

Researchers at the Allen Institute for AI (AI2) have introduced SERA, Soft Verified Efficient Repository Agents, as a coding agent family that aims to match very large closed systems using only supervised training and synthetic trajectories.
What is sera?
SERA is the first release in AI2’s open coding agent series. The flagship model, SERA-32B, is built on the Qwen 3 32B architecture and is trained as a repository level coding agent.
Verified at the 32K reference on the SWE bench, the SERA-32B reaches a 49.5 percent resolution rate. In the 64K context it reaches 54.2 percent. These numbers put it in the same performance band as open weight systems such as the Devstral-Small-2 with 24B parameters and the GLM-4.5 Air with 110B parameters, while SERA remains completely open in code, data and weights.
The series today consists of four models, the SERA-8B, SERA-8B GA, SERA-32B, and SERA-32B GA. All are released on Hugging Face under the Apache 2.0 license.
soft verified generation
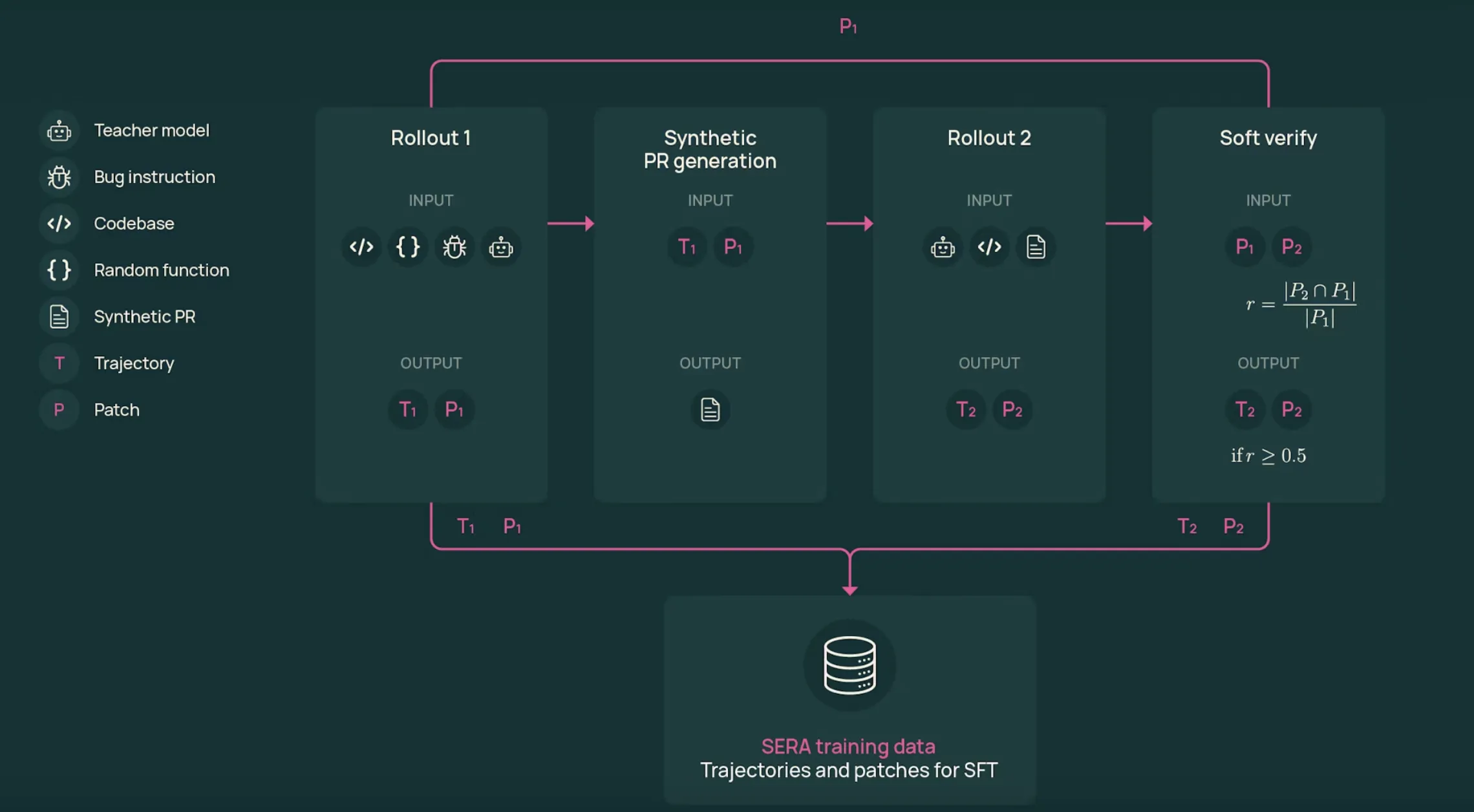
The training pipeline relies on soft verified generation,SVG. The SVG agent produces trajectories that look like realistic developer workflows, then uses patch agreement between two rollouts as a soft indication of correctness.
