

Today, we are publishing a New open source sample chatbot It shows how to use feedback from automated reasoning checks to iterate on generated content, ask clarifying questions, and prove the correctness of answers.
Chatbot implementations also produce an audit log that includes mathematically verifiable explanations for answer validity and a user interface that shows developers the iterative, rewriting process that occurs behind the scenes. Automated reasoning tests automatically use logical deduction to demonstrate that a statement is true. Unlike large language models, automated reasoning tools are not guessing or predicting accuracy. Instead, they rely on mathematical proofs to verify compliance with policies. This blog post dives deeper into the implementation architecture of the Automated Reasoning Check Rewriting Chatbot.
Improve accuracy and transparency with automated logic checking
LLMs can sometimes produce responses that seem convincing but contain factual errors – a phenomenon known as hallucination. Automated reasoning checks validate the user question and the LLM-generated answer, providing rewritten responses that point out vague statements, overly broad claims, and factually incorrect claims based on the ground truth knowledge encoded in the automated reasoning policies.
A chatbot that uses automated reasoning checks to double-check your answers before presenting them to users helps Improvement accuracy Because it can provide precise statements that clearly answer users’ yes/no questions without leaving room for ambiguity; And Helps improve transparency Because it can provide mathematically verifiable proof of why its statements are true, making generic AI applications auditable and explainable even in regulated environments.
Now that you understand its benefits, let’s see how you can implement it in your applications.
Chatbot Reference Implementation
chatbot There is a Flask application that exposes APIs for submitting questions and checking the status of answers. To show the inner workings of the system, the API also lets you get information about the status of each iteration, feedback from the automated reasoning checks, and rewrite signals sent to the LLM.
You can use a frontend NodeJS application to configure LLM from Amazon Bedrock to generate answers, select an automated reasoning policy for validation, and set the maximum number of iterations to get an answer correct. Selecting a chat thread in the user interface opens a debug panel on the right that displays each iteration over the content and validation output.
Figure 1 – Chat interface with debug panel
Once the automated logic check shows that the response is valid, a verifiable explanation for validity is displayed.
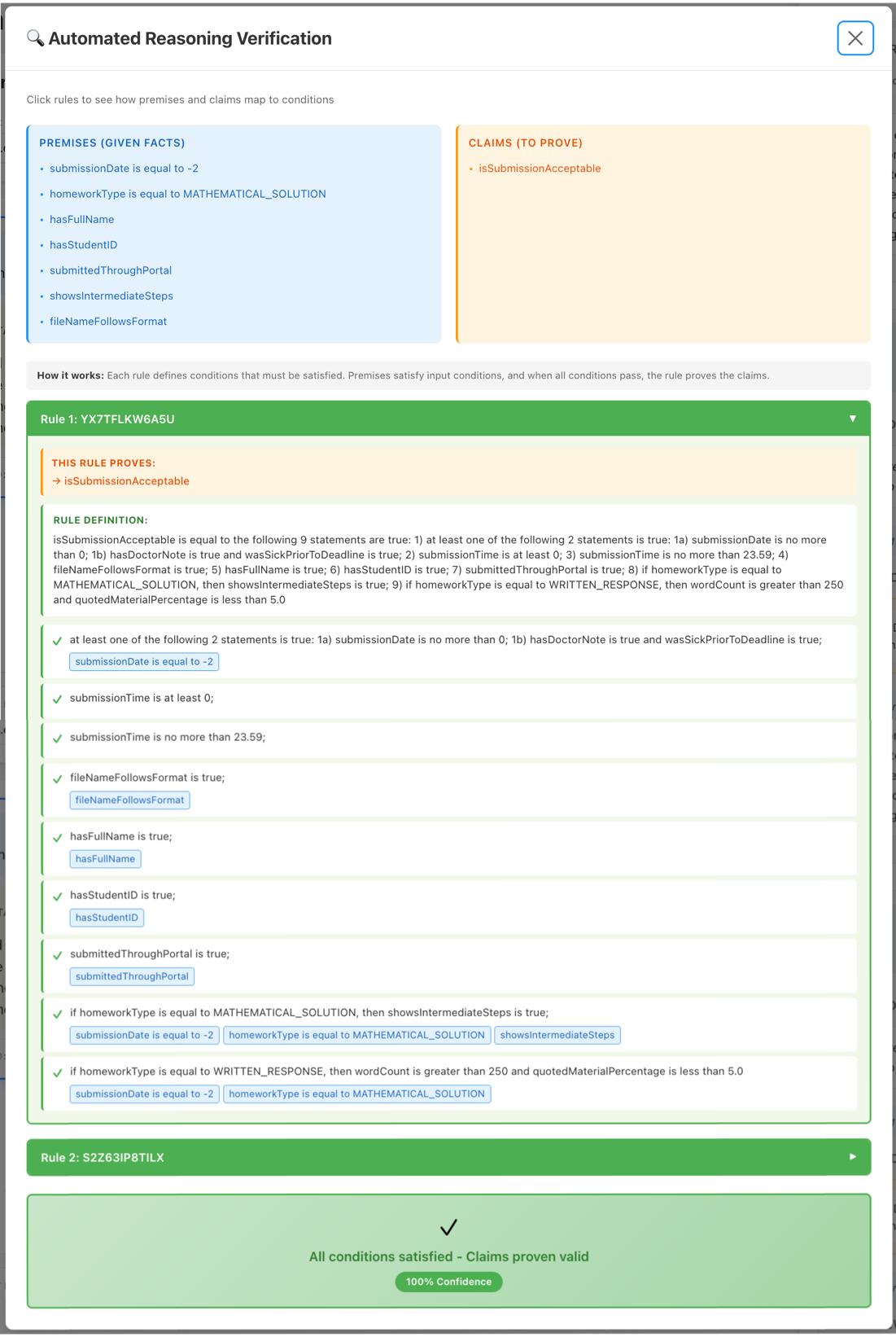
Figure 2 – Automated logic checks validity proof
