

The Alibaba Tongyi Lab research team released ‘Zweck’, an open source, in-process vector database targeting edge and on-device recovery workloads. It is ranked as the ‘SQLite of vector databases’ because it runs as a library inside your application and does not require any external services or daemons. It is designed for retrieval augmented generation (RAG), semantic search, and agent workloads that must run locally on laptops, mobile devices, or other constrained hardware/edge devices.
The basic idea is simple. Many applications now need vector searching and metadata filtering but do not want to run a separate vector database service. Traditional server style systems are heavy on desktop tools, mobile apps, or command line utilities. An embedded engine that behaves like SQLite but fits this gap for embedding.
Why does embedded vector search matter for RAG??
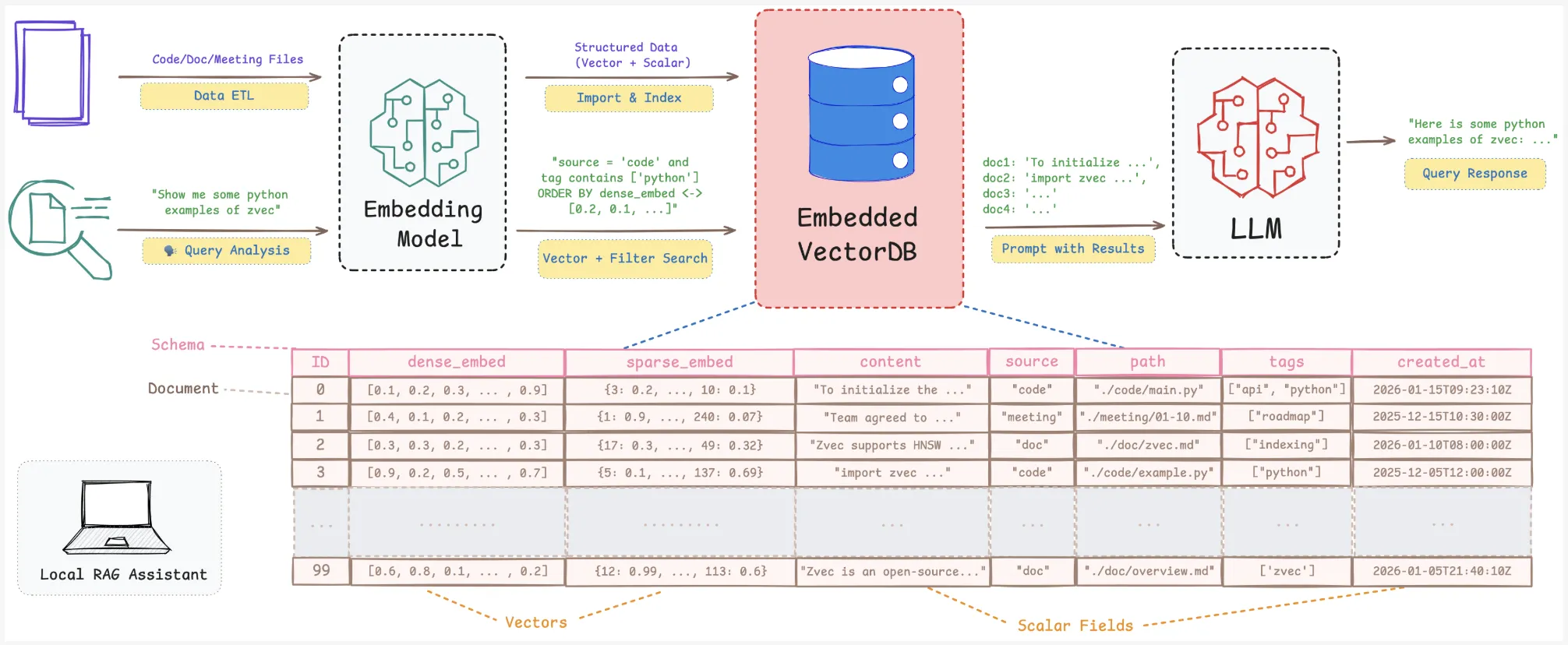
RAG and semantic search pipelines require more than a bare index. They need vectors, scalar fields, full CRUD, and safe persistence. The local knowledge base changes as files, notes, and project status change.
Index libraries like Phaze provide approximate nearest neighbor search but cannot handle scalar storage, crash recovery, or hybrid queries. You end up building your own storage and persistence layer. Embedded extensions like DuckDB-VSS add vector search to DuckDB but expose fewer index and quantization options and weaker resource controls for edge scenarios. Service based systems like Milvus or Managed Vector Cloud require network calls and separate deployments, which is often excessive for on-device tools.
