
Foghere AI Labs has released little nannyA family of small language models (SLM) that redefine multilingual performance. While many models scale by increasing parameters, Tiny Aya uses 3.35b-parameter Architecture to provide state-of-the-art translation and generation 70 languages.
The release includes 5 models: Chhota Aaya Base (pre-trained), Tiny Aya Global (Balanced Instruction-Tune), and three region-specific variants-Earth (Africa/West Asia), Fire (South Asia), and Water (Asia-Pacific/Europe).
architecture
Tiny AYA is built on a dense decoder-only Transformer architecture. Key specifications include:
- parameters: 3.35B total (2.8B non-embedding)
- layers:36
- vocabularyThe :262k tokenizer is designed for uniform language representation.
- Attention: Interleaved sliding window with grouped query attention (GQA) and full attention (3:1 ratio).
- Context:8192 tokens for input and output.
The model was pre-trained on 6T token Using a Warmup-Stable-Decay (WSD) schedule. The team experimented to maintain stability swigloo All bias was removed from the activation and convolution layers.
Advanced Post-Training: Fusion and SimMerge
To bridge the gap in low-resource languages, Cohere used a synthetic data pipeline.
- fusion-of-n (fusion): Signals are sent to ‘Teachers’ Team’ (Command A, GEMMA3-27B-IT, DEEPSEEK-V3). A Judge LLM, The fuserExtracts and aggregates the strongest components of their reactions.
- area expertise: Models were refined on 5 regional groups (e.g., South Asia, Africa).
- simmerge: To prevent ‘disastrous mistake’ of global security, regional checkpoints merged using global model simmergeWhich selects the best merge operators based on similarity signals.
performance benchmark
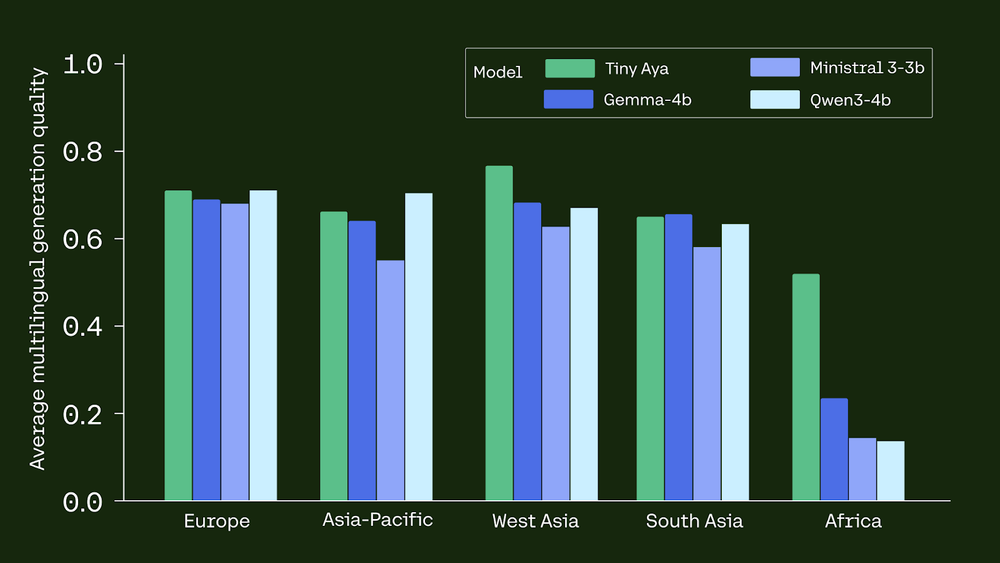
Tiny Aya Global consistently beats larger or similar level competitors in multilingual tasks:
- Translation:It performs better GEMMA3-4B In 46 out of 61 languages But WMT24++.
- logic: In globalmgsm (Mathematics) Benchmark for African languages, achieved by Tiny Aya 39.2% accuracyto be dwarf GEMMA3-4B (17.6%) and QWEN3-4B (6.25%).
- Security: It has the highest average safe response rate (91.1%) But multigel.
- linguistic integrity: Model achieves 94% language accuracyWhich means it rarely switches to English when asked to respond in another language.
On-device deployment
Tiny Aya is optimized for edge computing. using the 4-bit quantization (Q4_K_M)Model one fits 2.14 GB Memory footprint.
- iPhone 13: 10 tokens/s.
- iPhone 17 Pro: 32 tokens/s.
This quantization scheme results in minimum 1.4-point Degradable generation quality, making it a viable solution for offline, private and localized AI applications.
key takeaways
- proficient multilingual power:tiny aya is one 3.35b-parameter Model family that provides state-of-the-art translation and high-quality generation 70 languages. This proves that large scale is not required for strong multilingual performance if models are designed with intentional data curation.
- innovative training pipeline:The models were developed using an innovative strategy fusion-of-n (fusion)Where ‘a team of teachers’ (e.g. Command A and DeepSeq-V3) prepared synthetic data. A judge model then aggregates the strongest components to ensure high-quality training signals, even for low-resource languages.
- Regional specialization through mergers:Cohair releases special editions-Small came earth, fire and water-Which are designed for specific regions such as Africa, South Asia and Asia-Pacific. These were created by merging regionally refined models with global models simmerge Maintaining security while promoting local language exposure.
- Better benchmark performance: Tiny outperforms competitors like Aya Global Gemma3-4B In translation quality for 46 out of 61 languages On WMT24++. It also significantly reduces disparities in mathematical reasoning for African languages, achieving 39.2% accuracy Compared to 17.6% of Gemma3-4B.
- Optimized for on-device deployment: The model is highly portable and runs efficiently on edge devices; it achieves ~10 tokens/s More on iPhone 13 32 tokens/s Using iPhone 17 Pro Q4_K_M Quantification. This 4-bit quantization format maintains high quality with only minimal 1.4-point Degradation.
check it out technical details, paper, model weight And playground. Also, feel free to follow us Twitter And don’t forget to join us 100k+ ml subreddit and subscribe our newsletter. wait! Are you on Telegram? Now you can also connect with us on Telegram.