How does an iterative rewrite loop work?
open source reference implementation Automated reasoning helps improve chatbot answers by repeating feedback received from probes and rewriting responses automatically. When asked to validate chatbot questions and answers (Q&A), automated reasoning checks return a list of findings. Each conclusion represents an independent logical statement identified in the input question. For example, to the question “How much does S3 storage cost? In US East (N. Virginia), S3 costs $0.023/GB for the first 50Tb; in Asia Pacific (Sydney), S3 costs $0.025/GB for the first 50Tb” the automated reasoning check will yield two conclusions, one that validates the price of S3 in US-East-1 is $0.023 is, and one for AP-Southeast-2.
When parsing a conclusion for a Q&A, automated logic checking separates the input into a list of factual premises and claims made against those premises. A base can be a factual statement in the user’s question, such as “I am an S3 user in Virginia,” or an assumption made in the answer, such as “For requests sent to us-ex-1…” An assertion represents the statement being verified. In our S3 pricing example from the previous paragraph, the region would be a base, and the price point would be a claim.
Each search includes a validation result (VALID, INVALID, SATISFIABLE, TRANSLATION_AMBIGUOUS, IMPOSSIBLE) Also feedback is necessary to rewrite the answer so that it VALID. Feedback changes based on validation results. For example, ambiguous conclusions involve two interpretations of the input text, satisfiable conclusions involve two scenarios that show how claims can be true in some cases and false in others. You can see the possible search types in our API documentation.
By removing this context, we can take a deeper look at how the context implementation works:
Initial Feedback and Verification
When the user submits a question through the UI, the application first calls the configured Bedrock LLM to generate the answer, then calls the ApplyGuardrail API to validate the question.
Using Output from Automated Reasoning Tests ApplyGuardrail response, the application enters a loop where each iteration checks the automated logic checks the feedback, takes an action such as asking the LLM to rewrite the answer based on the feedback, and then calls ApplyGuardrail To re-verify updated content.
Rewrite Loop (Heart of the System)
After initial validation, the system uses the output from the automated reasoning checks to decide the next step. First, it orders the findings by their priority – addressing the most important first: TRANSLATION_AMBIGUOUS, IMPOSSIBLE, INVALID, SATISFIABLE, VALID. Then, it selects the highest priority finding and addresses it with the logic below. since VALID is last in the priority list, the system will accept only some VALID After addressing the other findings.
