

The success of machine learning pipelines depends on feature engineering as their essential foundation. As per your advanced techniques, the two most robust methods for handling time series data are Lag Features and Rolling Features. The ability to use these techniques will increase the performance of your models for sales forecasting, stock price prediction, and demand planning tasks.
This guide explains the interval and rolling features by showing their importance and providing Python implementation methods and potential implementation challenges through working code examples.
What is feature engineering in time series?
Time series feature engineering creates new input variables through the process of transforming raw temporal data into features that enable machine learning models to more effectively detect temporal patterns. Time series data differs from static datasets because it maintains a sequential structure, requiring observers to understand how previous observations influence what will happen next.
Traditional machine learning models XGBoost, LightGBM, and Random Forest lack built-in capabilities to process time. The system requires specific indicators that need to show past events that have occurred previously. Implementation of lag features with rolling features serves this purpose.
What are lag characteristics?
The lag feature is simply the previous value of a variable that has been shifted forward in time until it matches the current data point. The sales forecast for today depends on three different sales information sources, including yesterday’s sales data and both seven-day and thirty-day sales data.

Why do lag features matter
- They represent the relationship between different time periods when a variable shows its previous values.
- This method allows seasonal and cyclical patterns to be encoded without the need for complex transformations.
- This method provides simple calculations with clear results.
- The system works with all machine learning models that use tree structures and linear methods.
Implementing LAG Features in Python
import pandas as pd
import numpy as np
# Create a sample time series dataset
np.random.seed(42)
dates = pd.date_range(start="2024-01-01", periods=15, freq='D')
sales = (200, 215, 198, 230, 245, 210, 225, 260, 275, 240, 255, 290, 305, 270, 285)
df = pd.DataFrame({'date': dates, 'sales': sales})
df.set_index('date', inplace=True)
# Create lag features
df('lag_1') = df('sales').shift(1)
