


Image by author
, Introduction
It seems like almost every week, there is a new model claiming to be state-of-the-art, outperforming existing AI models on all benchmarks.
I get free access to the latest AI models within weeks of release at my full-time job. I generally don’t pay much attention to promotions and use whatever model is automatically selected by the system.
However, I know developers and friends who want to build software with AI that can be sent to production. Since these initiatives are self-funded, their challenge lies in finding the best model to work. They want to balance cost with reliability.
Because of this, after the release of GPT-5.2, I decided to run a practical test to understand whether this model was worth the hype, and whether it was really better than the competition.
Specifically, I chose to test each provider’s flagship models: cloud opus 4.5 (Anthropic’s most efficient model), GPT-5.2 Pro (OpenAI’s latest extended reasoning model), and DeepSeek V3.2 (One of the latest open-source options).
To test these models, I chose to use them to create a playable Tetris game with the same prompts.
These were the metrics I used to evaluate the success of each model:
| criteria | Description |
|---|---|
| first attempt successful | With only a hint, did the model deliver working code? Multiple debugging iterations lead to higher costs over time, which is why this metric was chosen. |
| feature completion | Were all the features mentioned in the prompt created by the model, or was anything missing? |
| ability to play | Technical implementation aside, was the game actually easy to play? Or were there issues that created friction in the user experience? |
| cost effectiveness | How much did it cost to get production-ready code? |
, prompt
Here is the signal I entered into each AI model:
Create a fully functional Tetris game as a single HTML file that I can open directly in my browser.
Requirements:
Game Mechanics:
– All 7 Tetris piece types
– Smooth piece rotation with wall kick collision detection
– Pieces should fall automatically, speed up gradually as user’s score increases
– Line clearing with visual animation
– “Next part” preview box
– The game is over when the pieces reach the topControl:
– Arrow keys: left/right to move, down to skip, up to rotate
– Touch controls for mobile: swipe left/right to move, swipe down to skip, tap to rotate
– Spacebar to pause/repause
– Enter key to restart after game endsVisual Design:
– gradient color for each piece type
– Smooth animations as pieces move and lines become clear
– Clean UI with rounded corners
– Update scores in real time
– level indicator
– Game on screen with final score and restart buttonGameplay Experience and Polish:
– Smooth 60fps gameplay
– Particle effect when lines are cleared (optional but effective)
– Increase score based on number of lines cleared simultaneously
– grid background
– responsive designMake it visually sophisticated and feel satisfying to play. Code should be clean and organized.
, Result
, 1. Cloud Opus 4.5
The Opus 4.5 model turned out to be exactly what I asked for.
The UI was clean and instructions were clearly displayed on the screen. All the controls were responsive and the game was fun to play.
The gameplay was so intuitive that I actually kept playing for quite some time and got distracted from testing other models.
Also, Opus 4.5 took less than 2 minutes to get me a working game, which impressed me on the first try.
