

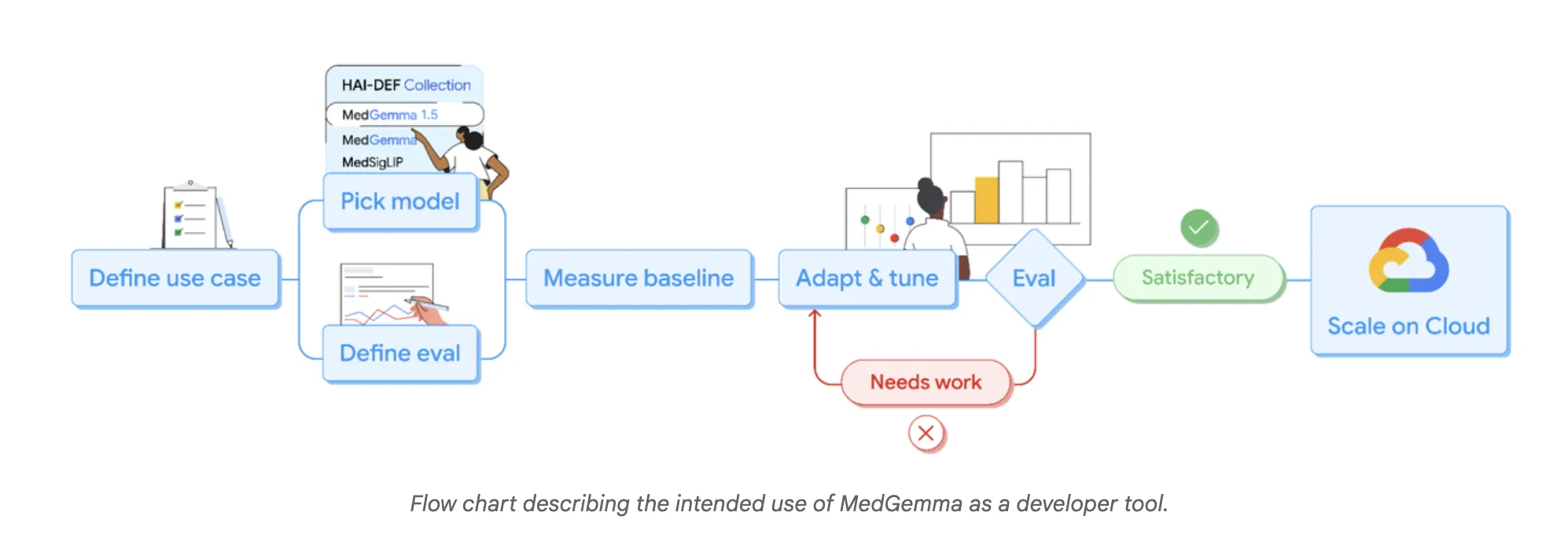
Google Research has expanded this Health AI Developer Foundation Program (HAI-DEF) with the release of Medjemma-1.5. This model is released as an open starting point for developers who want to build medical imaging, text, and speech systems and then adapt them to local workflows and regulations.
MedGemma 1.5, Small Multimodal Models for Real Clinical Data
MedGemma is a family of medical generative models built on Gemma. The new release, MedGemma-1.5-4b, targets developers who need a compact model that can still handle real clinical data. The previous MedGemma-1-27B model is available for more demanding text heavy use cases.
