

# Introduction
A model that says it is 90% confident should be correct in 90% of the cases. When that relationship breaks, you get a miscalibration crisis. The model’s scores stop telling you anything useful about reliability.
For large language model (LLM), miscalibration is widespread. A 2024 NAACL survey Found that confidence scores differ from actual correctness rates in factual QA, code generation, and reasoning tasks.
one more Study The average calibration score across all tested models on biomedical models was found to range from only 23.9% to 46.6%. The difference is consistent.
standard solution in classical machine learning Post-hoc recalculation is: fit a simple function on a held-out validation set to map the raw confidence scores to better-calibrated probabilities.
Three Methods dominate: temperature measurement, plate scalingAnd isotonic regression. All three were designed differential classifierAnd care is required to apply them in LLM.
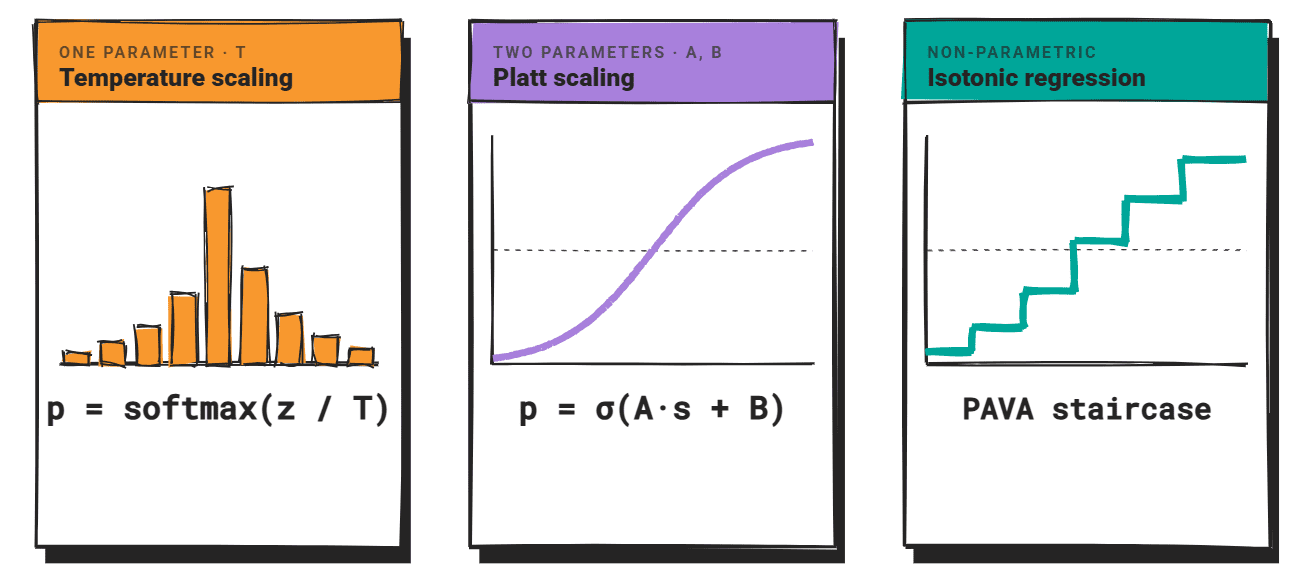
# measuring calibration
The key metric is expected calibration error (ECE). It groups the predictions into confidence bins, calculates the difference between the average confidence in each bin and the observed accuracy, and calculates the average of the bins weighted by size. ECE=0 is full calibration.
A reliability diagram presents confidence against precision. A fully calibrated model sits on the diagonal. An overconfident model sits below this: the curve shows high confidence, but accuracy does not hold up.