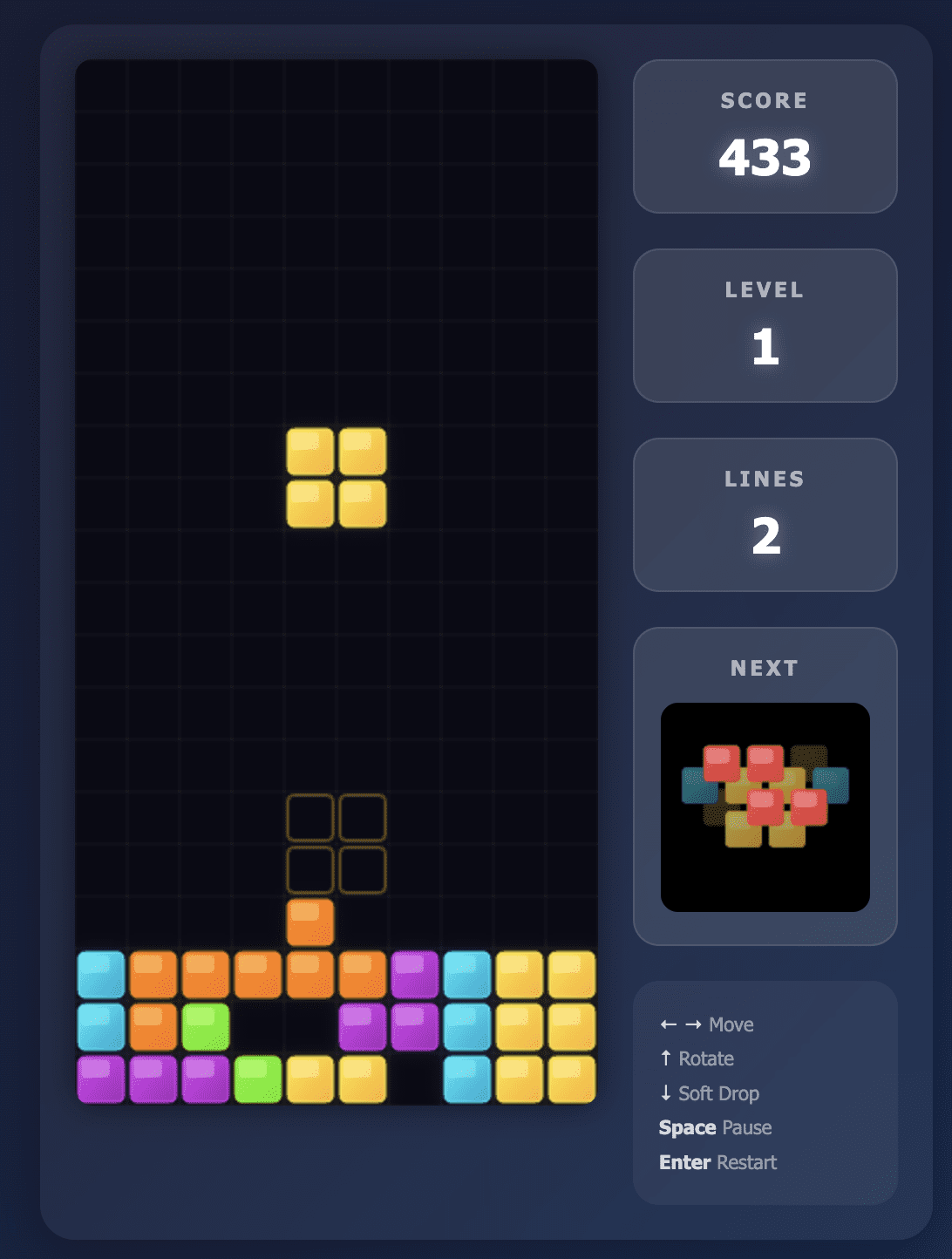
Tetris game created by Opus 4.5
, 2. GPT-5.2 Pro
GPT-5.2 Pro is OpenAI’s latest model with extended logic. For reference, GPT-5.2 has three levels: Instant, Thinking, and Pro. At the time of writing this article, GPT-5.2 Pro is their most intelligent model, offering extended thinking and reasoning capabilities.
It is also 4 times more expensive than Opus 4.5.
There was a lot of hype surrounding this model, which is why I went into it with high expectations.
Unfortunately, I was underwhelmed by the games produced by this model.
On the first attempt, GPT-5.2 Pro produced a Tetris game with a layout bug. The bottom rows of the game were outside the viewport, and I couldn’t see where the pieces were landing.