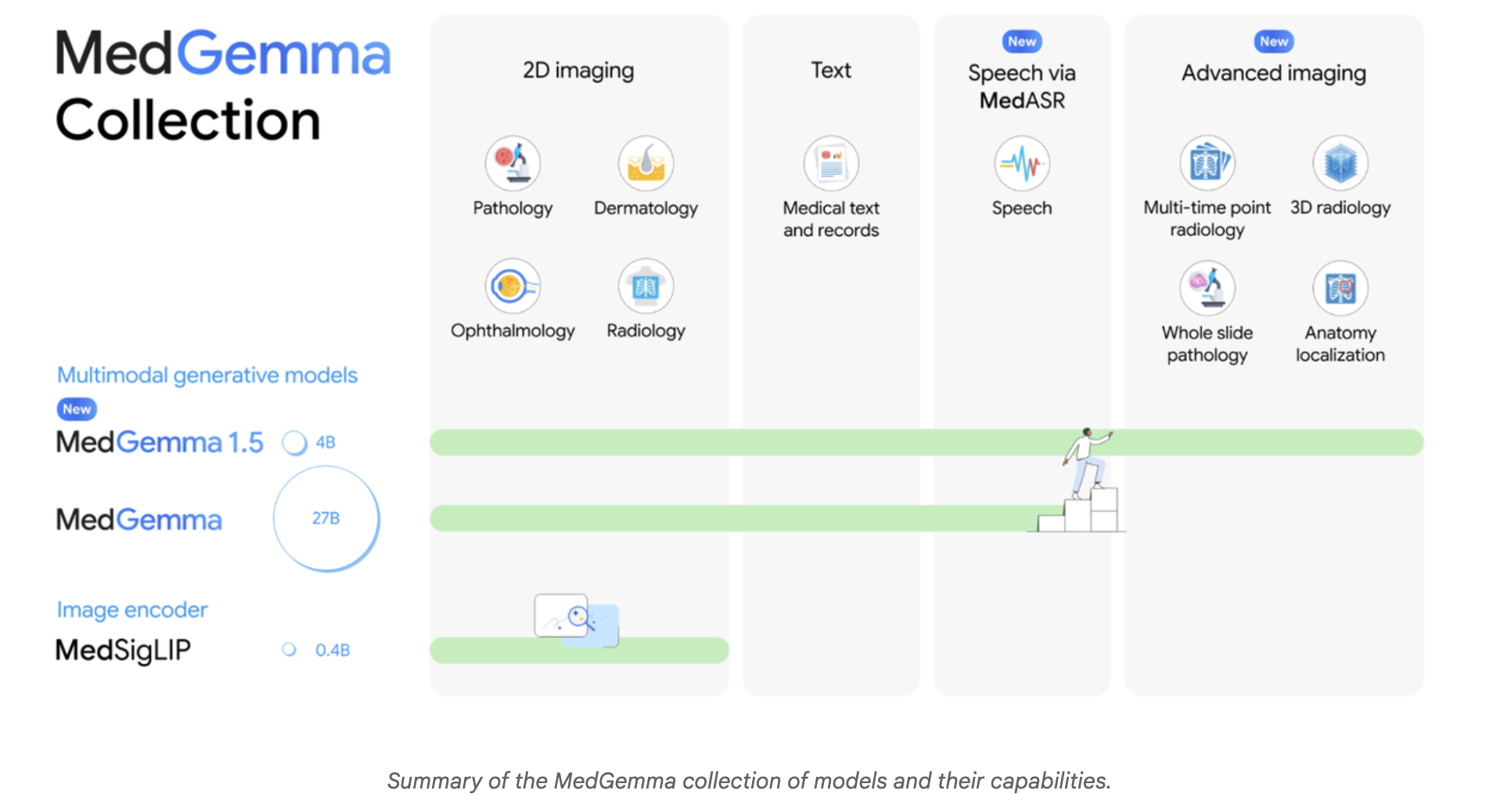
MedGemma-1.5-4B is multimodal. It accepts text, two dimensional images, high dimensional volumes and whole slide pathology images. This model is part of the Health AI Developer Foundation program, so it is intended as a basis for fine tuning, not as a ready-made diagnostic device.
Support for high dimensional CT, MRI and pathology
A major change in MedGemma-1.5 is support for higher dimensional imaging. The model can process three-dimensional CT and MRI volumes as sets of slices with natural language prompts. It can also process large histopathology slides by working on patches extracted from the slides.
