

Automatic speech recognition (ASR) is becoming a core building block for AI products ranging from meeting tools to voice agents. Mistral is new Voxtral Transcribe 2 The family targets this space with 2 models that are clearly divided into batch and realtime use cases while taking into account cost, latency, and deployment constraints.
Releases include:
- Voxtral Mini Transcribe V2 For batch transcription with diarization.
- Voxtral Realtime (Voxtral Mini 4B Realtime 2602) Released as open source, for low-latency streaming transcription.
Designed for both models 13 languages: English, Chinese, Hindi, Spanish, Arabic, French, Portuguese, Russian, German, Japanese, Korean, Italian and Dutch.
Model families: batch and streaming, with explicit roles
Mistral positions Voxtral Transcribe 2 as ‘two next-generation speech-to-text models’ State-of-the-art transcription quality, diarization, and ultra-low latency.
- Voxtral Mini Transcribe V2 Is batch model. It is optimized for transcription quality and diarization across domains and languages and is demonstrated as an efficient audio input model in the Mistral API.
- voxtral realtime Is streaming model. It is built with a dedicated streaming architecture and released under an open-source model Apache 2.0 On the hugging face, with the recommended VLLM runtime.
A key description: Speaker diarization is provided by Voxtral Mini Transcribe V2Not by Voxtral Realtime. RealTime focuses strictly on fast, accurate streaming transcription.
Voxtral Realtime: 4B-Parameter Streaming ASR with Configurable Delay
Voxtral Mini 4B Realtime 2602 there is one 4B-Parameter Multilingual Realtime Speech-Transcription Model. It is one of the first open-weight models to reach accuracy comparable to offline systems with a delay of less than 500 ms.
architecture:
- ≈3.4b-parameter language model.
- ≈0.6B-parameter audio encoder.
- Audio Encoder is trained from scratch causal focus.
- Both encoder and LM are used Sliding-Window MeditationEffectively enabling “infinite” streaming.
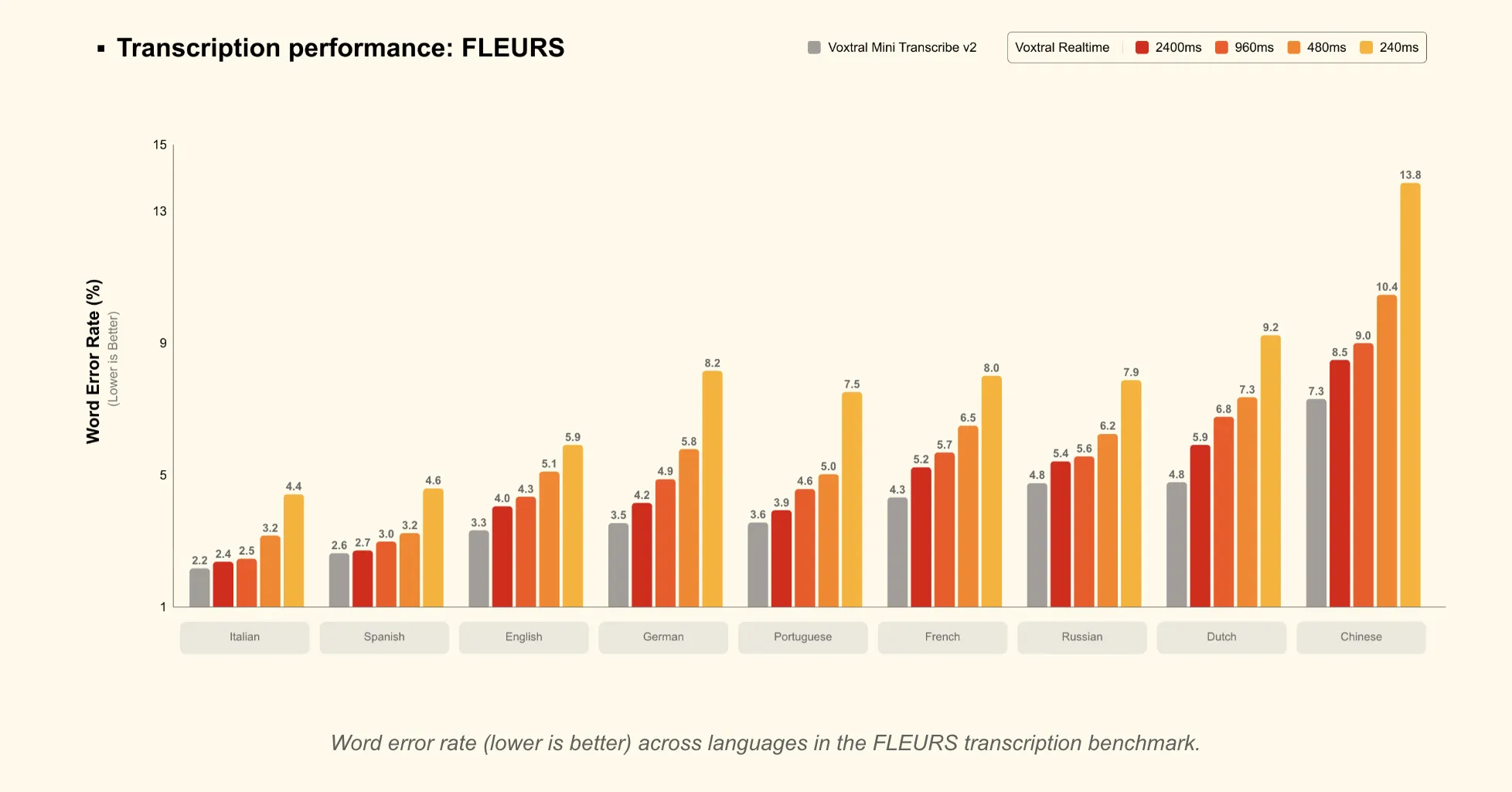
Latency vs accuracy is explicitly configurable:
- Transcription delay is tunable from 80 ms to 2.4 seconds through a
transcription_delay_msParameters. - Mistral describes latency as “Configurable down to 200 ms” For live applications.