This rendered the game unplayable, as shown in the screenshot below:
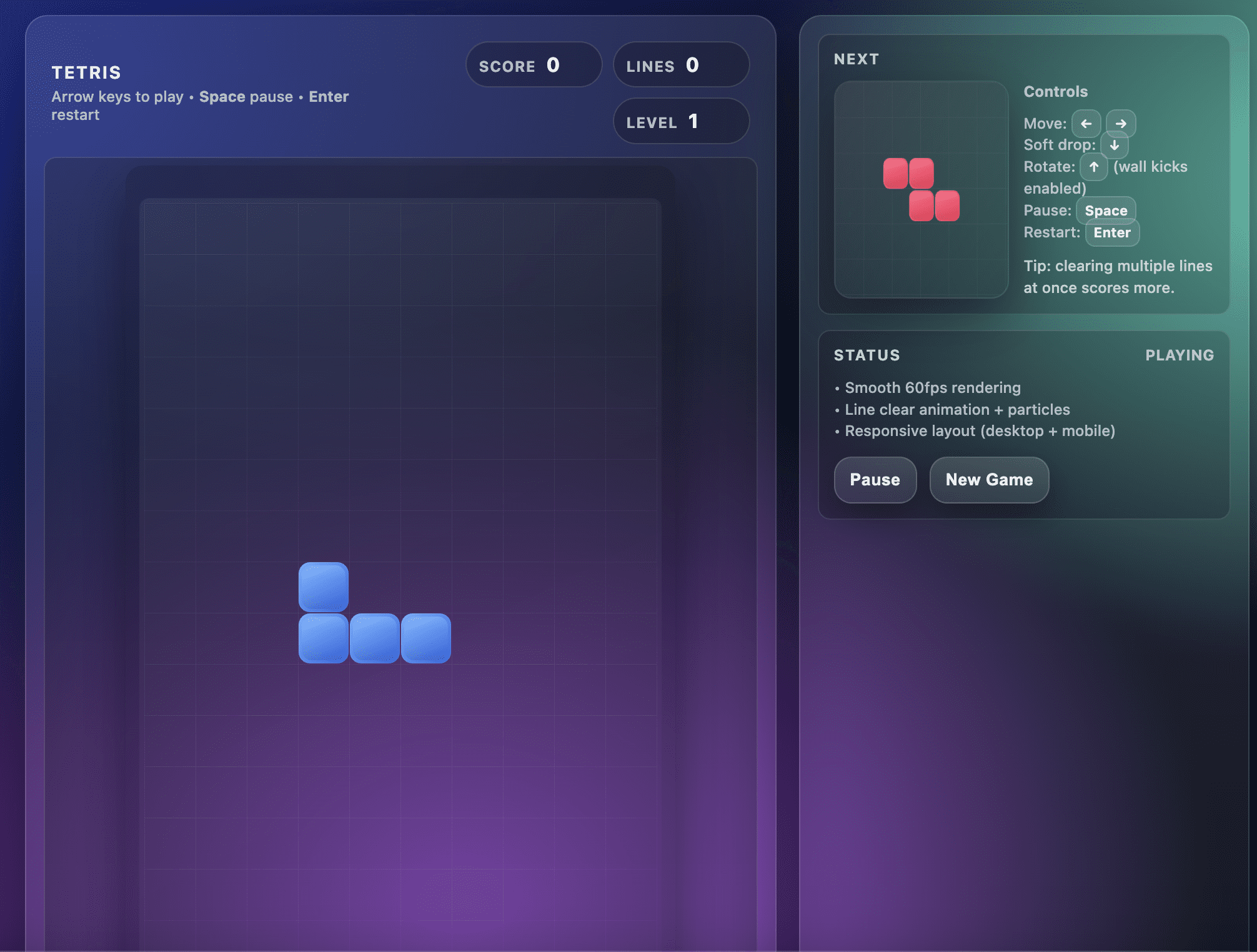
Tetris game created by GPT-5.2
I was particularly surprised by this bug because it took the model about 6 minutes to generate this code.
I decided to try again with this follow-up hint to fix the viewport issue:
The game works, but there is a bug. The bottom lines of the Tetris board are cut off from the bottom of the screen. I can’t see the pieces when they land on the ground and the canvas stretches beyond the visible viewport.
Please fix this:
1. Making sure the entire game board fits in the viewport
2. Adding proper centering so that the entire board is visibleThe game must fit the screen and all lines must be visible.
