
: Audiovisual encoder powering")
Meta Researchers Introduce Perception Encoder Audiovisual, PEAVAs a new family of encoders for joint audio and video understanding. The model learns aligned audio, video and text representations in a single embedding space using large-scale adversarial training on approximately 100M audio video pairs with text captions.
From Perception Encoder to PEAV
Perception Encoder,PE,is the main vision stack in Meta’s Perception Model project. It is a family of encoders for images, video and audio that reach the state of the art on multiple vision and audio benchmarks using a unified contrastive pretraining recipe. PE Core outperforms SigLIP2 on image tasks and InterVideo2 on video tasks. Py Lang powers perception language models for multimodal reasoning. PE Spatial is designed for intensive prediction tasks such as detection and depth estimation.
PEAV Builds on this backbone and extends it to full audio video text alignment. In the Perception Model Repository, PE Audio Visual is listed as the branch that embeds audio, video, audio video, and text into a single joint embedding space for cross modal understanding.
Architecture, separate towers and fusion
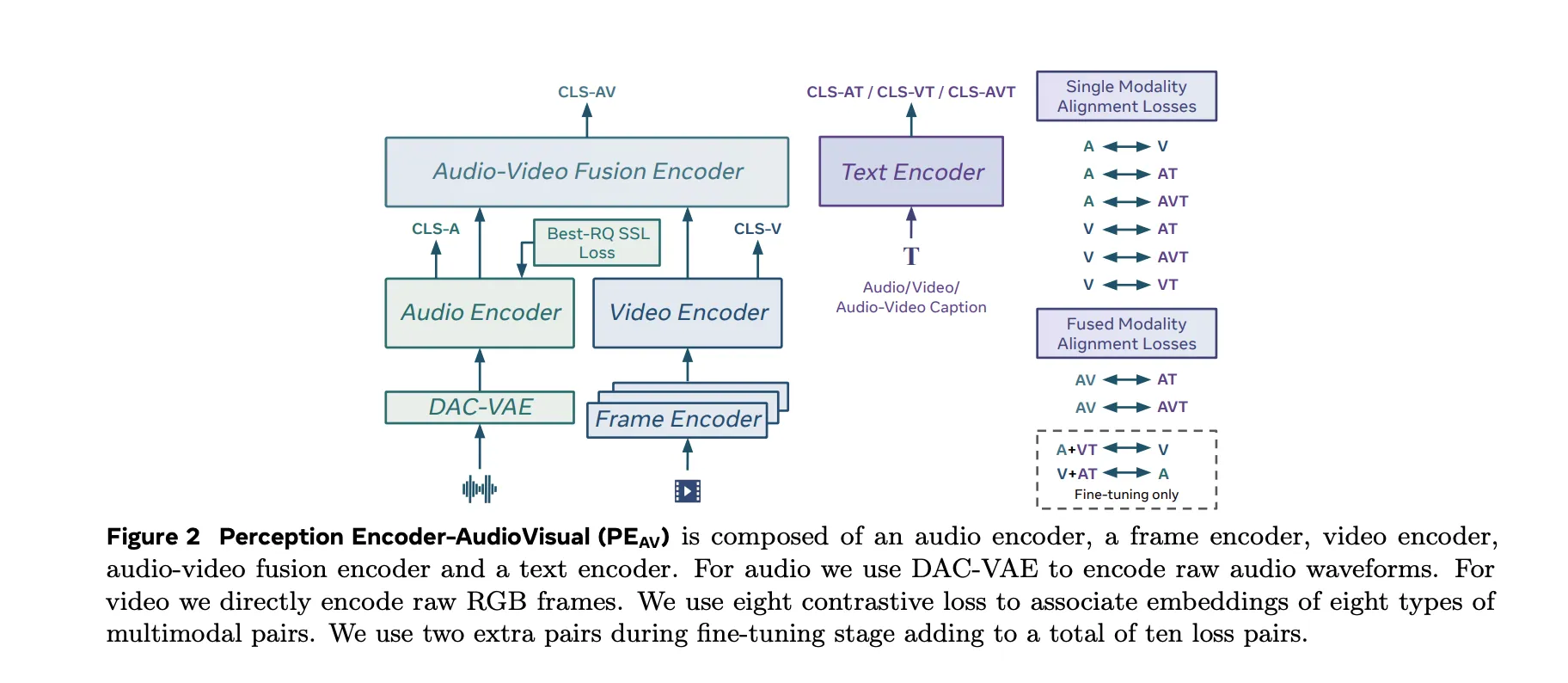
PEAV The architecture is composed of a frame encoder, a video encoder, an audio encoder, an audio video fusion encoder, and a text encoder.