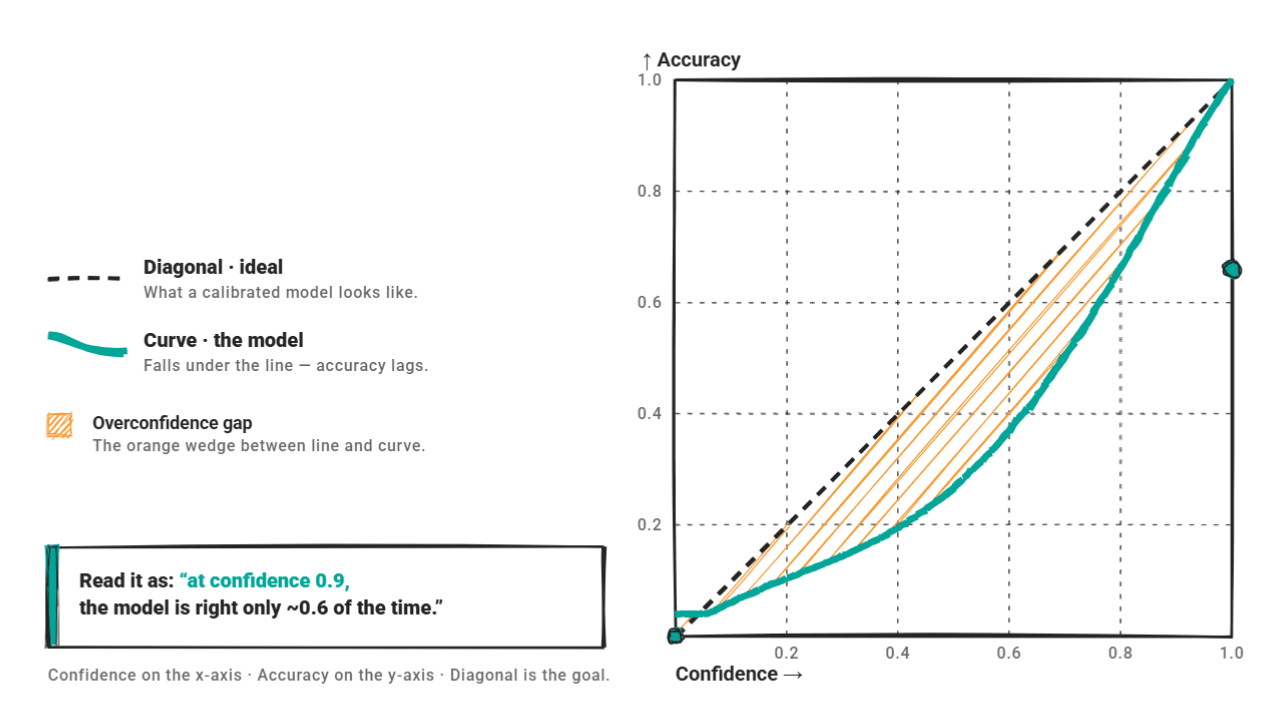
A 2025 assessment As a text classifier, GPT-4O-Mini found that 66.7% of its errors occurred at greater than 80% confidence – the canonical overconfidence pattern.
ECE alone is increasingly considered inadequate. A research paper ECE recommends linking it with barrier scoreOverconfidence rate, and reliability diagram together. A single number obscures meaningful variation in where and how a model misbehaves.
# Why do LLM standards complicate setup?
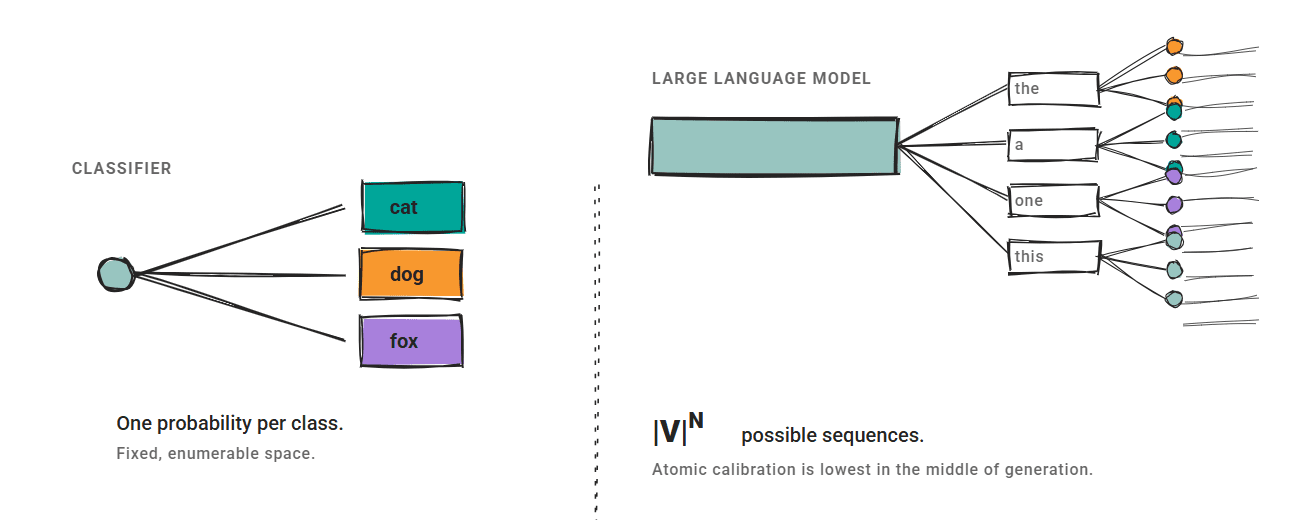
The three methods we cover assume a fixed output space. A classifier produces a Possibility per class, and calibration maps them to better estimates.
