

Kyutai has released hibiki-zeroA new model for simultaneous speech-to-speech translation (S2ST) and speech-to-text translation (S2TT). The system translates the source speech into the target language in real time. It handles non-monotonic term dependencies during the process. Unlike previous models, Hibiki-Zero does not require word-level aligned data for training. This eliminates a major barrier to scaling AI translation into more languages.
Traditional approaches rely on supervised training with word-level alignment. It is difficult to collect these alignments on a large scale. Developers typically rely on synthetic alignment and language-specific heuristics. Hibiki-Zero overcomes this complexity by using a novel reinforcement learning (RL) strategy to optimize latency.
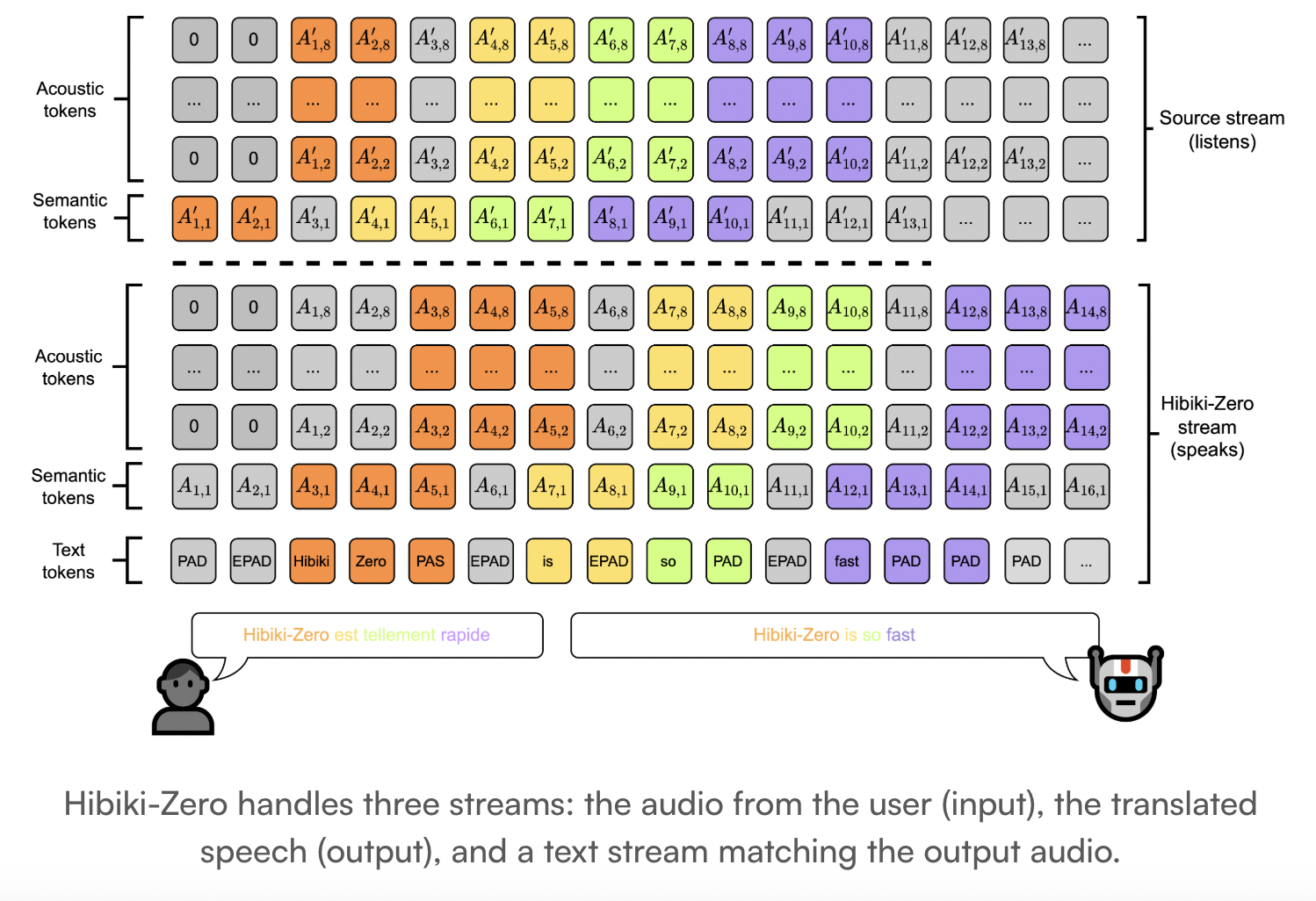
a multistream architecture
Hibiki-Zero is a decoder-only model. It uses a multistream architecture to jointly model sequences of tokens. The model handles 3 distinct streams:
- source stream:audio tokens from input speech.