The process is this:
- first rollout: A function is sampled from the real repository. The teacher model, GLM-4.6, in the SERA-32B setup receives a bug style or change description and works with tools to view files, edit code, and run commands. This generates a trajectory T1 and a patch P1.
- synthetic pull request: Converts the system trajectory into details such as a pull request. This text summarizes the intent and main edits in the same format as actual pull requests.
- second rollout: The teacher restarts from the original repository, but now only sees the pull request details and tools. This generates a new trajectory T2 and patch P2 that attempts to apply the described transformation.
- soft verification: Patches P1 and P2 are compared line by line. The recall score r is calculated as the fraction of modified lines in P1 that appear in P2. When r equals 1 the trajectory is hard to verify. For intermediate values, the sample is verified soft.
The main result of ablation studies is that strict validation is not required. When the model is trained on the T2 trajectory with varying thresholds on R, with R also equal to 0, the performance on the SWE bench verified is similar to a fixed sample count. This shows that realistic multi-step traces, even if noisy, are valuable observations for coding agents.
Data Scale, Training, and Cost
SVG is implemented on 121 Python repositories obtained from the SWE-Smith corpus. In the GLM-4.5 Air and GLM-4.6 Teacher runs, the full SERA dataset includes over 200,000 trajectories from both rollouts, making it one of the largest open coding agent datasets.
SERA-32B is trained on a subset of 25,000 T2 trajectories from the SERA-4.6-Lite T2 dataset. Training uses standard supervised fine tuning with Axolotl on QUEN-3-32B for 3 epochs, learning rate 1e-5, weight decay 0.01, and maximum sequence length 32,768 tokens.
Many trajectories are longer than the reference range. The research team defines the truncation ratio, the fraction of steps that fit into 32K tokens. They then give priority to trajectories that are already fit, and for the rest they select slices with higher truncation ratios. This ordered truncation strategy clearly outperforms random truncation when they compare SWE bench verified scores.
The reported computation budget for SERA-32B, including data generation and training, is approximately 40 GPU days. Using the scaling law on dataset size and performance, the research team estimated that the SVG approach is approximately 26 times cheaper than reinforcement learning based systems like SkyRL-Agent and 57 times cheaper than previous synthetic data pipelines like SWE-Smith to reach the same SWE-Bench score.

stock specialization
A central use case is to customize an agent to a specific repository. The research team conducts its study on three major SWE-bench verified projects, Django, SymPy, and Sphinx.
For each repository, the SVG is generated on the order of 46,000 to 54,000 trajectories. Due to compute limitations, expertise experiments are trained on 8,000 trajectories per repository, consisting of 3,000 soft verified T2 trajectories mixed with 5,000 filtered T1 trajectories.
In the 32K context, these specific students match or slightly outperform the GLM-4.5-air teacher, and also compare well with devstral-small-2 on those repository subsets. For Django, a particular student reaches a resolution rate of 52.23 percent compared to 51.20 percent for GLM-4.5-air. For SIMP, the particular model reaches 51.11 percent versus 48.89 percent for GLM-4.5-air.
key takeaways
- SERA turns coding agents into a supervised learning problem: SERA-32B is trained on synthetic trajectories from GLM-4.6 with standard supervised fine tuning, with no reinforcement learning loops and no dependency on repository test suites.
- Soft verified generation removes the need for tests:SVG uses two rollouts and patch overlap between P1 and P2 to calculate soft verification scores, and the research team shows that even unverified or weakly verified trajectories can train effective coding agents.
- Large, realistic agent dataset from real repositories:The pipeline applies SVG to 121 Python projects from the SWE Smith corpus, producing over 200,000 trajectories and creating one of the largest open datasets for coding agents.
- Efficient training with clear cost and scaling analysis: SERA-32B runs on 25,000 T2 trajectories and scaling studies show that SVG is approximately 26 times cheaper than SkyRL-Agent and 57 times cheaper than SWE-Smith at the same SWE bench verified performance.
check it out paper, repo And model weight. Also, feel free to follow us Twitter And don’t forget to join us 100k+ ml subreddit and subscribe our newsletter. wait! Are you on Telegram? Now you can also connect with us on Telegram.