Following the follow-up prompt, the GPT-5.2 Pro model produced a functional game, as seen in the screenshot below:

Second attempt at Tetris by GPT-5.2
However, game play was not as smooth as games produced by the Opus 4.5 model.
When I pressed the “down” arrow to drop a piece, the next piece would sometimes fall immediately at high speed, not giving me enough time to think about how to place it.
The game was only playable if I let each piece fall on its own, which wasn’t the best experience.
(Note: I also tried the GPT-5.2 standard model, which produced equally buggy code on the first try.)
, 3. DeepSeek V3.2
DeepSeek’s first attempt at creating this game had two issues:
- The pieces started disappearing as soon as they hit the bottom of the screen.
- The “down” arrow, used to drop pieces faster, scrolls the entire webpage instead of moving the game pieces.
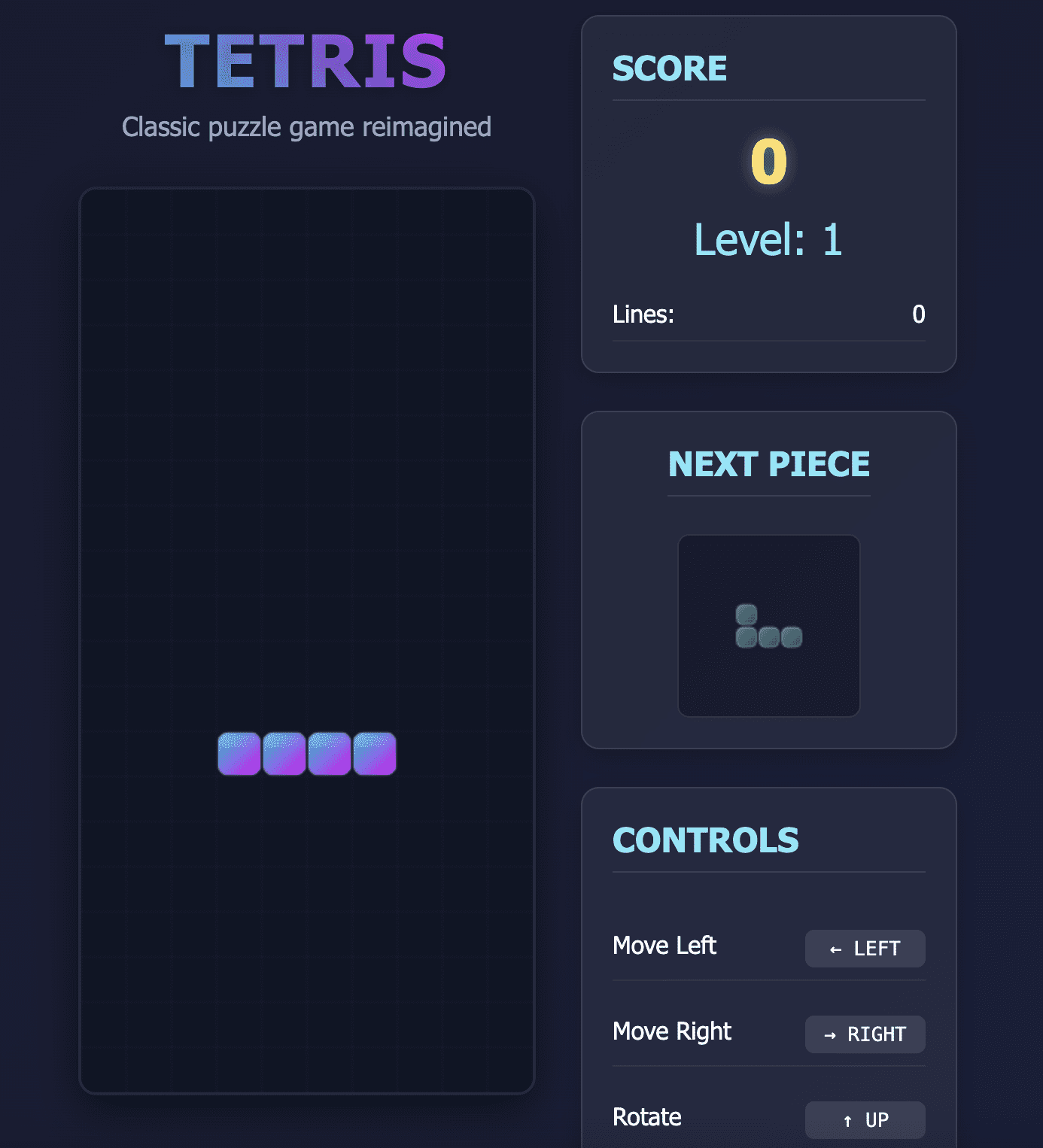
Tetris game created by DeepSeek V3.2
I re-prompted the model to fix this problem, and the gameplay controls started working correctly.