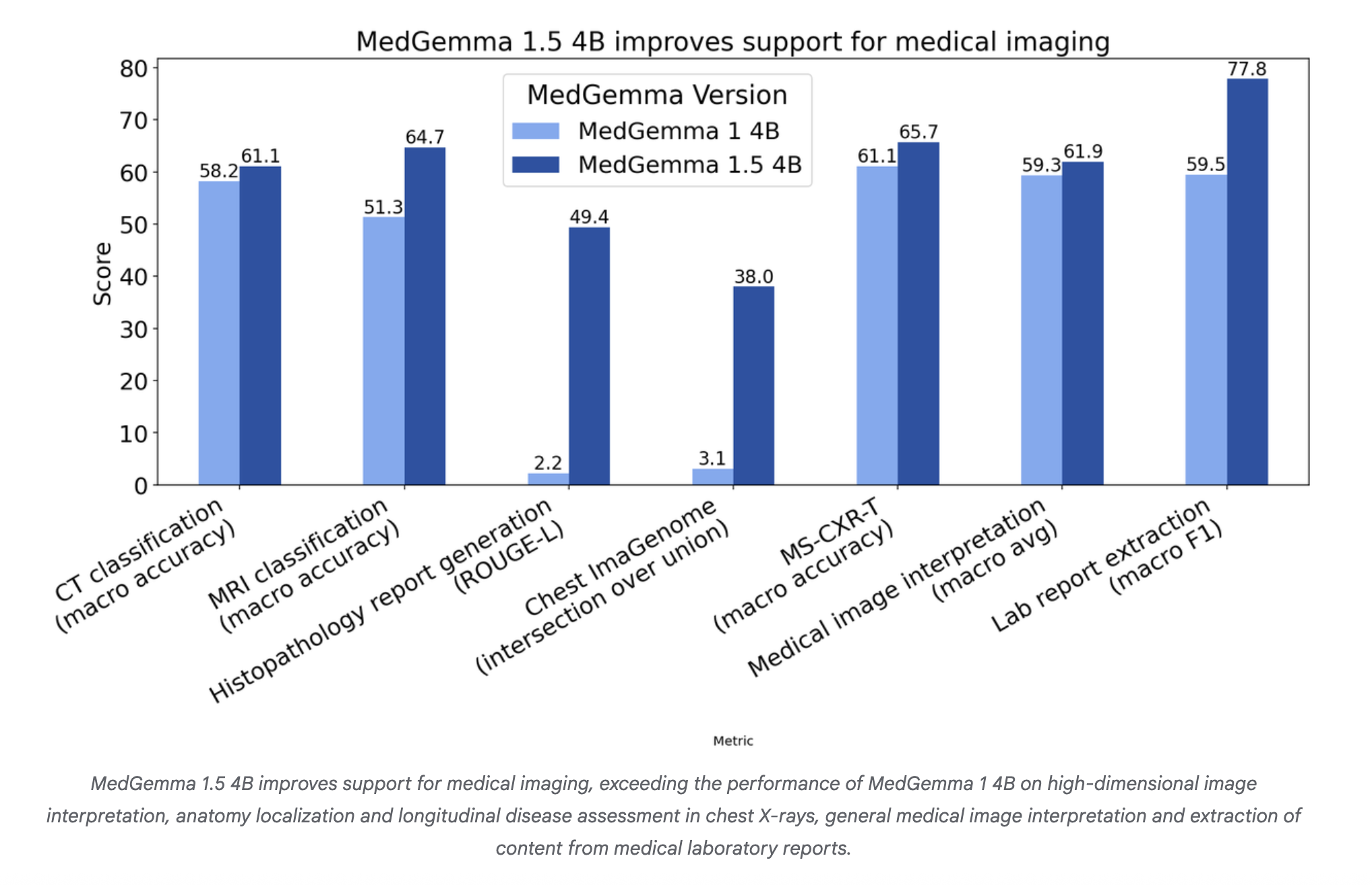
On internal benchmarks, MedGemma-1.5 improves pathological CT findings to 58% to 61% accuracy and MRI pathological findings to 51% to 65% accuracy when averaged over findings. For histopathology, the ROUGE L score increases from 0.02 to 0.49 on single slide cases. This function matches the 0.498 rouge L score of the typical polypath model.

Imaging and Report Extraction Benchmarks
MedGemma-1.5 also improves several benchmarks that are closer to production workflows.
