

Can a 3B model provide the logic of a 30B range by fixing the training recipe rather than the scaling parameters? The NanBiz LLM lab at Boss Zipin has released NanBiz4-3B, a 3B parameter small language model family trained with an unusually heavy emphasis on data quality, course scheduling, distillation, and reinforcement learning.
The research team ships 2 primary checkpoints, NanBiz4-3B-Base and NanBiz4-3B-Thinking, and evaluates reasoning tuned models against Quen3 checkpoints ranging from 4B to 32B parameters.
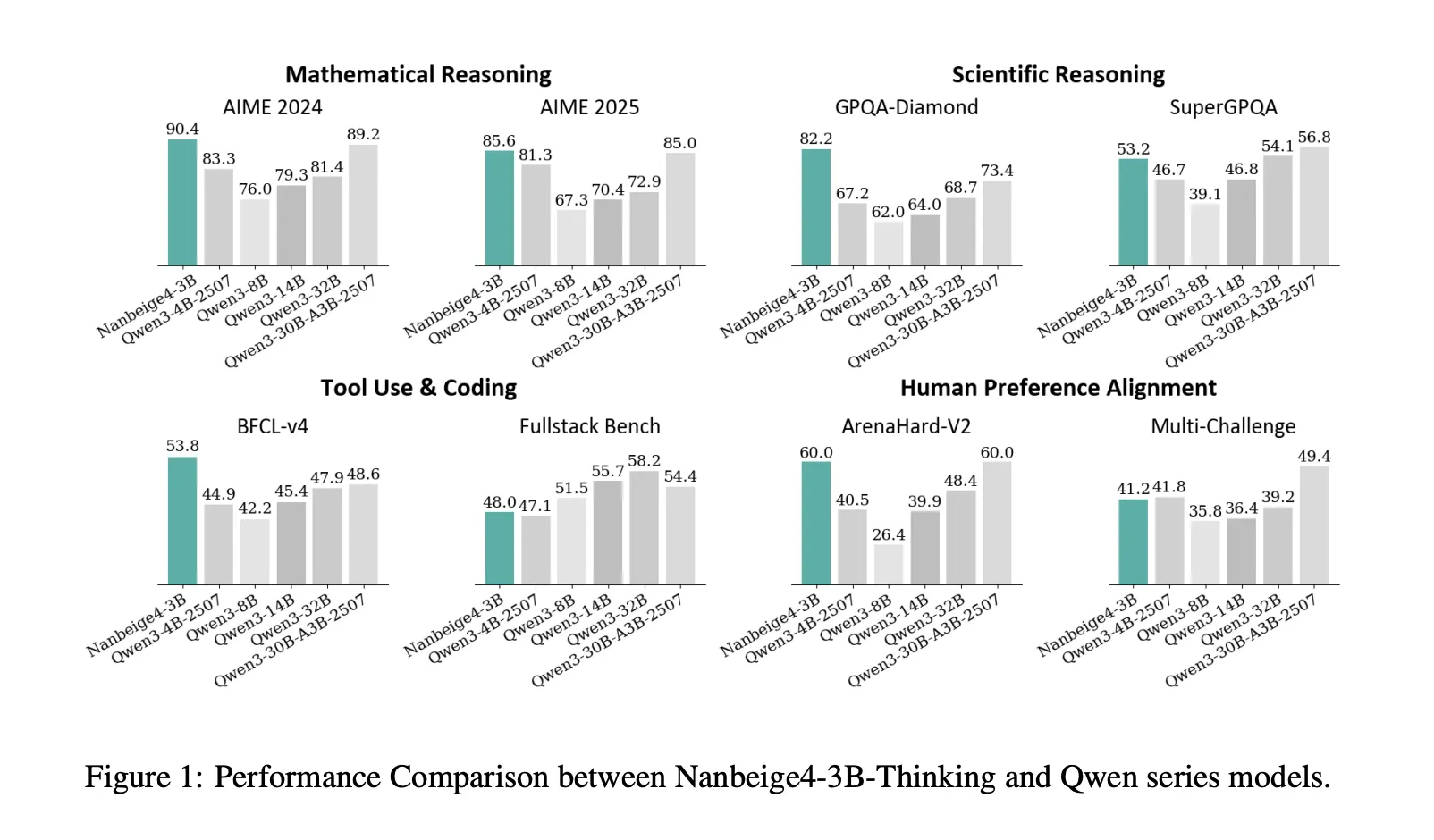
benchmark results
On AIME 2024, NanBiz4-3B-2511 reports 90.4, while Qwen3-32B-2504 reports 81.4. On GPQA-Diamond, NanBiz4-3b-2511 reports 82.2, while Quen3-14b-2504 reports 64.0 and Quen3-32b-2504 reports 68.7. These are 2 benchmarks where the “3B beats 10× bigger” framing of the research is directly supported.