However, some pieces disappeared before they could land. This left the game completely unplayable even after the second iteration.
I’m sure this problem can be fixed with 2-3 more signals, and given the low price of DeepSeek, you can afford 10+ debugging rounds and still spend less than a successful Opus 4.5 attempt.
, Summary: GPT-5.2 vs Opus 4.5 vs DeepSeek 3.2
, cost breakdown
Here’s a cost comparison between the three models:
| Sample | Input (per 1M token) | Output(per 1M token) |
|---|---|---|
| DeepSeek V3.2 | $0.27 | $1.10 |
| GPT-5.2 | $1.75 | $14.00 |
| cloud opus 4.5 | $5.00 | $25.00 |
| GPT-5.2 Pro | $21.00 | $84.00 |
DeepSeek v3.2 is the cheapest option, and you can also download weights of the model for free and run it on your infrastructure.
GPT-5.2 is about 7 times more expensive than DeepSeek V3.2, followed by Opus 4.5 and GPT-5.2 Pro.
For this specific task (creating a Tetris game), we consumed approximately 1,000 input tokens and 3,500 output tokens.
For each additional iteration, we will estimate an additional 1,500 tokens per additional round. Here’s the total cost per model:
| Sample | total cost | Result |
|---|---|---|
| DeepSeek V3.2 | ~$0.005 | Game is not playable |
| GPT-5.2 | ~$0.07 | Playable, but bad user experience |
| cloud opus 4.5 | ~$0.09 | Playable and good user experience |
| GPT-5.2 Pro | ~$0.41 | Playable, but bad user experience |
, takeaway
Based on my experience creating this game, I’ll stick to the Opus 4.5 model for everyday coding tasks,
Although GPT-5.2 is cheaper than Opus 4.5, I personally wouldn’t use it to code, as it would likely cost the same amount due to the iterations required to achieve the same results.
However, the DeepSeek V3.2 is much more affordable than the other models on this list.
If you’re a developer on a budget and have extra time on debugging, you’ll still save money even if it takes more than 10 tries to get working code.
I was surprised by GPT 5.2 Pro’s inability to produce a working game on the first try, as it took about 6 minutes of thinking before coming up with flawless code. After all, this is OpenAI’s core model, and Tetris should be a relatively simple task.
However, GPT-5.2 Pro’s strengths lie in mathematics and scientific research, and it is specifically designed for problems that do not rely on pattern recognition from training data. Perhaps this model is over-engineered for simple day-to-day coding tasks, and should instead be used when building something that is complex and requires innovative architecture.
Practical conclusions from this experiment:
- Opus 4.5 performs best in everyday coding tasks.
- DeepSeek v3.2 is a budget option that gives reasonable output, although it does require some debugging effort to reach your desired results.
- GPT-5.2 (Standard) did not perform as well as Opus 4.5, while GPT-5.2 (Pro) is probably better suited for complex logic than quick coding tasks like this.
Feel free to repeat this test with the hints I shared above, and happy coding!
 
 
Natasha Selvaraj He is a self-taught data scientist and has a passion for writing. Natasha writes on everything related to data science, she is a true expert on all data topics. you can join him Linkedin or check it out Youtube channel,