- target stream: Generated audio tokens for translated speech.
- internal monologue: A stream of padded text tokens that match the target audio.
uses the system mm Neural audio codec. mm is a reason and streaming codec that encodes waveforms into separate tokens. It works at a framerate of 12.5Hz. Model one uses RQ-transformer To model these audio streams.
Architectural specifications include:
- Total Parameters: 3B.
- temporal transformer: 28 layers with latent dimension of 2048.
- depth transformer: 6 layers per codebook with latent dimension of 1024.
- context window: 4 minutes.
- audio codebook: 16 levels for high quality speech.
Training without human interpretable data
Hibiki-Zero is trained in 2 main stages:
- coarse alignment training: The model is first trained on sentence-level aligned data. This data ensures that ith The target is the translation of sentence ith Sentence in source. The research team uses the technique of inserting artificial silence into the target speech to delay its content relative to the source.
- Reinforcement Learning (RL):uses model Group Relative Policy Optimization (GRPO) To refine your policy. This step reduces translation latency while maintaining quality.
uses RL process process award is based on BLEU Score. It calculates intermediate rewards at several points during the translation. A hyperparameter ⍺ balances the trade-off between speed and accuracy. Lower ⍺ reduces latency but may reduce quality slightly.
Scaling into Italian in record time
The researchers demonstrated how easily Hibiki-Zero acquires new languages. They added Italian as an input language using less than 1000h of speech data.
- They performed supervised fine-tuning following the GRPO process.
- The model reached the same quality and latency trade-off as Meta uninterrupted Sample.
- It outperformed the Seamless in speaker parity by several fold. 30 points.
Performance and results
Hibiki-Zero 5 achieves state-of-the-art results in X-to-English tasks. It was tested on audio-ntrex-4l Long-form benchmark, covering 15 hours of speech per TTS system.
| metric | Hibiki-Zero (French) | seamless (french) |
| ASR-Blue (↑) | 28.7 | 23.9 |
| Speaker similarity (↑) | 61.3 | 44.4 |
| Average Lag (LAAL) (↓) | 2.3 | 6.2 |
In short-form tasks (Europaarl-ST), Hibiki-Zero reached ASR-BLEU 34.6 with a gap of 2.8 seconds. Human evaluators gave the model significantly higher scores than the baseline for naturalness of speech and voice transfer.

key takeaways
- zero aligned data requirementHibiki-Zero eliminates the need for expensive, hand-crafted word-level alignment between source and target speech, which was previously the biggest barrier to scaling simultaneous translations into new languages.
- grpo-driven latency optimization: The model uses Group Relative Policy Optimization (GRPO) and a simple reward system based only on BLEU scores to automatically learn an efficient translation policy, balancing high translation quality with low latency.
- coarse to fine training strategy: The training pipeline starts with sentence-level aligned data to teach the model base translations at high latency, followed by a reinforcement learning stage that “teaches” the model when to speak and when to listen.
- Better sound and naturalness: In benchmarking against previous state-of-the-art systems like Seamless, Hibiki-Zero achieved a 30-point lead in speaker similarity and significantly higher scores in speech naturalness and audio quality across five language tasks.
- rapid new language adaptation: The architecture is highly portable; The researchers demonstrated that Hibiki-Zero could be adapted to a new input language (Italian) with less than 1,000 hours of speech data while maintaining its original performance on other languages.
check it out paper, technical details, repo And samples. Also, feel free to follow us Twitter And don’t forget to join us 100k+ ml subreddit and subscribe our newsletter. wait! Are you on Telegram? Now you can also connect with us on Telegram.