llm Don’t act like this.
Four complications matter here.
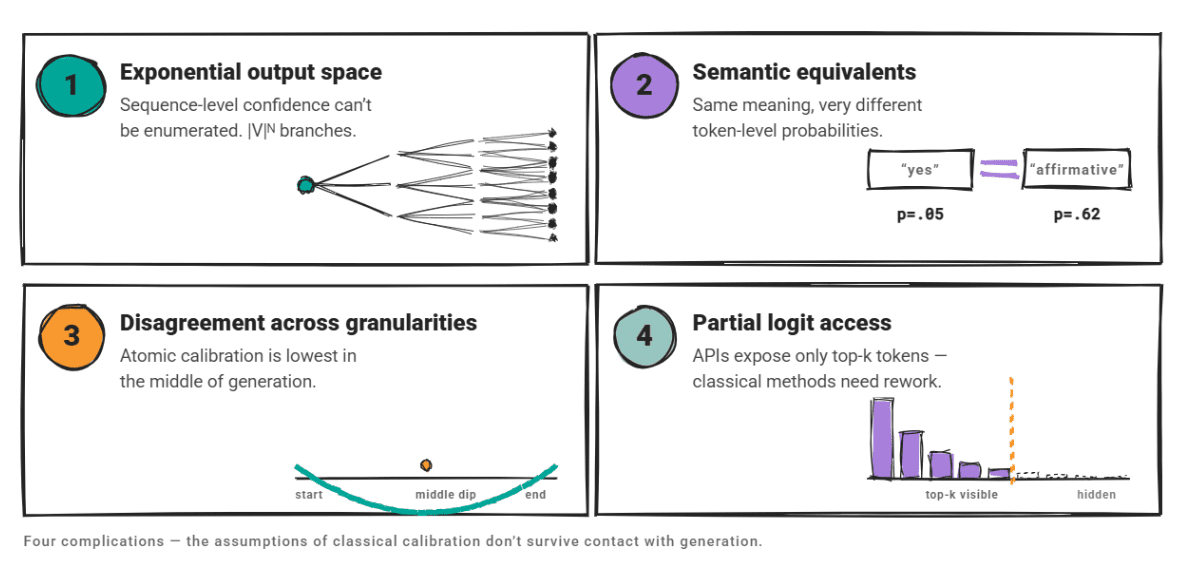
The output space is exponentially larger: sequence-level confidence cannot be calculated. Semantically equivalent outputs may have very different token-level probabilities. Disagree on confidence granularity; A research paper Atomic calibration revealed that generative models exhibit their lowest average confidence in the middle of generation, not at the beginning or end.
And many LLMs expose top-K token prospects only through their APITherefore classical calibration approaches that rely on full logit access require modification.
# apply temperature scaling
Temperature scaling divides the logit vector by the scalar t before applying softmax. When t > 1, the distribution flattens and confidence falls. When t < 1, the distribution is steeper and confidence increases.
