
: A New Multi-Species Genomics")
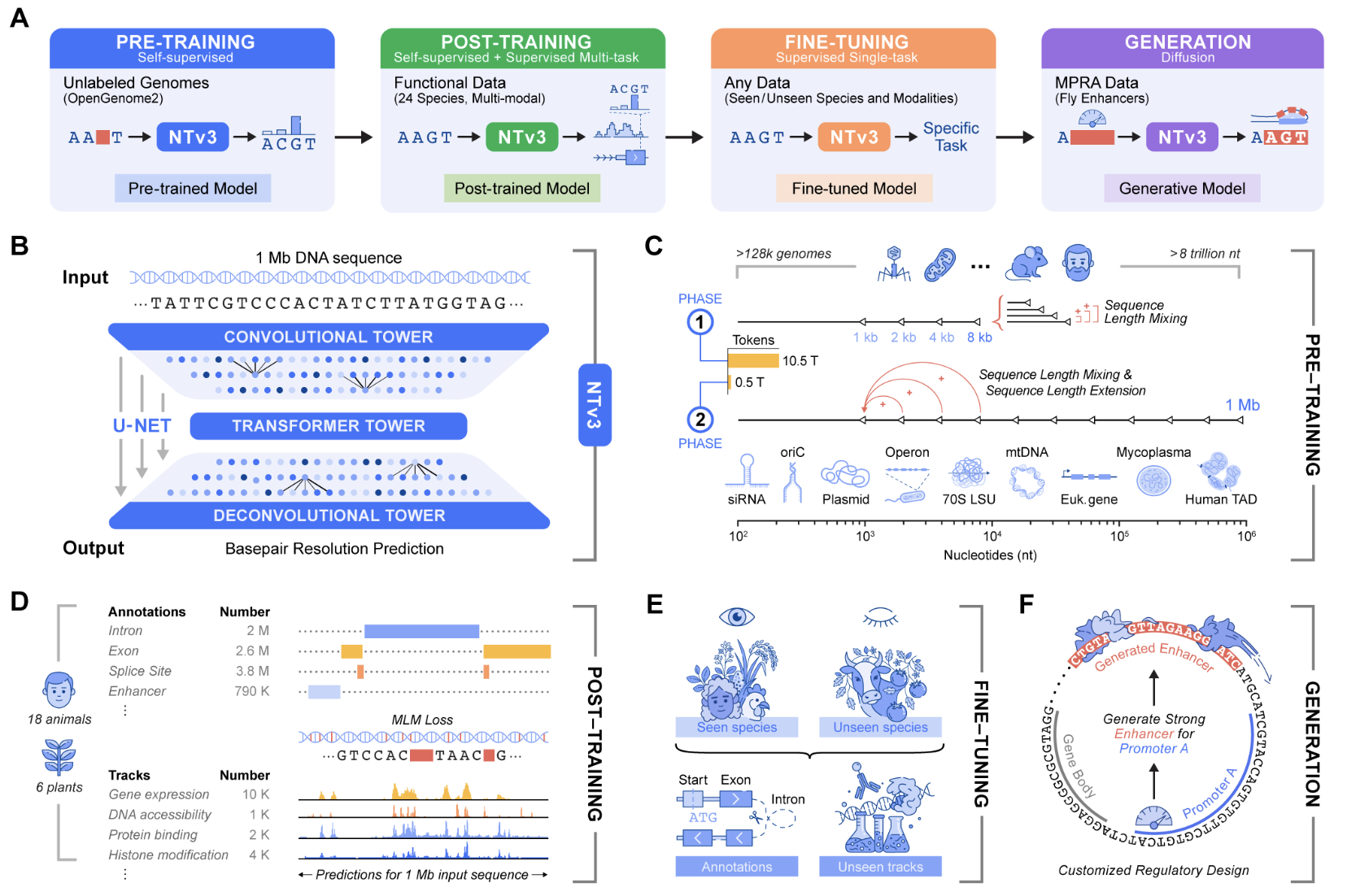
Genomic prediction and design now require models that connect local motifs to megabase scale regulatory context and that work across multiple organisms. Nucleotide Transformer v3, or NTv3, is InstaDeep’s new Multi Species Genomics Foundation model for this setting. It integrates representation learning, functional track and genome annotation prediction, and controllable sequence generation into a single backbone that runs on 1 Mb contexts at single nucleotide resolution.
