

How do you keep the RAG system accurate and efficient when each query attempts to populate thousands of tokens into the context window and the retriever and generator are still optimized as 2 separate, disconnected systems? a team of researchers Apple and the University of Edinburgh release CLaRa, Continuous Latent Reasoning, (CLaRa-7B-Base, CLaRa-7B-Instruct and CLaRa-7B-E2E) is a retrieval augmented generation framework that compresses documents into continuous memory tokens and then performs both retrieval and generation in that shared latent space. The goal is simple. Minimize the context, avoid double encoding, and let the generator teach the retriever what really matters for downstream answers.
From raw documents to persistent memory tokens
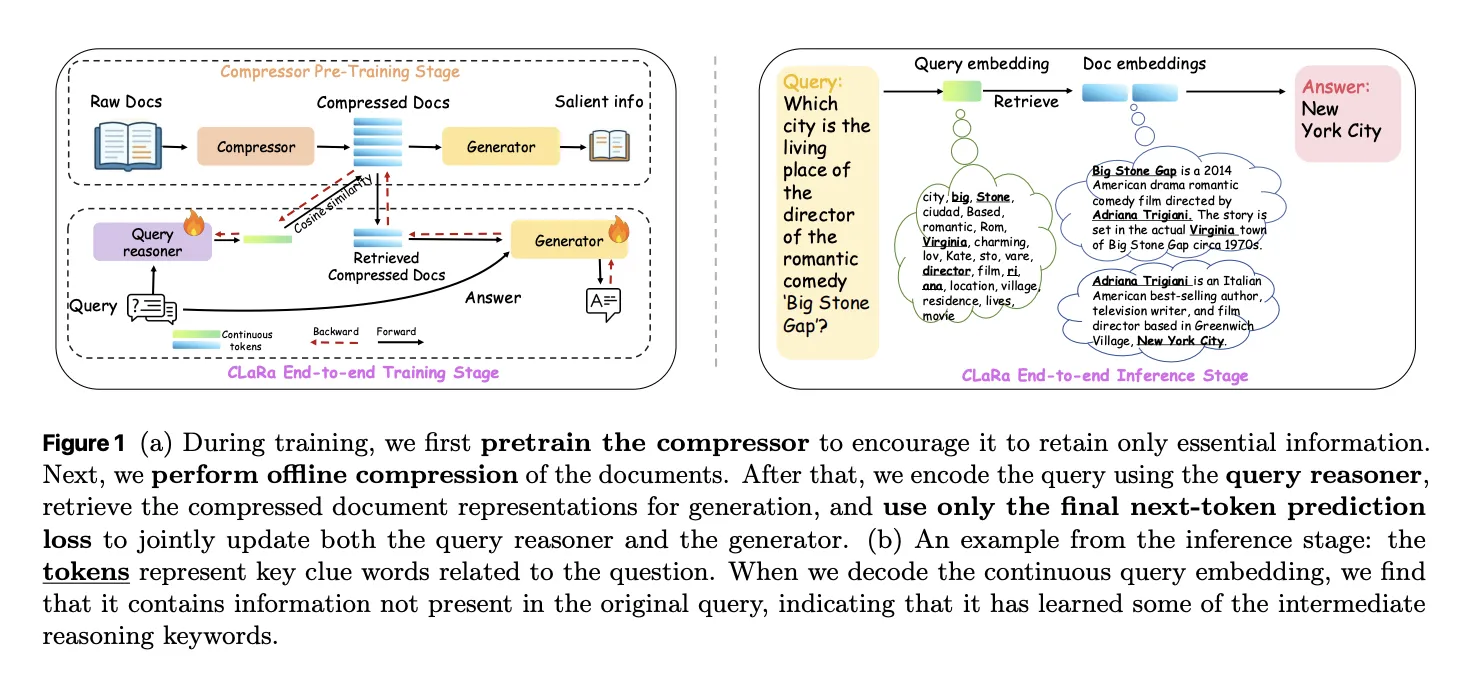
CLaRa starts with a semantic compressor that adds a small number of learned memory tokens to each document. during Main Compressor Pretraining, scp, The base model is a Mistral 7B style transformer with a LoRA adapter that switches between the compressor role and the generator role. The last layer of memory tokens hide states that become a compressed representation for that document.
