

Microsoft has released VibeVoice-ASR as part of the VibeVoice family of open source Frontier voice AI models. VibeVoice-ASR is described as an integrated speech-to-text model that can handle up to 60 minutes long audio in a single pass and output structured transcriptions encoding who, when and what with support for customized hotwords.
VibeVoice sits in a single store Which hosts text-to-speech, real time TTS and automatic speech recognition models under the MIT license. VibeVoice uses a continuous speech tokenizer that runs at 7.5 Hz and uses a next-token diffusion framework where a larger language model considers text and dialogue and a diffusion head generates acoustic descriptions. This framework is primarily documented for TTS, but it defines the overall design context in which VibeVoice-ASR lives.

Long form asr with single global reference
Unlike traditional ASR (Automatic Speech Recognition) systems, which first chop the audio into small segments and then run diarization and alignment as separate components, VibeVoice-ASR is designed to accept up to 60 minutes of continuous audio input within a 64K token length budget. The model maintains a global representation of the entire session. This means that the model can maintain speaker identity and subject context for an entire hour, rather than resetting every few seconds.
60 minutes single-pass processing
first main feature This is how many traditional ASR systems process long audio by cutting it into smaller segments, which can cause global context to be lost. Instead VibeVoice-ASR captures up to 60 minutes of continuous audio within a 64K token window so it can maintain consistent speaker tracking and semantic context throughout the recording.
This is important for tasks like meeting transcription, lectures, and long support calls. A single pass over the entire sequence simplifies the pipeline. There is no need to apply custom logic to merge partial hypotheses or repair speaker labels at the boundaries between audio segments.
Optimized hotwords for domain accuracy
Have optimized hotwords second key feature. Users can provide hotwords such as product names, organization names, technical terms, or background references. The model uses these hotwords to guide the identification process.