On the Chest Imagenom benchmark for anatomical localization in chest X-rays, this increases intersection at fusion from 3% to 38%. On the MS-CXR-T benchmark for longitudinal chest X-ray comparison, macro-accuracy increases from 61% to 66%.
In internal single image benchmarks covering chest radiography, dermatology, histopathology, and ophthalmology, the average accuracy ranges from 59% to 62%. These are simple single image functions, useful as sanity checks during domain optimization.
MedGemma-1.5 also targets document extraction. On medical laboratory reports, the model improves macro F1 from 60% to 78% when removing laboratory type, value, and units. For developers this means less custom rule based parsing for semi-structured PDF or text reports.
Applications deployed on Google Cloud can now work directly with DICOM, the standard file format used in radiology. This removes the need for custom preprocessors for many hospital systems.
Medical text reasoning with MedQA and EHRQA
MedGemma-1.5 is not just an imaging model. It also improves baseline performance on medical text tasks.
On MedQA, a multiple choice benchmark for medical question answering, the 4B model improves accuracy from 64% to 69% compared to the previous MedGemma-1. On EHRQA, a text-based electronic health record question answering benchmark, accuracy increases from 68% to 90%.
These numbers matter if you plan to use MedGemma-1.5 as the backbone for tools such as chart summarization, guideline grounding or augmented generation retrieval on clinical notes. The 4B size keeps tuning and service costs down to a practical level.
MedASR, a domain tuned speech recognition model
A large amount of directed speech occurs in clinical workflow. MedASR is a new medical automatic speech recognition model released together with MedGemma-1.5.
MedASR uses a conformer based architecture that is pre-trained and fine-tuned for clinical audio. It targets tasks such as chest X-ray dictation, radiology reports and general medical notes. The model is available through the same Health AI developer foundation channel on Vertex AI and Hugging Face.
In evaluation against Whisper-Large-v3, a common ASR model, MedASR reduced the word error rate for chest X-ray dictation from 12.5% to 5.2%. This corresponds to 58% fewer transcription errors. On a comprehensive internal medicine dictation benchmark, MedASR reaches a 5.2% word error rate while Whisper-Large-V3 has 28.2%, which corresponds to 82% fewer errors.
key takeaways
- MedGemma-1.5-4B is a compact multimodal medical model that handles text, 2D images, 3D CT and MRI volumes, and whole slide pathology, released as part of the Health AI Developer Foundation program for optimization for local use cases.
- On imaging benchmarks, MedGemma-1.5 improves CT disease findings from 58% to 61%, MRI disease findings from 51% to 65%, and histopathology Rouge-L from 0.02 to 0.49, matching the performance of the PolyPath model.
- For downstream clinical-style tasks, MedGemma-1.5 increases chest imagenome intersection at union from 3% to 38%, MS-CXR-T macro accuracy from 61%T to 66%, and lab report extraction macro F1 from 60% to 78%, while keeping the model size at 4B parameters.
- MedGemma-1.5 also strengthens text logic, increasing MedQA accuracy from 64% to 69% and EHRQA accuracy from 68% to 90%, making it suitable as the backbone for chart summaries and EHR question answering systems.
- MedASR, a conformer-based medical ASR model in the same program, reduced the word error rate from 12.5% to 5.2% on chest X-ray dictation and from 28.2% to 5.2% on comprehensive medical dictation benchmarks compared to Whisper-Large-v3, which provides a domain tuned speech front end for MedGemma-centric workflows.
check it out model weight And technical details. Also, feel free to follow us Twitter And don’t forget to join us 100k+ ml subreddit and subscribe our newsletter. wait! Are you on Telegram? Now you can also connect with us on Telegram.
Asif Razzaq Marktechpost Media Inc. Is the CEO of. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. Their most recent endeavor is the launch of MarketTechPost, an Artificial Intelligence media platform, known for its in-depth coverage of Machine Learning and Deep Learning news that is technically robust and easily understood by a wide audience. The platform boasts of over 2 million monthly views, which shows its popularity among the audience.