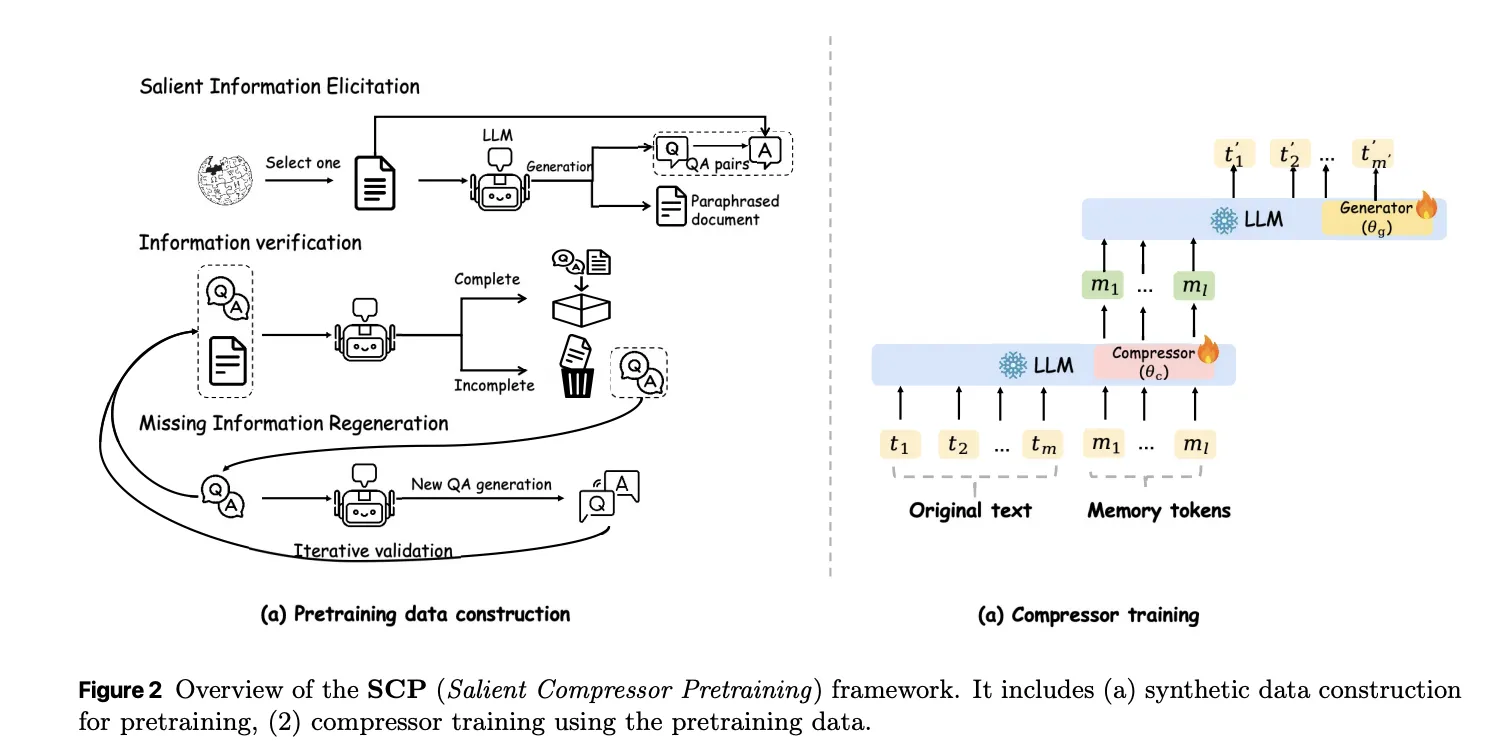
The SCP is trained on approximately 2M routes from Wikipedia 2021. A local QUEN-32B model generates 3 observation signals for each pathway. Simple QA pairs cover the nuclear facts. Complex QA pairs multiple facts into one query to implement multi-hop logic. Paraphrases rearrange and compress text while preserving semantics. A validation loop checks factual consistency and coverage and can reproduce missing questions or interpretations for up to 10 rounds before accepting the sample.