Zweck claims to be specifically fit for these local scenarios. It provides you with a vector-native engine with persistence, resource administration, and RAG-oriented features packaged as a lightweight library.
Core Architecture: In-Process and Vector-Native
Zvec is implemented as an embedded library. you install it pip install zvec And open the archive directly in your Python process. There is no external server or RPC layer. You define the schema, insert documents, and run queries through the Python API.
The engine is built on Proxima, Alibaba Group’s high-performance, production grade, battle-tested vector search engine. Zvec wraps Proxima with a simple API and embedded runtime. This project is released under the Apache 2.0 license.
Current support covers Python 3.10 to 3.12 on Linux x86_64, Linux ARM64, and macOS ARM64.
The design goals are clear:
- Embedded execution is in process
- vector native indexing and storage
- Production-ready strength and crash safety
This makes it suitable for edge devices, desktop applications, and zero-ops deployments.
Developer Workflow: From Install to Semantic Search
The quickstart document shows a shortcut from install to query.
- Install package:
pip install zvec - define a
CollectionSchemaWith one or more vector fields and optional scalar fields. - call out
create_and_openTo create or open an archive on disk. - Pour
DocObjects that have an ID, vector, and scalar attributes. - create and run an index
VectorQueryTo retrieve nearest neighbors.
Example:
import zvec
# Define collection schema
schema = zvec.CollectionSchema(
name="example",
vectors=zvec.VectorSchema("embedding", zvec.DataType.VECTOR_FP32, 4),
)
# Create collection
collection = zvec.create_and_open(path="./zvec_example", schema=schema,)
# Insert documents
collection.insert((
zvec.Doc(id="doc_1", vectors={"embedding": (0.1, 0.2, 0.3, 0.4)}),
zvec.Doc(id="doc_2", vectors={"embedding": (0.2, 0.3, 0.4, 0.1)}),
))
# Search by vector similarity
results = collection.query(
zvec.VectorQuery("embedding", vector=(0.4, 0.3, 0.3, 0.1)),
topk=10
)
# Results: list of {'id': str, 'score': float, ...}, sorted by relevance
print(results)The results are returned as dictionaries that contain IDs and similarity scores. It is enough to build a local semantic search or RAG retrieval layer on top of any embedding model.
Performance: VectorDBBench and 8,000+ QPS
Zvec is optimized for high throughput and low latency on CPUs. It uses multithreading, cache friendly memory layout, SIMD instructions, and CPU prefetching.
In vectordbbench On the Cohere 10M dataset, with comparable hardware and matched recall, Zvec reports over 8,000 QPS. This is 2× more than the previous leaderboard #1, ZillizCloud, while also significantly reducing index creation time in the same setup.

These metrics show that an embedded library can reach cloud level performance for high volume similarity search, as long as the workload resembles benchmark conditions.
RAG Capabilities: CRUD, Hybrid Search, Fusion, Reranking
The feature set is tuned for RAG and agentive recovery.
Zweck supports:
- Full CRUD on documents so that the local knowledge base can change over time.
- Schema development to accommodate index strategies and fields.
- Multi vector retrieval for queries that combine multiple embedding channels.
- A built-in reranker that supports weighted fusion and reciprocal rank fusion.
- Scalar vector hybrid search that pushes scalar filters into the index execution path, with optional inverted indexes for scalar attributes.
It allows you to create device assistants that combine semantic retrieval, filters like user, time or type, and multiple embedding models within one embedded engine.
key takeaways
- Zvec is an embedded, in-process vector database that is deployed as the ‘SQLite of vector databases’ for on-device and edge RAG workloads.
- It is built on Proxima, Alibaba’s high performance, production grade, battle tested vector search engine, and is released under Apache 2.0 with Python support on Linux x86_64, Linux ARM64, and macOS ARM64.
- Zvec delivers over 8,000 QPS on VectorDBBench with the Cohere 10M dataset, achieving over 2× the previous leaderboard #1 (ZillizCloud), while also reducing index creation time.
- The engine offers explicit resource administration through 64 MB streaming rights, optional MMAP mode, experimental
memory_limit_mband configurableconcurrency,optimize_threadsAndquery_threadsFor CPU control. - Zvec is RAG ready with full CRUD, schema evolution, multi vector retrieval, built-in reranking (weighted fusion and RRF) and scalar vector hybrid search with optional inverted indexes, as well as an ecosystem roadmap targeting Langchain, LlamaIndex, DuckDB, PostgreSQL and real device deployment.
check it out technical details And repo. Also, feel free to follow us Twitter And don’t forget to join us 100k+ ml subreddit and subscribe our newsletter. wait! Are you on Telegram? Now you can also connect with us on Telegram.