This allows you to bias the decoding towards correct spelling and pronunciation for domain specific tokens without retraining the model. For example, a dev-user can pass internal project names or customer specific conditions at estimation time. This is useful when deploying the same base model on multiple products that share similar acoustic conditions but very different terminology.
Microsoft also ships finetuning-asr Directory with LoRA based fine tuning scripts For VibeVoice-ASR. Together, hotwords and LoRa fine tuning provide a path to both lightweight optimization and deep domain expertise.
Rich transcription, diarizing, and timing
third characteristic Have rich transcription with who, when and what. The model jointly performs ASR, diarization, and timestamping, and returns a structured output that indicates who said what and when.
See three evaluation statistics called DER, cpWER, and tcpWER below.
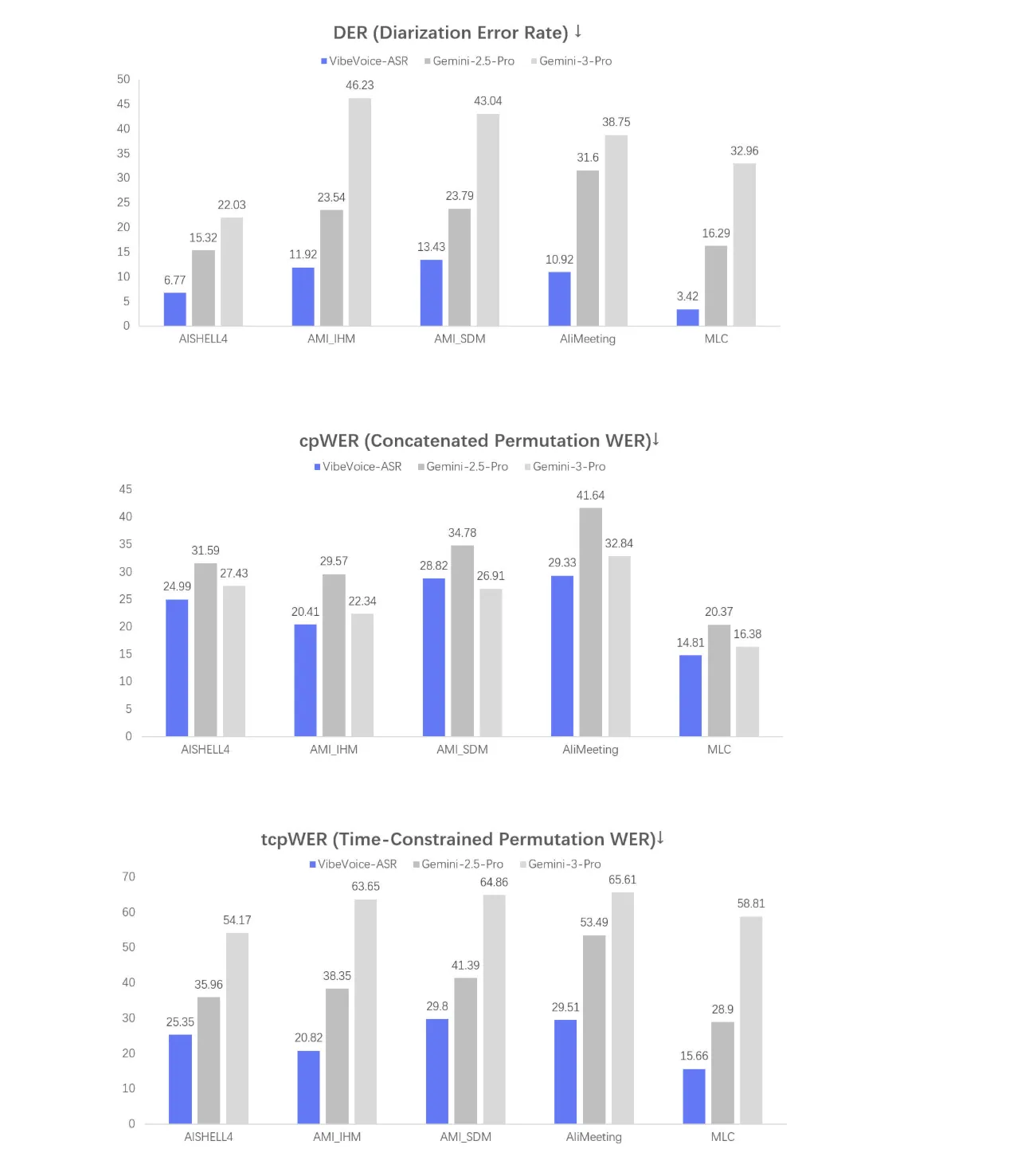
- DER is diarization error rate, it measures how well the model allocates speech segments to the correct speaker
- cpWER and tcpWER are word error rate metrics calculated under conversation settings
These graphs summarize how well the model performs on multi-speaker long form data, which is the primary target setting for this ASR system.
The structured output format is suitable for downstream processing such as speaker specific summaries, action item extraction, or analytics dashboards. Since the segments, speakers, and timestamps already come from the same model, downstream code can treat the transcripts as time aligned event logs.
key takeaways
- VibeVoice-ASR is an integrated speech to text model that handles 60 minutes long form audio in a single pass within a 64K token context.
- The model jointly performs ASR, diarization, and timestamping, so it outputs structured transcripts that encode who, when, and what in a single inference step.
- Customized hotwords let users inject domain specific terms like product names or technical jargon to improve detection accuracy without retraining the model.
- Evaluation with DER, CPWER, and TCPWER focuses on multi-speaker conversation scenarios that align the model with meetings, lectures, and long calls.
- VibeVoice-ASR is released in the VibeVoice open source stack under the MIT license with official weights, fine tuning scripts, and an online playground for experimentation.
check it out model weight, repo And playground. Also, feel free to follow us Twitter And don’t forget to join us 100k+ ml subreddit and subscribe our newsletter. wait! Are you on Telegram? Now you can also connect with us on Telegram.