The research team also demonstrated strong device utilization advantage over BFCL-v4, with NanBiz4-3b reporting 53.8 versus 47.9 for Qwen3-32b and 48.6 for Qwen3-30b-A3b. On Arena-Hard v2, NanBiz4-3b reports 60.0, which matches the highest score listed in that comparison table inside the research paper. Also, the model is not the best in every category, on fullstack-bench it reports 48.0, slightly below qwen3-14b at 55.7 and qwen3-32b at 58.2, and on SuperGPQA it reports 53.2, slightly below qwen3-32b at 54.1.

Training recipe, parts that transfer to 3B model
Hybrid data filtering, then mass resampling
For pre-training, the research team combines multidimensional tagging with similarity-based scoring. They reduce their labeling space to 20 dimensions and report 2 key findings, content-related labels are more predictable than format labels, and a granular 0 to 9 scoring scheme outperforms binary labeling. For similarity-based scoring, they create a retrieval database with hundreds of billions of entries supporting hybrid text and vector retrieval.
They filter 12.5T tokens of high quality data, then select a 6.5T high quality subset and upsample it for 2 or more epochs, generating a final 23T token training corpus. This is the first place where the report diverges from typical small model training, the pipeline is not just “clean data”, it is scored, retrieved and resampled with explicit utility assumptions.
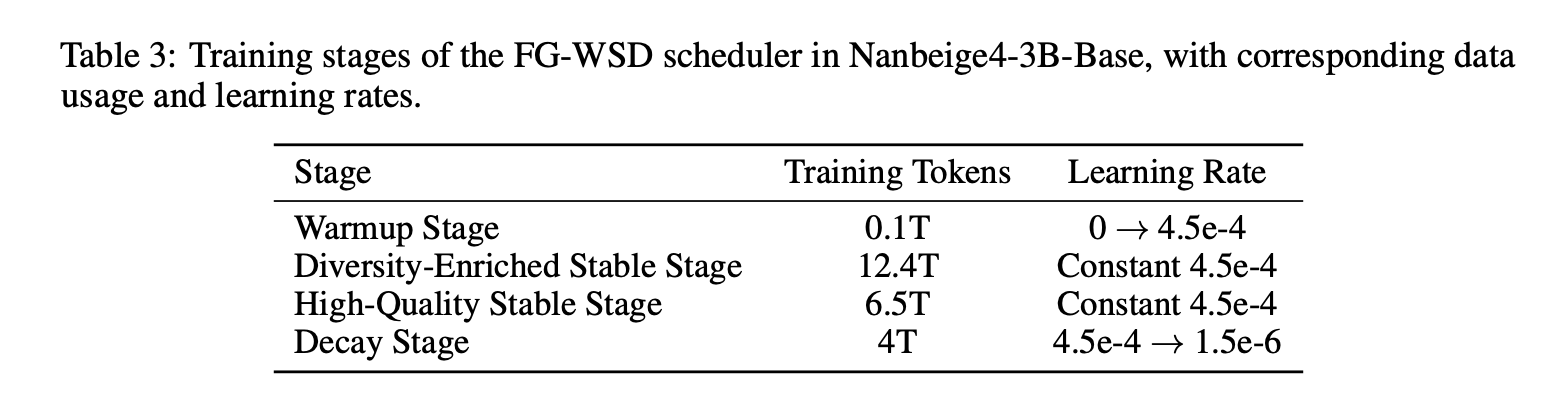
FG-WSD, a data utilization scheduler instead of uniform sampling.