- The video path uses the existing PE frame encoder on the RGB frame, then applies a temporal video encoder on top of the frame level features.
- The audio path uses a DAC VAE as a codec to convert the raw waveform into discrete audio tokens at a fixed frame rate, approximately one embedding every 40 milliseconds.
These towers feed an audio video fusion encoder that learns a shared representation for both streams. A text encoder projects text queries into several specific locations. In practice this gives you a single backbone that can be queried in multiple ways. You can get text to video, text to audio, video to audio, or retrieve text descriptions conditioned on any combination of modalities without retraining task specific heads.
Data engine, large-scale synthetic audiovisual captions
The research team proposed a two-stage audiovisual data engine that generates high-quality synthetic captions for unlabeled clips. The team describes a pipeline that first uses multiple weak audio caption models, their confidence scores, and individual video captioners as inputs to a larger language model. This LLM generates three caption types per clip, one for the audio content, one for the visual content, and one for the combined audio visual content. An initial PE AV model is trained on this synthetic supervision.
In the second phase, this initial P.E.AV It is integrated with the Perception Language Model Decoder. Together they refine the captions to make better use of the audiovisual correspondence. The two-stage engine delivers reliable captions for approximately 100M audio video pairs and uses approximately 92M unique clips for Stage 1 pretraining and an additional 32M unique clips for Stage 2 fine tuning.
Compared to previous work that often focuses on speech or narrow sound domains, this corpus is designed to balance speech, general sound, music, and diverse video domains, which is important for general audiovisual retrieval and comprehension.
Contradictory Objectives in Ten Modality Pairs
PEAV Uses sigmoid based contrastive loss in audio, video, text and fused representations. The research team explains that the model uses eight adversarial loss pairs during pretraining. These cover combinations such as audio text, video text, audio video text and fusion related pairs. During fine tuning, two additional pairs are added, bringing the total to ten loss pairs between different modalities and caption types.