df('lag_3') = df('sales').shift(3)
df('lag_7') = df('sales').shift(7)
print(df.head(12))Output:
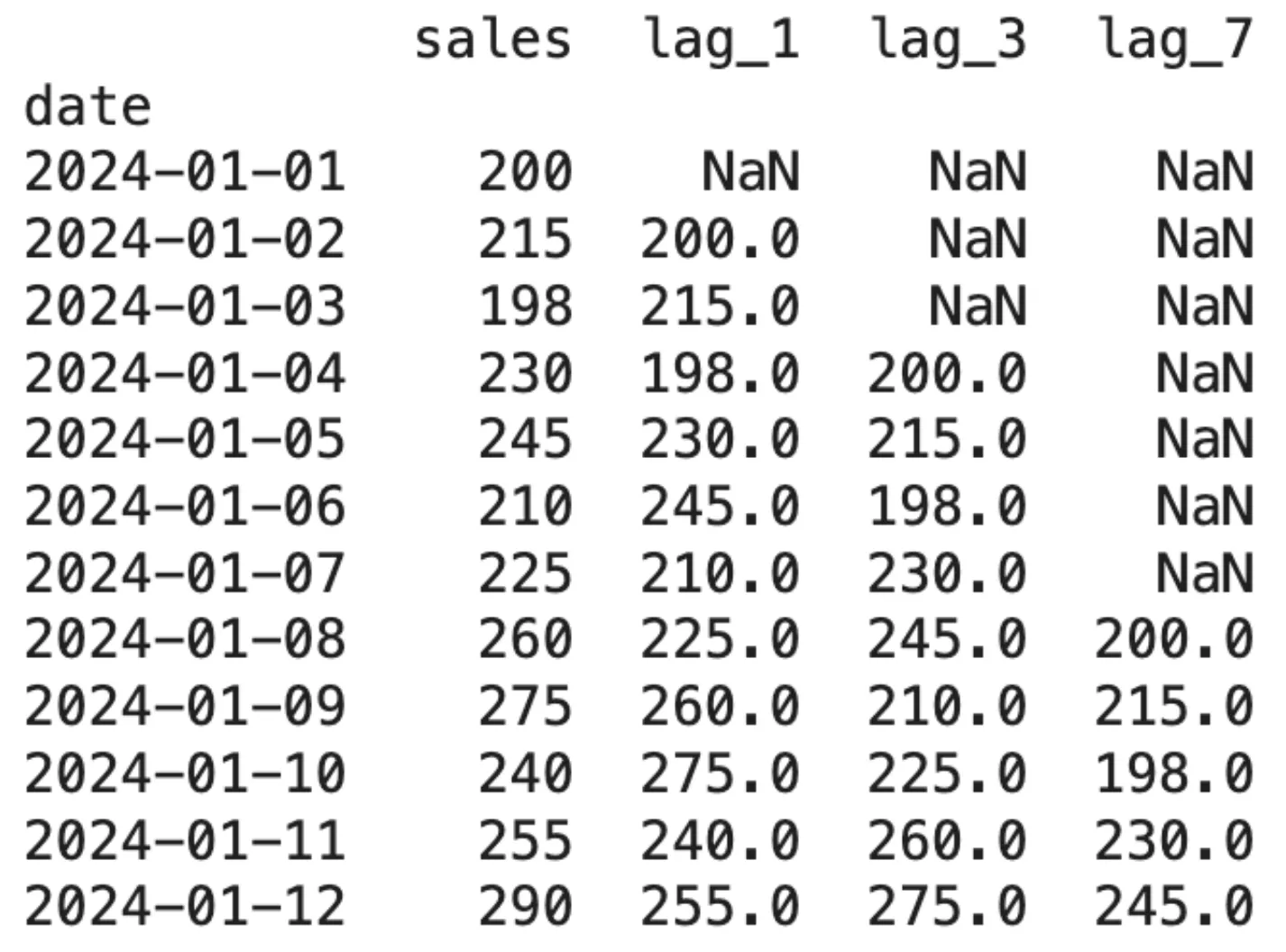
The initial appearance of NaN values indicates a form of data loss that is caused by lagging. This factor becomes important to determine the number of intervals to be created.
Choosing the Right Lag Value
The selection process for the optimal interval demands scientific methods that eliminate random selection as an option. The following methods have shown successful results in practice:
- Domain knowledge helps a lot, like weekly sales data? Add intervals on 7, 14, 28 days. Hourly energy data? Try for 24 to 48 hours.
- The autocorrelation function enables ACF users to determine which lags show significant links to their target variables through its statistical identification method.
- After you complete the training process the model will identify which intervals hold the most importance.
What are rolling (window) features?
Rolling features act as window features that move through time to calculate variable quantities. The system provides you with aggregate statistics, which include mean, median, standard deviation, minimum and maximum values for the last N periods, rather than showing you a single past value.

Why do rolling features matter?
The following features provide excellent capabilities to perform their specified functions:
- This process eliminates sound elements while it reveals the fundamental development pattern.
- This system enables users to observe short-term price fluctuations that occur within specific time periods.
- This system enables users to observe short-term price fluctuations that occur within specific time periods.
- The system identifies abnormal behavior when current values move away from the established rolling average.
The following aggregations establish their presence in rolling windows as standard practice:
- The most common method of trend smoothing uses a rolling mean as its primary method.
- The rolling standard deviation function calculates the degree of variability that exists within a specified time window.
- The Rolling Min and Max functions identify the highest and lowest values that occur during a specified time interval/period.
- The rolling median function provides accurate results for data that contains outliers and exhibits high levels of noise.
- The rolling sum function helps track the total volume or total count across time.