There are 2 losses used in training. Trains a cross entropy word generator to answer questions or generate paraphrases conditioned only on memory tokens and an instruction prefix. A mean square error term aligns the average latent state of document tokens with the average latent state of memory tokens. The MSE loss gives a slight but consistent gain of about 0.3 to 0.6 F1 points at compression ratios 32 and 128 and keeps the compressed and original representations in the same semantic region.
Joint retrieval and generation in shared space
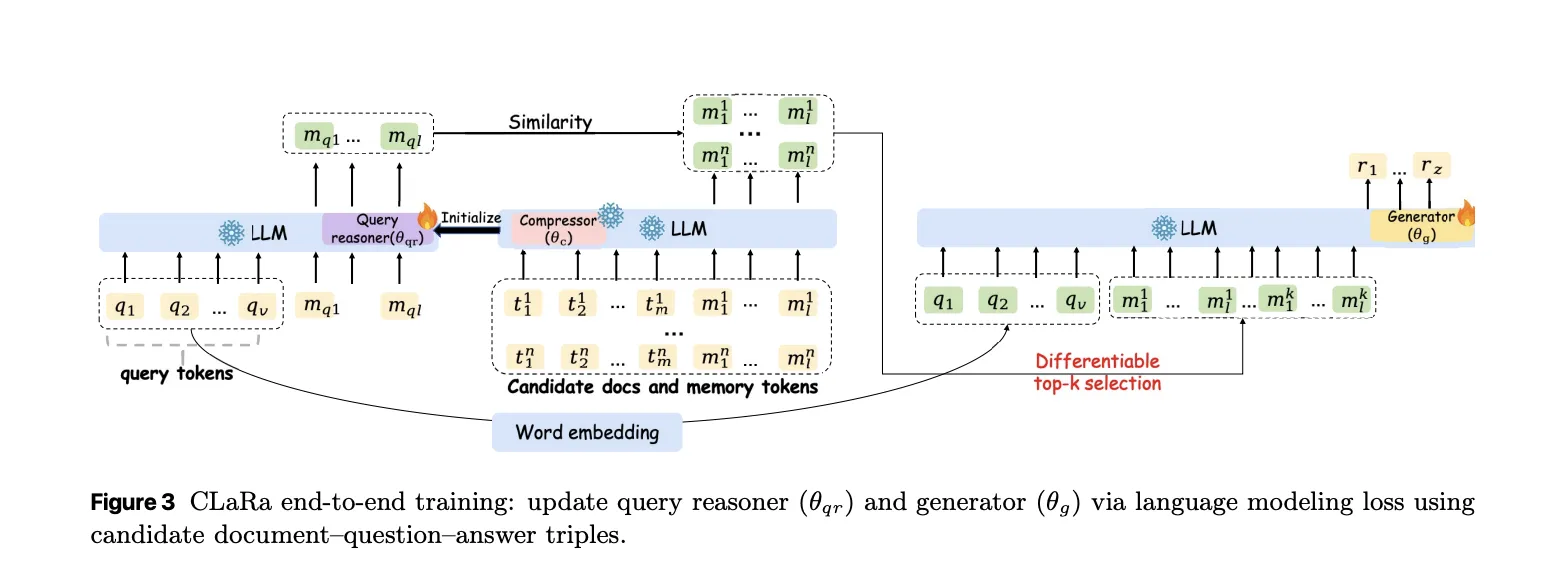
After offline compression, each document is represented only by its memory token. CLaRa then trains a query reasoner and an answer generator on the same basis. Query Reasoner is another LoRA adapter that maps an input query to the same number of memory tokens used for documents. Retrieval becomes pure embedding search. The system calculates the cosine similarity between the query embedding and each candidate document embedding.
The best compressed document embedding for a query is combined with the query token and fed into the generator adapter. Training uses only a standard next token prediction loss on the last answer. There are no clear relevance labels. The key trick is a discrete vertex k selector implemented with a straight through estimator. The model uses hard top selection during the forward pass. Softmax distribution on document scores during the backward pass allows gradients from the generator to flow into the query reasoner parameters.
The research team shows 2 effects in gradient analysis. First, the retriever is encouraged to assign higher probability to documents that increase answer probability. Second, because retrieval and generation share the same compressed representations, generator gradients reshape the latent document space to make it easier to reason about. Logit lens analysis of query embeddings recovers topic tokens such as “NFL” and “Oklahoma” for a query about Ivory Lee Brown’s nephew, even though those tokens are not in the raw query but are present in supporting articles.