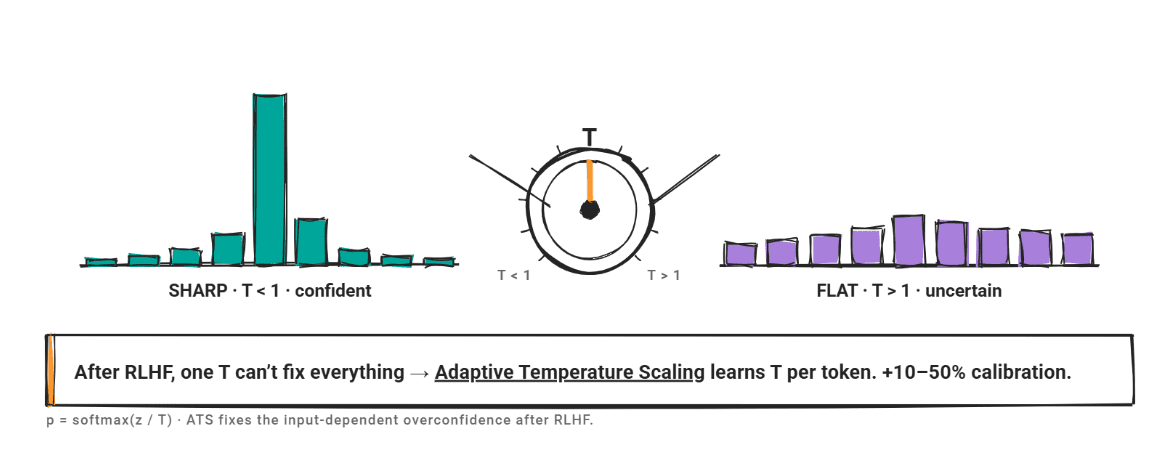
t is fit on a held-out validation set by minimizing the negative log-likelihood. The method adds one parameter, preserves the prediction ranking, and is inexpensive to compute.
original formulation Targeted DenseNet Image Classifier. For LLM, the temperature controls the probability distribution over the vocabulary at each decoding step, so the same logic applies.
the problem is Reinforcement learning from human feedback (RLHF). Post-RLHF models develop input-dependent overconfidence: the degree of miscalibration varies across inputs, and a single T cannot account for that variation.
Average ECE scores above 0.377 have been documented for models such as GPT-3 in verbal confidence tasks, and a 2025 survey Confirms that RLHF-tuned models consistently overestimate confidence across the board.
adaptive temperature scaling (ATS) addresses this directly. ATS predicts per-token temperatures from token-level latent features fit to a supervised fine-tuning dataset, rather than using a single fixed T. Researchers confirmed that ATS improved calibration by 10–50% without harming task performance. For any RLHF-tuned model, the ATS is a stronger baseline than standard temperature scaling.
Standard temperature scaling still works well for the base model before RLHF. When miscalibration is roughly uniform across all inputs, a single T is often sufficient to correct systematic over- or underconfidence.
The problem is specific to post-RLHF models, where input-dependent overconfidence means that a T cannot correct all inputs.
# apply plot scaling
Platt scaling fits a logistic function on the uncalibrated scores: P = σ(A·S + B), where A and B are learned from a held-out validation set with binary purity labels.
The sigmoid shape gives a parametric mapping with two free parameters.
Platt scaling was originally developed for SVMs, but generalizes to any system that generates scalar confidence scores.