Implementing Rolling Features in Python
import pandas as pd
import numpy as np
np.random.seed(42)
dates = pd.date_range(start="2024-01-01", periods=15, freq='D')
sales = (200, 215, 198, 230, 245, 210, 225, 260, 275, 240, 255, 290, 305, 270, 285)
df = pd.DataFrame({'date': dates, 'sales': sales})
df.set_index('date', inplace=True)
# Rolling features with window size of 3 and 7
df('roll_mean_3') = df('sales').shift(1).rolling(window=3).mean()
df('roll_std_3') = df('sales').shift(1).rolling(window=3).std()
df('roll_max_3') = df('sales').shift(1).rolling(window=3).max()
df('roll_mean_7') = df('sales').shift(1).rolling(window=7).mean()
print(df.round(2))Output:
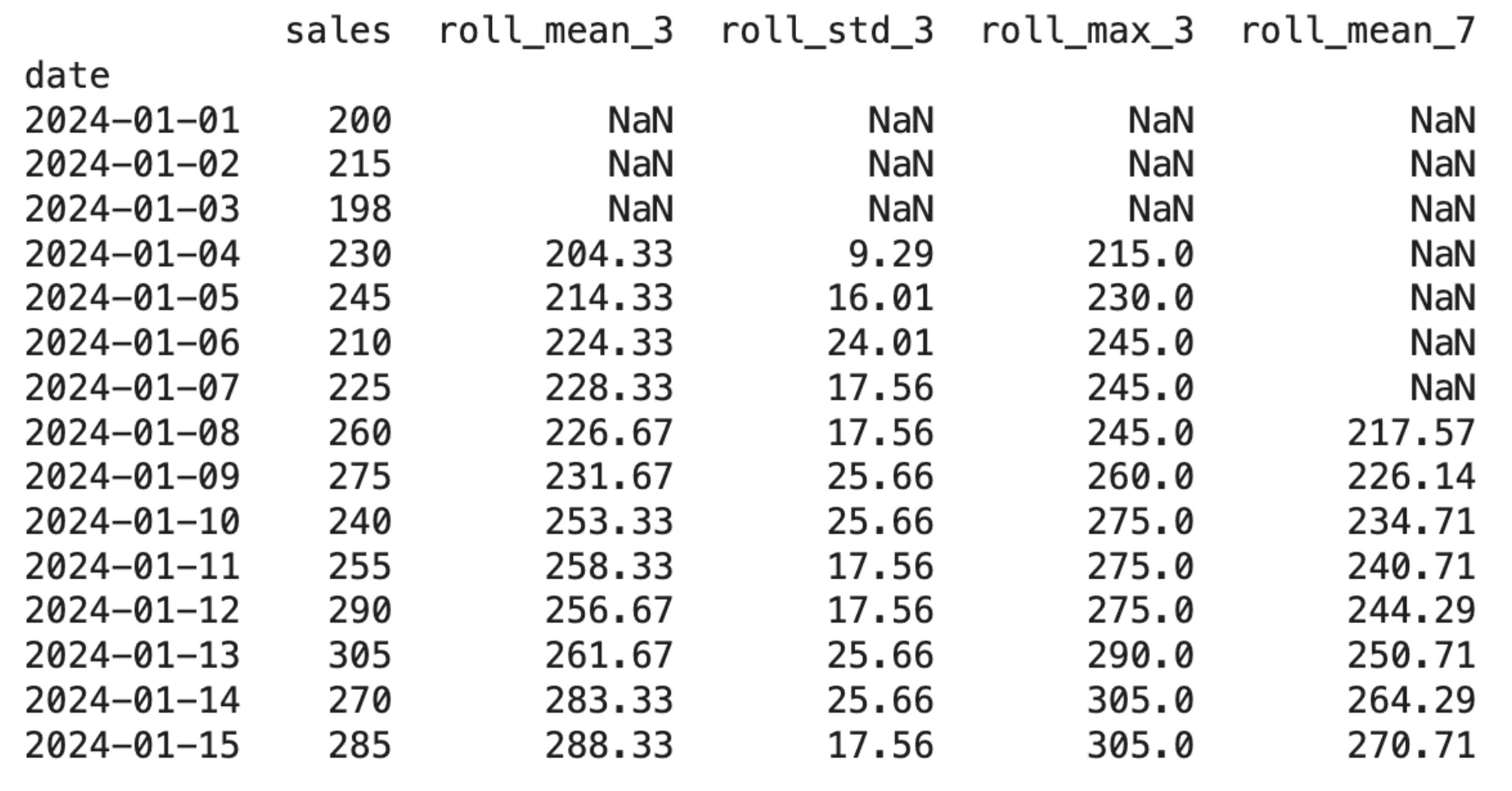
The .shift(1) function should be executed before the .rolling() function as it creates an important relationship between both functions. The system needs this mechanism because it will create rolling calculations that rely exclusively on historical data without using any current data.