This objective is similar to the contrast objectives used in recent vision language encoders but generalized to audio video text tri-modal training. By aligning all these sequences in one place, a single encoder can support classification, retrieval, and correspondence tasks with simple dot product similarity.
Display in audio, speech, music and video
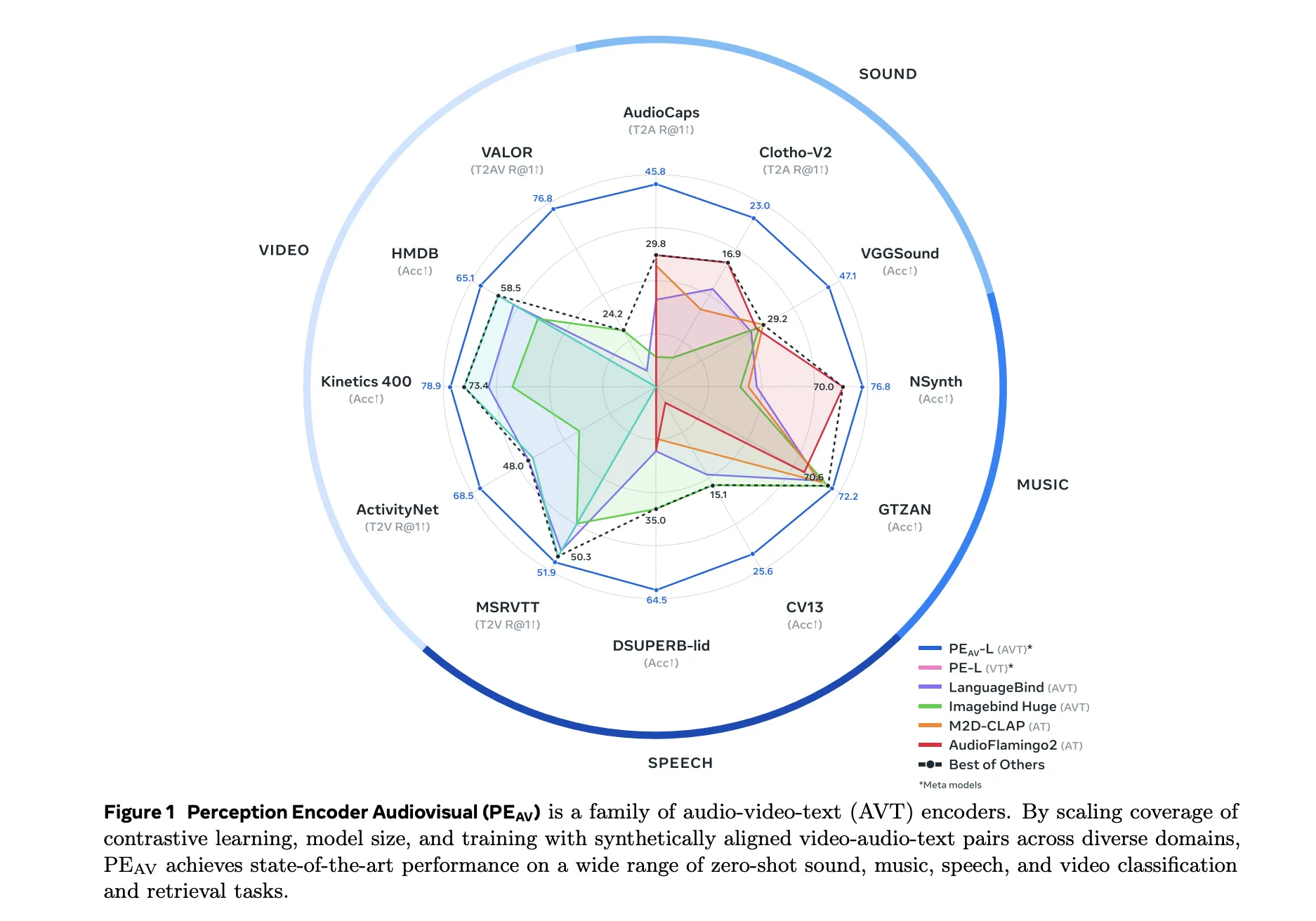
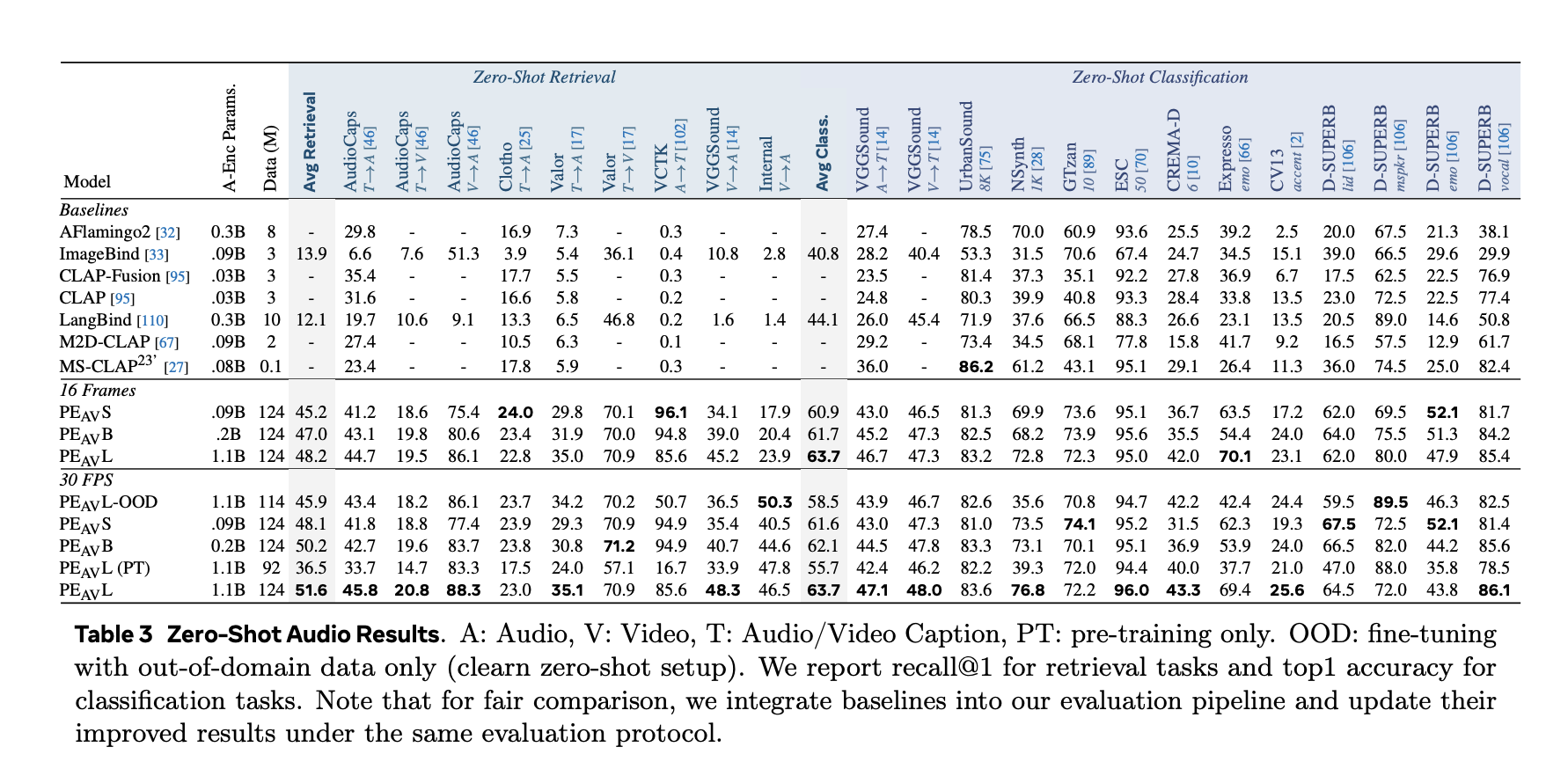
On benchmark, PEAV Target zero shot retrieval and classification for multiple domains. PE AV achieves state-of-the-art performance on multiple audio and video benchmarks compared to recent audio text and audio video text models such as CLAP, Audio Flamingo, ImageBind and LanguageBind.
Concrete benefits include:
- On AudioCaps, audio retrieval from text increases from 35.4 R at 1 to 45.8 R at 1.
- On VGGSound, clip level classification accuracy increased from 36.0 to 47.1.
- For speech retrieval on VCTK style tasks, the PE AV reaches 85.6 accuracy while earlier models are closer to 0.
- On ActivityNet, text-to-video retrieval increases from 60.4 R at 1 to 66.5 R at 1.
- On the Kinetics 400, the zero shot video classification has increased from 76.9 to 78.9, outperforming the larger model by 2 to 4 times.
PEframeframe level audio text alignment
along with PEAVMeta releases Perception Encoder Audio Frame, PEframeFor sound event localization. PE A frame is an audio text embedding model that outputs one audio embedding per 40 millisecond frame and one text embedding per query. The model can return temporal spans that mark where each described event in the audio occurs.
PEframe Uses frame level contrastive learning to align audio frames with text. This enables precise localization of events such as specific speakers, instruments, or transient sounds in long audio sequences.
Perception models and SAM’s role in the audio ecosystem
PEAV and peframe Sit inside the comprehensive Perception Model stack, which connects the PE Encoder with the Perception Language Model for multimodel generation and reasoning.