Earlier nucleotide transformer models had already shown that self-supervised pre-training on thousands of genomes provides robust features for molecular phenotype prediction. The original series included models with 50M to 2.5B parameters trained on 3,200 human genomes and 850 additional genomes from different species. NTv3 keeps this sequence-only pre-training idea but extends it to longer contexts and adds explicit functional supervision and a generative mode.
Architecture for a 1 MB genomic window
NTv3 uses a U-Net style architecture that targets very long genomic windows. A convolutional downsampling tower compresses the input sequence, a transformer stack models long-range dependencies in that compressed space, and a deconvolution tower restores the base level resolution for prediction and generation. Input is tokenized at character level with special tokens like A, T, C, G, N
The smallest public model, NTv3 8M Pre, has about 7.69M parameters with hidden dimension 256, FFN dimension 1,024, 2 transformer layers, 8 attention heads, and 7 downsample stages. At the high end, NTv3 uses 650M hidden dimension 1,536, FFN dimension 6,144, 12 transformer layers, 24 attention heads and 7 downsample stages, and adds conditioning layers for species specific prediction heads.
training data
The NTv3 model is pre-trained on 9 trillion base pairs from the OpenGenome2 resource using base resolution masked language modeling. After this stage, the model is trained with a combined objective that integrates continuous self-supervision with supervised learning on approximately 16,000 functional tracks and annotation labels from 24 animal and plant species.
Performance and Ntv3 benchmarks
After training NTv3 achieves state-of-the-art accuracy for functional track prediction and genome annotation across species. It outperforms the robust sequence of function model and previous Genomic Foundation models on existing public benchmarks and the new Ntv3 benchmark, which is defined as a controlled downstream fine tuning suite with a standardized 32 kb input window and base resolution output.
The Ntv3 benchmark currently includes 106 long-range, single nucleotide, cross assay, cross species functions. Because NTv3 sees thousands of tracks across 24 species after training, the model learns a shared regulatory grammar that transfers between organisms and assays and supports consistent long-range genomes for function inference.
From prediction to controllable sequence generation
Beyond predictability, NTv3 can be fine-tuned into a controllable generator model through masked diffusion language modeling. In this mode the model receives conditioning signals that encode the desired enhancer activity level and promoter selectivity, and it fills in the masked spans in the DNA sequence in a manner consistent with those conditions.
In experiments described in the launch materials, the team designs 1,000 enhancer sequences with specified activity and promoter specificity and validates them in vitro using STARR seq assays in collaboration with the Stark lab. The results show that these generated enhancers recover the desired order of activity levels and reach more than 2-fold improved promoter specificity compared to the baseline.