Compression quality and QA accuracy
Compressor is evaluated on 4 QA datasets: Natural Questions, HotpotQA, MuSiQue and 2WikiMultihopQA. Under normal settings, where the system retrieves the top 5 Wikipedia 2021 documents per query, SCP-Mistral-7b reaches an average F1 of 39.86 at 4x compression. It is 5.37 points better than the hard compression baseline LLMLingua 2 and 1.13 points better than the best soft compression baseline PISCO.
Under the oracle setting, where the gold document is guaranteed to be in the candidate set, SCP-Mistral-7b reaches an average F1 of 66.76 at 4x compression. This is 17.31 points above LLMlingua-2 and 5.35 points above PISCO. What is even more interesting is that the compressed representation outperforms the BGE based text retriever and the full document Mistral-7B generator by about 2.36 average F1 points for Mistral and about 6.36 points for Fi4 Mini. Well-trained soft compression can exceed full text RAG while reducing the reference length by factors ranging from 4 to 128.
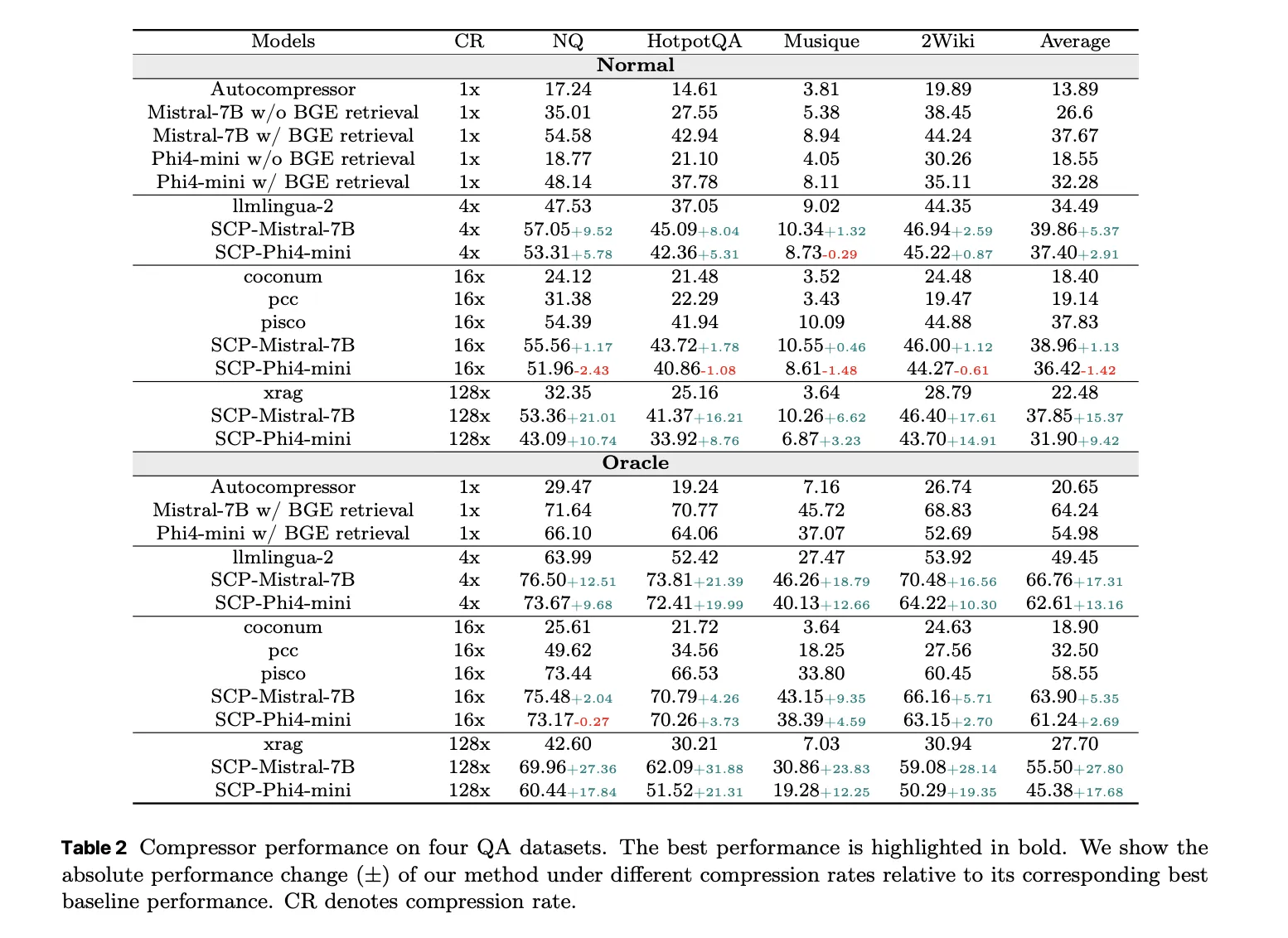
In Oracle, performance degrades at very high compression ratios, above 32, but the degradation remains moderate under normal recovery conditions. The main explanation according to the research team is that weak document relevance hinders the system before compression quality.