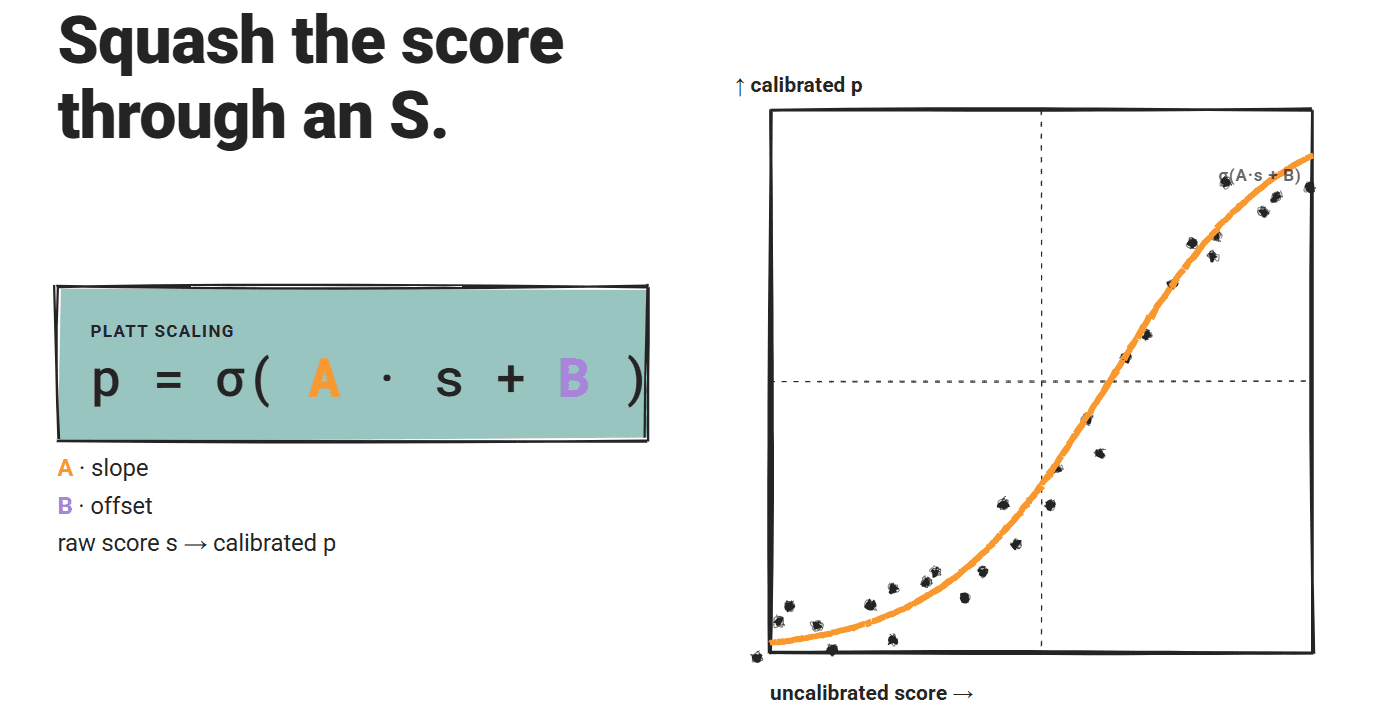
Two-parameter fit is also data-efficient compared to isotonic regression: it can produce usable estimates from a small calibration set, which may matter in deployment contexts where label purity data is limited.
In LLM contexts, Plat scaling works on sequence-level or token-level confidence scores.
A paper On LLM-generated code confidence, Platt scaling was found to produce better-calibrated outputs than uncalibrated scores. Another study launched on LLM for text-to-SQL multivariate plot scaling (MPS), extends single-variable plot scaling to combine sub-segment frequency scores across multiple generated samples – consistently outperforming single-score baselines.
Two boundaries are documented. First, global sequence-level plot scaling is too harsh for tasks where accuracy depends on local editing decisions: a single sigmoid mapping cannot capture sample-dependent miscalibration patterns.
Furthermore, plot scaling can degrade reasonable scoring performance for robust models.
# Applying Isotonic Regression
Isotonic regression takes a non-parametric route.
It learns a piecewise-constant, monotonically non-decreasing mapping from uncalibrated scores to calibrated probabilities using . Pool Adjacency Violator Algorithm (Pava). There is no approximate shape for the calibration function, making it more flexible than Platt scaling when the confidence–accuracy relation is not sigmoid-shaped.
The piecewise-constant output adapts to any monotone shape: linear, stepped, or concave. This adaptability is the main reason why isotonic regression outperforms Platt scaling in empirical comparisons.
The cost outweighs the risk on small calibration sets. The mapping generalizes well only when there is enough data to constrain it.
Empirically, isotonic regression performs better than Platt scaling.
a harsh Compare Across multiple datasets and architectures, isotonic regression beat Plat scaling on ECE and Brier scores with statistical significance, using paired t-tests with Bonferroni correction at α = 0.003.