comparison table
| Dimensions | NTv3 (Nucleotide Transformer v3) | jenna-lm |
|---|---|---|
| primary goal | Integrated Multi-Species Genomics Foundation Models for Representation Learning, Function Prediction from Sequence, and Controllable Sequence Generation | A family of DNA language models for long sequences focused on transfer learning for many supervised genomic prediction tasks |
| architecture | U-net style convolutional tower, transformer stack, deconvolutional tower, single basis resolution language model, post trained version add multi species conditioning and task specific heads | BERT based encoder models with 12 or 24 layers and BigBURDER variants with shorter attention spans, further enhanced with recurrent memory transformers for longer contexts |
| parameter scale | The family spans 8M, 100M and 650M parameters | The base model has 110M parameters and the larger model has 336M parameters, including a BigBird variant at 110M |
| original reference length | Up to 1 MB input at single nucleotide resolution for both pre-trained and post-trained models | Up to about 4500 bp with 512 bp tokens for the BERT model and up to 36000 bp with 4096 tokens for the BigBird model. |
| extended reference system | Uses a U-net style convolutional tower to aggregate long-range context before the convolution layers while maintaining single basis resolution; Reference length is fixed to 1 MB in ongoing checkpoints | BigBird uses sparse attention in variants and recurrent memory transformers to expand the effective context to hundreds of thousands of base pairs. |
| tokenization | Character level tokenizer on A, T, C, G, N and special tokens; Each nucleotide is a token | BPE tokenizer on DNA that maps approximately 4500 bp to 512 tokens; Two tokenizers are used, one on T2T only and one on T2T plus 1000G SNPs plus multispecies data. |
| size of pretraining corpus | First-stage pre-training on OpenGenome2 with approximately 9 trillion base pairs from over 128000 species | Preprocessed Human T2T V2 Plus Human-only model trained on 1000 genome SNPs, approximately 480 × 10^9 base pairs Multispecies model trained on combined human and multispecies data, approximately 1072 × 10^9 base pairs |
| species coverage | Over 128000 species in pretraining and posttraining supervision from 24 animal and plant species in OpenGenome2 | Human-centric models and taxon specific models for yeast, Arabidopsis and Drosophila and multispecies models from ENSEMBL genomes |
| Supervising signals after training | Approximately 16000 functional tracks in 10 assay types and approximately 2700 tissues in 24 species, with different labels used to condition the spinal cord and train functional heads | With function specific heads at the top of the LM, many observed functions have been fine-tuned, including promoters, splice sites, Drosophila enhancers, chromatin profiles, and polyadenylation sites. |
| productive capabilities | can be finely tuned into a controllable generative model using masked diffusion language modeling, which is used to design 1000 promoter specific enhancers that achieve more than 2× increased specificity in STARR seq assays. | Primarily used as a mask language model and feature extractor, supports sequence completion via MLM but the main publication focuses on predictive tasks rather than explicit controllable sequence design. |
key takeaways
- NTv3 is a long-range, multi-species genomics foundation model: It integrates representation learning, functional track prediction, genome annotation, and controllable sequence generation in a single U Net style architecture that supports 1 Mb nucleotide resolution references across 24 animal and plant species.
- The model is trained on 9 trillion base pairs with combined self-supervised and supervised objectives: NTv3 is pre-trained on 9 trillion base pairs from OpenGenome2 with base resolution masked language modeling, then trained on over 16,000 functional tracks and annotation labels from 24 species using a joint objective that blends continuous self-supervision with supervised learning.
- NTv3 achieves state-of-the-art performance on Ntv3 benchmark: After training, NTV3 reaches state-of-the-art accuracy for functional track prediction and genome annotation across species and outperforms previous sequence of function models and Genomics Foundation models on public benchmarks and the NTV3 benchmark, which consists of 106 standardized long-range downstream tasks with 32 kb input and base resolution output.
- The same backbone supports controllable enhancer designs validated with STARR seq:NTv3 can be fine-tuned as a controllable generative model using masked diffusion language modeling to design enhancer sequences with specified activity levels and promoter selectivity, and these designs are experimentally validated with STARR seq assays that confirm the desired activity ordering and improved promoter specificity.
check it out repo, Model on HF And technical detailsAlso, feel free to follow us Twitter And don’t forget to join us 100k+ ml subreddit and subscribe our newsletterwait! Are you on Telegram? Now you can also connect with us on Telegram.
Asif Razzaq Marktechpost Media Inc. Is the CEO of. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. Their most recent endeavor is the launch of MarketTechPost, an Artificial Intelligence media platform, known for its in-depth coverage of Machine Learning and Deep Learning news that is technically robust and easily understood by a wide audience. The platform boasts of over 2 million monthly views, which shows its popularity among the audience.