End-to-end QA and recovery practices
For end-to-end QA, CLaRa uses 20 candidate documents per query with compression ratios 4, 16, and 32. On normal settings, the CLaRa-Mistral-7B instruction reaches F1 equal to 50.89 on natural queries and 44.66 on 2WikiMultihopQA with initial weights and 16x compression. This is comparable to DRO-Mistral-7B, which reads full uncompressed text using a 16 times smaller document representation. On some datasets, CLaRa at 16x compression improves F1 slightly compared to DRO, for example from 43.65 to 47.18 on 2Wiki.
In the oracle setting, CLaRa-Mistral-7b outperforms F1 by 75 on both Natural Queries and HotpotQuery at 4x compression. This shows that the generator can fully exploit precise recovery even when all evidence is stored only in compressed memory tokens. Initialized CLaRa generally wins over pre-training initialized CLaRa in the general setting, while the difference diminishes in Oracle, where retrieval noise is limited.
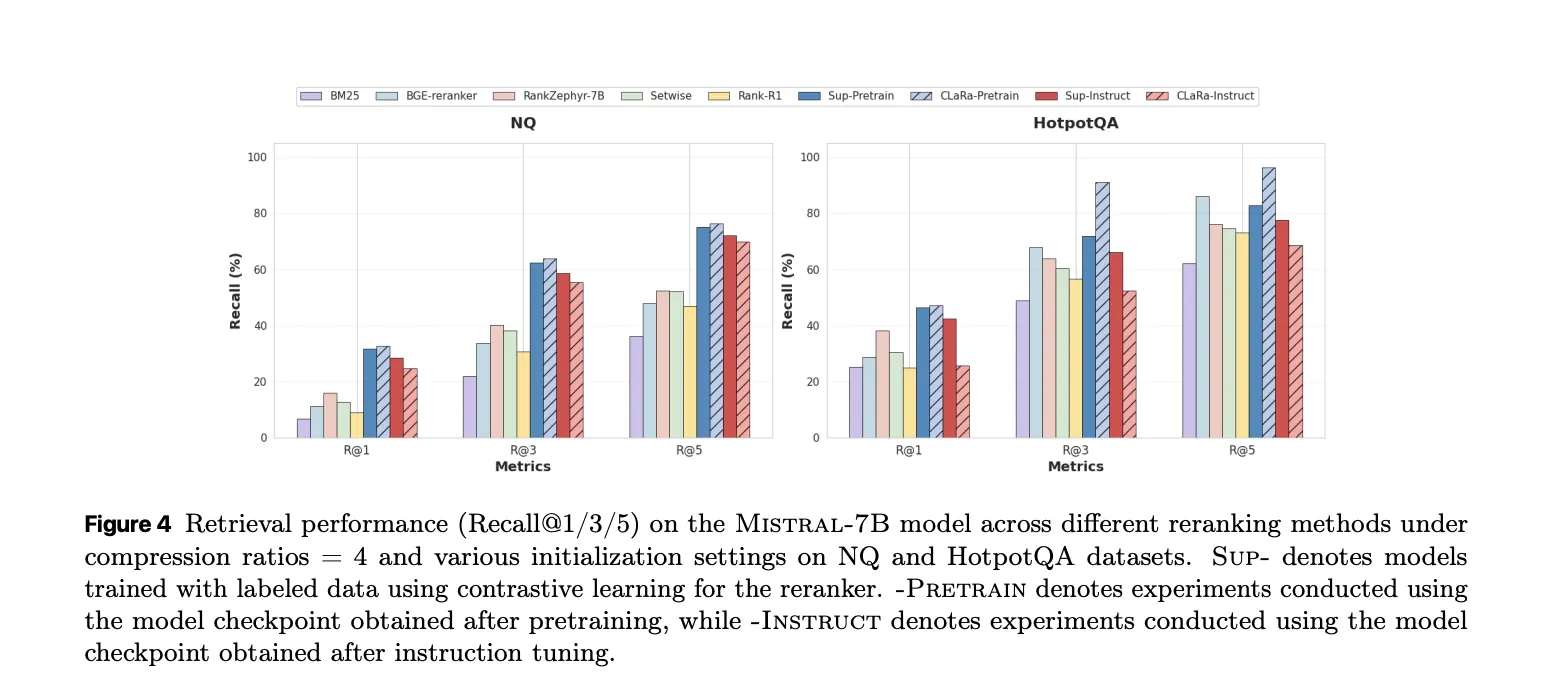
On the retrieval side, CLARA used as a reranker under Oracle conditions provides strong recalls at 5. With pretraining initialization at compression 4 on HotpotQA, CLARA-Mistral-7B reaches recall at 5 equal to 96.21. It outperforms the supervised BGE reranker baseline by 10.28 points at 85.93 and even outperforms the fully supervised super instructed retriever trained with conflicting relevance labels.
What has Apple released?
Apple’s research team released 3 models on Hugging Face: CLaRa-7B-Base, CLaRa-7B-Instruct and CLaRa-7B-E2E. CLaRa-7B-Instruct is described as an instruction tuned integrated RAG model with built-in document compression at 16 and 128 times. It answers instruction style queries directly from compressed representations and uses mistral-7b-instruct v0.2 as the base model.
key takeaways
- CLaRa replaces raw documents with a small set of persistent memory tokens learned through QA guided and paraphrase guided semantic compression, preserving key logic signals even at 16x and 128x compression.
- Retrieval and generation are trained in the same shared latent space, the query encoder and generator share the same compressed representation and are optimized together with a language modeling loss.