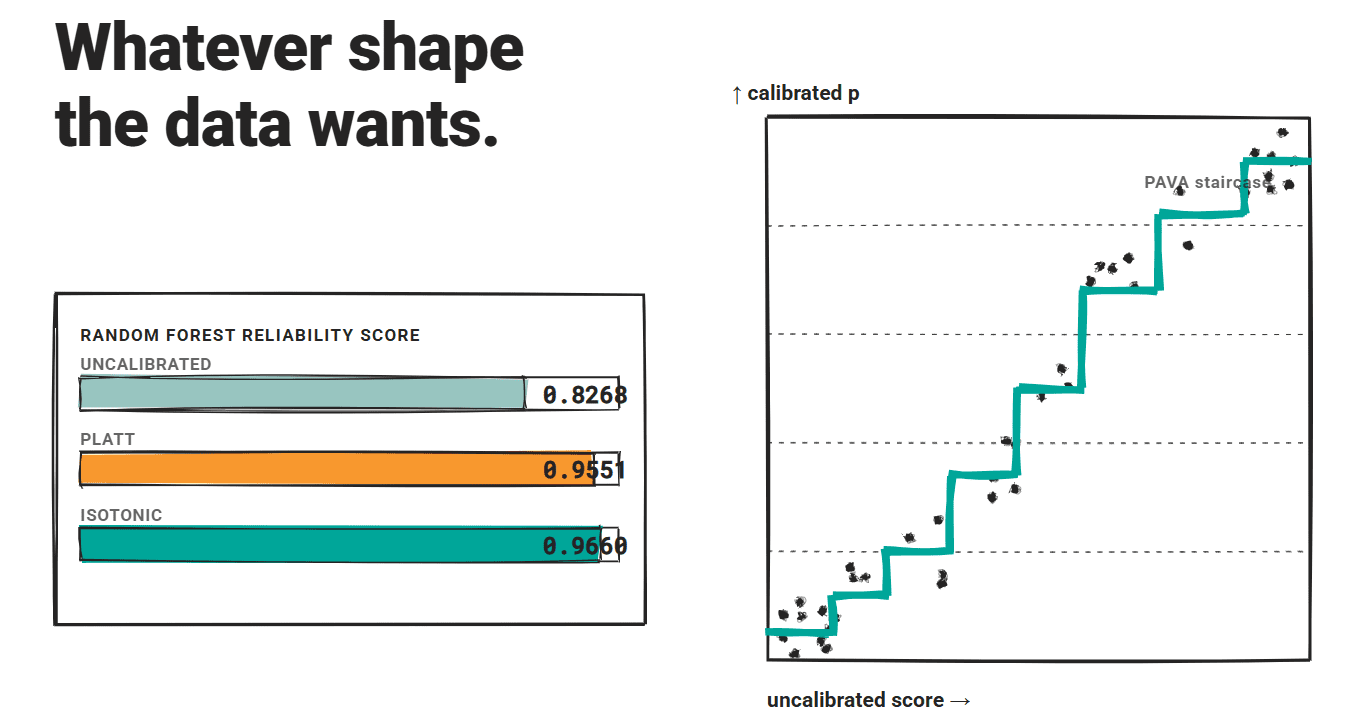
In that study, the random forest baseline improved from a reliability score of 0.8268 uncalibrated to 0.9551 with Platt scaling, to 0.9660 with isotonic regression. Both methods could degrade reasonable scoring performance for robust models, but the isotonic edge remained consistent.
For LLM multiclass settings, it has been shown that standard isotonic regression can be further improved with normalization-aware extensions, consistently outperforming both OVR isotonic regression and standard parametric methods on NLL and ECE.
Data requirement is the binding constraint. The benefit of isotonic regression is real, but it does not transfer to low-data deployment scenarios.
# What does literature leave open?
Three interval It is advisable to mark before implementing any of these methods.
RLHF The interaction has been studied only for temperature scaling. How plate scaling And performing isotonic regression on post-rLHF models has not been systematically tested. ATS Exists because standard temperature scaling needs an explicit solution for this case. Whether the other two methods require similar extensions is an open question.