Combining lag and rolling features: a production-ready example
In a real machine learning time series workflow, researchers create their own hybrid feature set, which includes both lagged features and rolling features. We provide you with complete feature engineering functions that you can use for any project.
import pandas as pd
import numpy as np
def create_time_features(df, target_col, lags=(1, 3, 7), windows=(3, 7)):
"""
Create lag and rolling features for time series ML.
Parameters:
df : DataFrame with datetime index
target_col : Name of the target column
lags : List of lag periods
windows : List of rolling window sizes
Returns:
DataFrame with new features
"""
df = df.copy()
# Lag features
for lag in lags:
df(f'lag_{lag}') = df(target_col).shift(lag)
# Rolling features (shift by 1 to avoid leakage)
for window in windows:
shifted = df(target_col).shift(1)
df(f'roll_mean_{window}') = shifted.rolling(window).mean()
df(f'roll_std_{window}') = shifted.rolling(window).std()
df(f'roll_max_{window}') = shifted.rolling(window).max()
df(f'roll_min_{window}') = shifted.rolling(window).min()
return df.dropna() # Drop rows with NaN from lag/rolling
# Sample usage
np.random.seed(0)
dates = pd.date_range('2024-01-01', periods=60, freq='D')
sales = 200 + np.cumsum(np.random.randn(60) * 5)
df = pd.DataFrame({'sales': sales}, index=dates)
df_features = create_time_features(df, 'sales', lags=(1, 3, 7), windows=(3, 7))
print(f"Original shape: {df.shape}")
print(f"Engineered shape: {df_features.shape}")
print(f"nFeature columns:n{list(df_features.columns)}")
print(f"nFirst few rows:n{df_features.head(3).round(2)}")Output:

Common Mistakes and How to Avoid Them
The most serious error in time series feature engineering occurs when data leakage, which reveals upcoming data for testing features, leads to misleading model performance.
Main mistakes to beware of:
- The process requires a .shift(1) command before starting the .rolling() function. The current observation will become part of the rolling window because rolling requires the first observation to be moved.
- Data loss occurs due to the addition of lags because each lag produces NaN rows. A 100-row dataset will lose 30% of its data because 30 lags require creating 30 NaN rows.
- This process requires different window size experiments because different features require different window sizes. This process requires testing short windows, which range from 3 to 5, and long windows, which range from 14 to 30.
- For a production environment you need to calculate the rolling and lag features from actual historical data that you will use during inference time, rather than using your training data.
When to use lag vs rolling features
| Example | Recommended Features |
|---|---|
| Strong autocorrelation in data | Interval Features (Interval-1, Interval-7) |
| Noisy signal, needs smoothing | rolling mean |
| Seasonal Pattern (Weekly) | Lag-7, Lag-14, Lag-28 |
| trend spotting | means rolling on long windows |
| anomaly detection | deviation from rolling mean |
| Capturing Variability/Risk | rolling standard deviation, rolling range |
conclusion
Time series machine learning infrastructure uses lagged features and rolling features as its essential components. The two methods establish a path from unprocessed sequential data to the organized data format that a machine learning model needs for its training process. When users execute them with accurate data handling and window selection methods and their relevant understanding of the specific area, the methods become the highest impact factor for prediction accuracy.
The best part? They provide clear explanations that require minimal computing resources and work with any machine learning model. Whether you use XGBoost for demand forecasting, LSTM for anomaly detection, or linear regression for baseline models, you will benefit from these features.
![]()
General AI Intern at Analytics Vidya
Department of Computer Science, Vellore Institute of Technology, Vellore, India
I am currently working as the General AI Intern at Analytics Vidya, where I contribute to innovative AI-powered solutions that empower businesses to effectively leverage data. As a final year Computer Science student at Vellore Institute of Technology, I bring a solid foundation in software development, data analytics and machine learning to my role.
Feel free to connect with me at (email protected)
Login to continue reading and enjoy expertly curated content.