- But 480 ms delayRealTime matches leading offline open-source transcription models and realtime APIs on benchmarks such as FLEURS and Long-Form English.
- But 2.4 second delayrealtime match Voxtral Mini Transcribe V2 On FLEURS, which is suitable for subtitling work where slightly higher latency is acceptable.
From a deployment perspective:
- Model has been released BF16 and is designed for Deploy on-device or at the edge.
- It can run in real time Single GPU with ≥16GB memoryAs per VLLM serving instructions in model card.
The main control knob is the delay setting:
- Low latency (≈80-200 ms) for interactive agents where responsiveness dominates.
- nearby 480 ms As the recommended “sweet spot” between latency and accuracy.
- High latency (up to 2.4 seconds) when you need accuracy as close as possible to the batch model.
Voxtral Mini Transcribe V2: Batch ASR with diarization and reference bias
Voxtral Mini Transcribe V2 is a closed-weight audio input model Adapted only for transcription. It is exposed in the Mistral API as voxtral-mini-2602 But $0.003 per minute.
On benchmarks and pricing:
- nearby 4% word error rate (WER) Average across the top 10 languages, on the FLEURS transcription benchmark.
- “The best price-performance of any transcription API” At $0.003/min.
- performs better GPT-4o Mini Transcribe, gemini 2.5 flash, assembly universalAnd Deepgram Nova On the accuracy of their comparisons.
- processes audio ≈3× faster than ElevenLabs Scribe v2 When matching quality one fifth of the cost.
Enterprise-oriented features are concentrated in this model:
- speaker diarization
- Outputs speaker labels with accurate start and end times.
- Designed for meetings, interviews and multi-party calls.
- For overlapping speech, the model typically emits a single speaker label.
- context bias
- accepts up to 100 words or phrases Biasing transcription toward specific names or domain terms.
- adapted to English, with experimental support For other languages.
- word-level timestamp
- Per-word start and end timestamps for subtitles, alignment, and searchable audio workflows.
- noise intensity
- Maintains accuracy in noisy environments such as factory floors, call centers, and field recordings.
- long audio support
- handles up to 3 hours of audio in a single request.
Language coverage mirrors Realtime: 13 languages, with Mistral noting that non-English performance “far surpasses competitors” in their assessment.
API, tooling and deployment options
The integration paths are straightforward and differ little between the two models:
- Voxtral Mini Transcribe V2
- Served via Mistral Audio Transcription API (
/v1/audio/transcriptions) as an efficient transcription-only service. - at cost $0.003/minute. (Mistral AI)
- available in Mistral Studio’s Audio Playground and in le chat For interactive testing.
- Served via Mistral Audio Transcription API (
- voxtral realtime
- Available via Mistral API $0.006/minute.
- Released as loose weight on a hugging face (
mistralai/Voxtral-Mini-4B-Realtime-2602) under Apache 2.0, with official VLLM realtime support.
Audio Playground in Mistral Studio lets users:
- upload to 10 audio files up to (.mp3, .wav, .m4a, .flac, .ogg) 1 GB Everyone.
- Toggle diarization, choose timestamp granularity, and configure reference bias conditions.
key takeaways
- Two-ideal family with clear roles: Voxtral Mini Transcribe V2 targets batch transcription and diarization, while Voxtral RealTime targets low-latency streaming ASR in 13 languages.
- Realtime model – 4B parameters with tunable delay: Voxtral uses a 4B architecture (≈3.4B LM + ≈0.6B encoder) with realtime sliding-window and causal attention, and supports configurable transcription delay from 80 ms to 2.4 sec.
- Latency vs. accuracy trade-off is clear: At a latency of about 480 ms, Voxtral RealTime reaches accuracy comparable to stronger offline and realtime systems, and at 2.4 seconds it matches Voxtral Mini Transcribe V2 on FLS.
- Adds batch model diarization and enterprise features: Voxtral Mini Transcribe V2 provides diarization, context bias, word-level timestamps, noise robustness for up to 100 phrases, and supports up to 3 hours of audio per request at $0.003/minute.
- Deploy- closed batch API, open real-time load: Mini Transcribe v2 is served through Mistral’s audio transcription API and Playground, while Voxtral Realtime costs $0.006/min and is also available as an Apache 2.0 open source with official VLLM Realtime support.
check it out technical details And model weight. Also, feel free to follow us Twitter And don’t forget to join us 100k+ ml subreddit and subscribe our newsletter. wait! Are you on Telegram? Now you can also connect with us on Telegram.

Michael Sutter is a data science professional and holds a Master of Science in Data Science from the University of Padova. With a solid foundation in statistical analysis, machine learning, and data engineering, Michael excels in transforming complex datasets into actionable insights.