- For
TRANSLATION_AMBIGUOUSAccording to the findings, the automated logic check returns two interpretations of the input text. ForSATISFIABLEIn the findings, the automated logic check returns two scenarios that prove and disprove the claims. Using the feedback, the application asks the LLM to decide whether it wants to try to rewrite the answer to clarify ambiguities or ask the user follow-up questions to gather additional information. For example,SATISFIABLEFeedback may say that the price of $0.023 is only valid if the region is US East (N. Virginia). The LLM can use this information to ask about the application area. When the LLM decides to ask follow-up questions, the loop stops and waits for the user to answer the questions, then the LLM regenerates the answers based on the explanation and the loop restarts. - For
IMPOSSIBLEIn conclusions, automated logic checking returns a list of rules that contradict the premises – accepted facts – in the input material. Using the feedback, the application asks the LLM to rewrite the answers to avoid logical inconsistencies. - For
INVALIDAccording to the findings, the automated reasoning check returns automated reasoning policy rules that invalidate claims based on the premises and policy rules. Using the feedback, the application asks the LLM to rewrite their answer so that it conforms to the rules. - For
VALIDConclusion, the application exits the loop and returns the answer to the user.
After rewriting each answer, the system sends the question and answer ApplyGuardrail API for verification; The next iteration of the loop starts with the feedback from this call. Each iteration thread stores the findings and signals in a data structure with the full context of how the system arrived at a certain answer.
Getting Started with Automated Reasoning Chatbot Rewriting Checklist
To try out our reference implementation, the first step is to create an automated logic policy:
- navigate to amazon bedrock In the AWS Management Console in one of the supported regions in the United States or European regions.
- From the left navigation, open automatic logic in the page Construction Social class.
- Using the dropdown menu make policy button, select create sample policy.
- Enter a name for the policy and then select make policy at the bottom of the page.
Once you have created a policy, you can proceed to download and run the reference implementation:
- Clone Amazon Bedrock Sample Store.
- Follow the instructions given in readme file To install dependencies, build the frontend, and start the application.
- Navigate using your favorite browser http://localhost8080 And start testing.
backend implementation details
If you plan to adapt this implementation for production use, this section discusses the key components in the backend architecture. You will find these components in backend Directory of stores.
- Thread Manager: Streamlines conversation lifecycle management. It handles the creation, retrieval, and state tracking of conversation threads, maintaining proper state during the rewriting process. The ThreadManager enforces thread-safe operations by using locks to help prevent race conditions when multiple operations attempt to simultaneously modify the same conversation. It also tracks threads waiting for user input and can identify old threads that have passed a configurable time limit.
- ThreadProcessor: Handles rewriting loops using the state machine pattern for clear, maintainable control flow. The processor manages state transitions between stages such as
GENERATE_INITIAL,VALIDATE,CHECK_QUESTIONS,HANDLE_RESULTAndREWRITING_LOOPLeading the conversation correctly through each stage. - Verification Service: IIntegrates with Amazon Bedrock Rails. This service takes each LLM-generated response and submits it for validation using
ApplyGuardrailAPI. It handles communications with AWS, manages retry logic with exponential backoff for transient failures, and parses validation results into structured findings. - LLMResponse Parser: Explains the LLM’s intentions during the rewrite cycle. When the system asks the LLM to fix an invalid response, the model must decide whether to attempt a rewrite (
REWRITE), ask clarifying questions (ASK_QUESTIONS), or declare the task impossible due to contradictory grounds (IMPOSSIBLE). The parser checks the LLM’s response to specific markers like “DECISION:“, “ANSWER:“, And “QUESTION:“, extracting structured information from natural language output. It handles Markdown formatting beautifully and enforces a limit on the number of queries (maximum 5). - AuditLogger: Writes structured JSON logs to a dedicated audit log file, recording two major event types:
VALID_RESPONSEWhen a response passes verification, andMAX_ITERATIONS_REACHEDWhen the system exhausts the specified number of retry attempts. Each audit entry captures timestamp, thread ID, prompt, response, model ID, and validation findings. The logger also extracts and records quiz exchanges from explanation iterations, including whether the user answered or skipped questions.
Together, these components help build a strong foundation for building trustworthy AI applications that combine the flexibility of large language models with the rigor of mathematical verification.
For detailed guidance on implementing automated logic checking in production:
About the authors