- A discrete top-k estimator allows gradients to flow from answer tokens back to the retriever, which aligns document relevance with answer quality and removes the discontinuous tuning loop common to RAG systems.
- On multi-hop QA benchmarks such as Natural Query, HotPotQA, MuCQ and 2WikiMultiHopQA, CLARA’s SCP Compressor outperforms strong text-based baselines such as LLMingua 2 and PISCO at 4x compression and can even beat full-text BGE/Mistral pipelines on average F1.
- Apple has released 3 practical models, CLaRa-7B-Base, CLaRa-7B-Instruct, and CLaRa-7B-E2E, with full training pipelines on GitHub.
Editorial Notes
CLaRa is an important step forward for the retrieval augmented generation because it treats semantic document compression and joint optimization in a shared persistent space as first-class citizens, not afterthoughts simply bolted onto a text pipeline. This demonstrates that embedding-based compression with SCP, combined with end-to-end training via a discrete top-k estimator and single language modeling loss, can match or outperform text-based RAG baselines using much smaller contexts and simpler retrieval stacks. Overall, CLARA demonstrates that unified continuous latent logic is a reliable alternative to classic chunk and recover RAGs for real-world QA workloads.
check it out paper, Model load on HF And repoFeel free to check us out GitHub page for tutorials, code, and notebooksAlso, feel free to follow us Twitter And don’t forget to join us 100k+ ml subreddit and subscribe our newsletterwait! Are you on Telegram? Now you can also connect with us on Telegram.
Asif Razzaq Marktechpost Media Inc. Is the CEO of. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. Their most recent endeavor is the launch of MarketTechPost, an Artificial Intelligence media platform, known for its in-depth coverage of Machine Learning and Deep Learning news that is technically robust and easily understood by a wide audience. The platform boasts of over 2 million monthly views, which shows its popularity among the audience.