PEAV It is also the main perception engine behind Meta’s new SAM audio model and its Judge evaluator. SAM uses audio PEAV Embedding to connect visual cues and text cues to sound sources in complex mixes and score the quality of separate audio tracks.
key takeaways
- PEAV There is a unified encoder for audio, video, and text, trained with contrastive learning on over 100M videos, and embeds audio, video, audio video, and text into a single joint space for cross modal retrieval and understanding.
- The architecture uses separate video and audio towers with PE based visual encoding and DAC VAE audio tokenization, followed by an audio visual fusion encoder and specialized text heads associated with different modality pairs.
- The Stage 2 data engine generates synthetic audio, visual and audio visual captions using weak captioners and LLM in Stage 1 and PE.AV Plus perception language models in phase 2, enabling large-scale multimodal supervision without manual labels.
- PEAV With six public checkpoints ranging from small 16 frame to large all frame variants, it sets new state of the art on a wide range of audio and video benchmarks through a sigmoid contrastive objective on multiple modality pairs, where the average retrieval improves from approximately 45 to 51.6.
- PEAVframe level with PEframe The variant forms the perception backbone for Meta’s SAM audio system, providing instantiation based audio separation and fine embeddings used for fine sound event localization in speech, music and general sounds.
check it out paper, repo And model weightAlso, feel free to follow us Twitter And don’t forget to join us 100k+ ml subreddit and subscribe our newsletterwait! Are you on Telegram? Now you can also connect with us on Telegram.
Asif Razzaq Marktechpost Media Inc. Is the CEO of. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. Their most recent endeavor is the launch of MarketTechPost, an Artificial Intelligence media platform, known for its in-depth coverage of Machine Learning and Deep Learning news that is technically robust and easily understood by a wide audience. The platform boasts of over 2 million monthly views, which shows its popularity among the audience.