections in real time, invoking search_address device with correct parameters "1450 Page Mill Rd"And reads the normalized address back to the user for confirmation. For data teams that have spent time building post-call cleanup pipelines to extract structured fields from dirty transcripts, this basic capture-and-read-back capability represents a meaningful reduction in downstream processing complexity.
The model has been tested in the toughest real-world conditions: telephony audio, background noise, heavy accents and frequent interruptions. It natively supports 25+ languages, making it ideal for global deployment for use cases including customer support, phone sales, appointment booking, and restaurant reservations.
Starlink deployment: mass production
The most compelling verification of grok-voice-think-fast-1.0 This is not just a benchmark but this is a live deployment. Grok Voice +1 (888) GO powers full phone sales and customer support operations for Starlink. The numbers revealed by xAI from this deployment are operationally significant: a 20% sales conversion rate (Meaning one in five callers making a sales inquiry purchases Starlink service while on the phone with Grok), a 70% autonomous resolution rate For customer support inquiries that don’t involve any people, and are handled by a single agent 28 specific tools Spanning hundreds of support and sales workflows.
key takeaways
- grok-voice-think-fast-1.0 leads the τ-voice bench with a score of 67.3%Gemini 3.1 outperforms Flash Live (43.8%), Grok Voice Fast 1.0 (38.3%), and GPT Realtime 1.5 (35.3%).
- The model executes background logic with zero additional latencyAllowing it to think through complex, multi-step workflows in real time without slowing down conversational responses.
- Accurate data entry and read-back is a basic capabilityEnables the model to capture and validate structured data such as names, addresses, phone numbers, and account numbers, whether spoken quickly, with accents, or with mid-sentence corrections.
- Model supports 25+ languages and high-volume tool callingThat makes it deployable across global enterprise use cases, including customer support, phone sales, appointment booking, and restaurant reservations.
- Starlink live deployment proves readiness for mass production: A single Grok voice agent works across 28 tools and hundreds of workflows, achieves a 20% sales conversion rate and resolves 70% of customer support inquiries autonomously without anyone in the loop.
check it out documentation And official release. Also, feel free to follow us Twitter And don’t forget to join us 130k+ ML subreddit and subscribe our newsletter. wait! Are you on Telegram? Now you can also connect with us on Telegram.
Do you need to partner with us to promote your GitHub repo or Hugging Face page or product release or webinar, etc? join us

Michael Sutter is a data science professional and holds a Master of Science in Data Science from the University of Padova. With a solid foundation in statistical analysis, machine learning, and data engineering, Michael excels in transforming complex datasets into actionable insights.