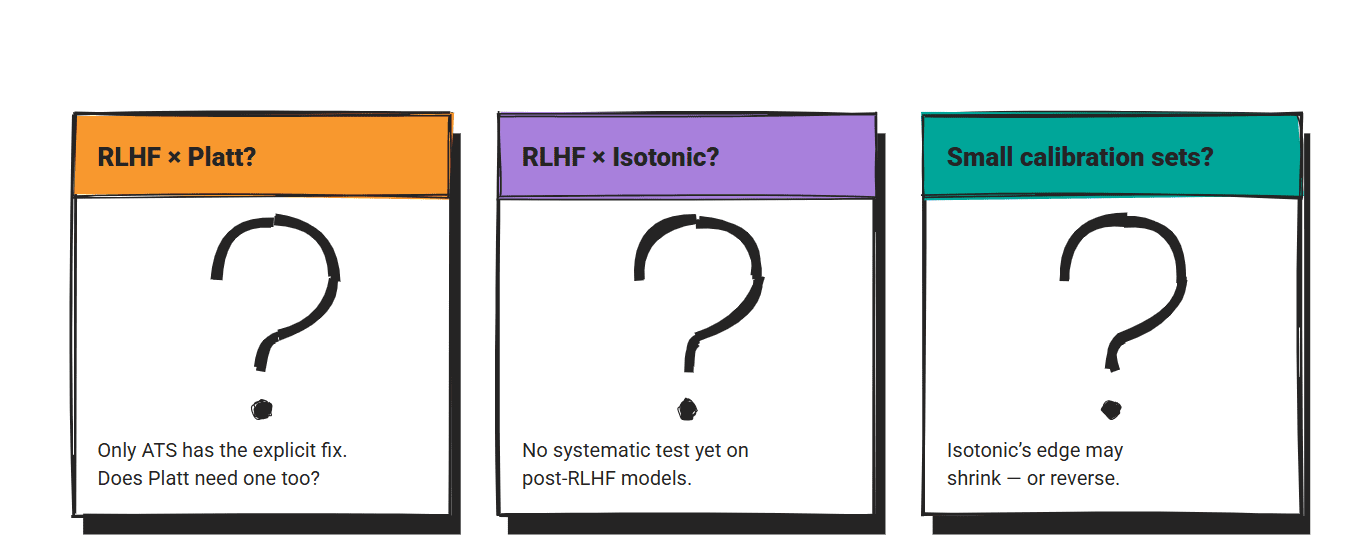
the straightest Compare All three methods come from the general machine learning calibration literature. LLM-specific benchmarks that test all three head-to-head are rare. icse 2025 code calibration paper One of the few, and its scope is limited to code generation.
The calibration set size is a real deployment bottleneck. Isotonic regression results from papers consider datasets large enough to constrain mapping. In production with limited labeled instances, the distinction between isotonic regression and Platt scaling may be closed or reversed.
# conclusion
temperature scaling This is the perfect starting point for most teams. For base models without RLHF, a T is often sufficient.
For RLHF-Tuned models, switch to ATS: Per-token temperature handles input-dependent overconfidence that a global scalar misses.
plot scaling This is a practical choice when the calibration set is small or when the calibration needs to be slotted into a larger pipeline. It is data-efficient and easy to implement. The limitation is scope: it cannot capture miscalibration that varies across samples, and it degrades the performance of robust models.
isotonic regression Has the strongest empirical track record of the three. Use it when the calibration set is large enough to constrain the mapping without overfitting, and combine it with normalization-aware extensions in multiclass settings.
The decision that comes before all this is what happens.Self-confidence“Means up to the task. Token probability, sequence probability, verbal confidence, and consistency across samples can give different values for the same output. A calibration method applied to the wrong signal does not improve reliability. Getting that definition right is the prerequisite for any of the methods above to work.
Nate Rosidi Is a data scientist and is into product strategy. He is also an adjunct professor teaching analytics, and is the founder of StratScratch, a platform that helps data scientists prepare for their interviews with real interview questions from top companies. Nate writes on the latest trends in the career market, gives interview advice, shares data science projects, and covers everything SQL.