Most similar research projects consider the warmup constant decay only as a learning rate schedule. NanBiz4-3B FG-WSD adds a data course inside the stationary phase via fine-grained warmup-stable-decay. Instead of sampling a fixed mixture during static training, they focus on progressively higher quality data in subsequent training.

In 1B ablation trained on 1T tokens, the above table shows GSM8K improving from 27.1 under vanilla WSD to 34.3 under FG-WSD, with gains in CMATH, BBH, MMLU, CMMLU and MMLU-Pro. In the full 3B run, the research team divides the training into warmup, diversity-rich stable, high-quality stable, and decay, and uses ABF in the decay stage to increase the reference length to 64K.
Multi-stage SFT, then fix supervised traces
After training starts with cold start SFT, then overall SFT. The cold start phase uses approximately 30M QA samples focused on math, science, and code, with a 32K context length, and a reported mix of approximately 50% math logic, 30% scientific logic, and 20% code tasks. The research team also claims that scaling cold start SFT instructions from 0.5M to 35M continues to improve AIME 2025 and GPQA-Diamond, with no early saturation in their experiments.
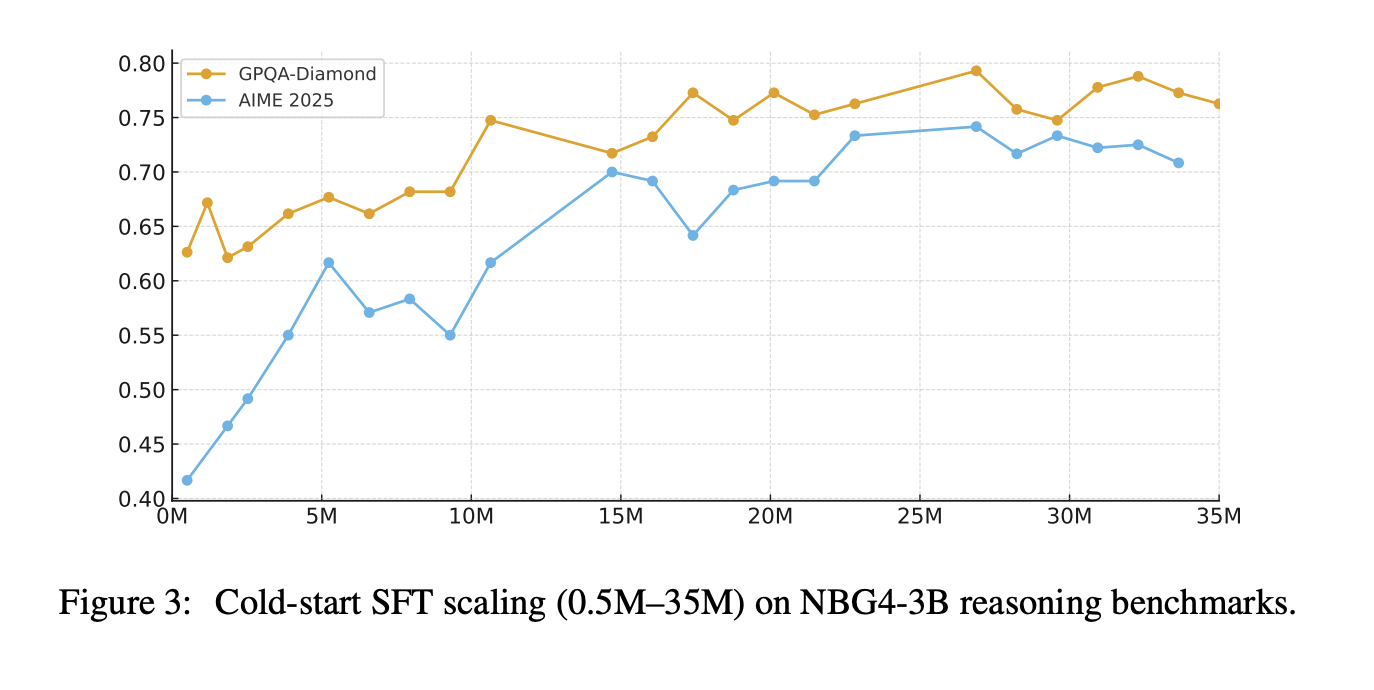
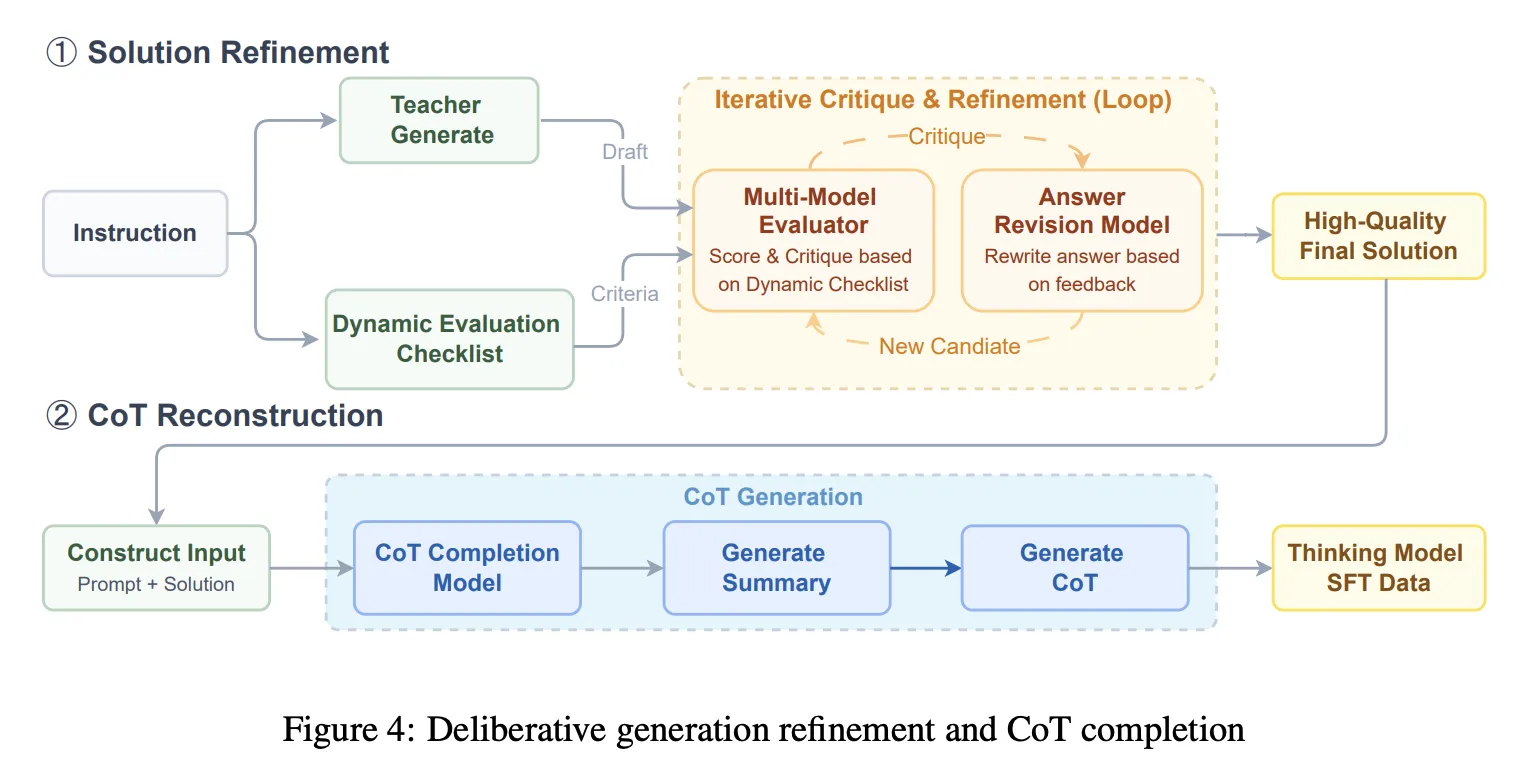
Overall the SFT turns out to be a 64K reference length mix including general conversation and writing, agent style tool use and planning, difficult reasoning targeting vulnerabilities, and coding tasks. This phase introduces solution refinement and chain-of-thought reconstruction. The system runs iterative generate, criticize, modify cycles guided by a dynamic checklist, then uses a chain completion model to reconstruct a coherent COT that is consistent with the final refined solution. The purpose is to avoid training on broken arguments after heavy editing.
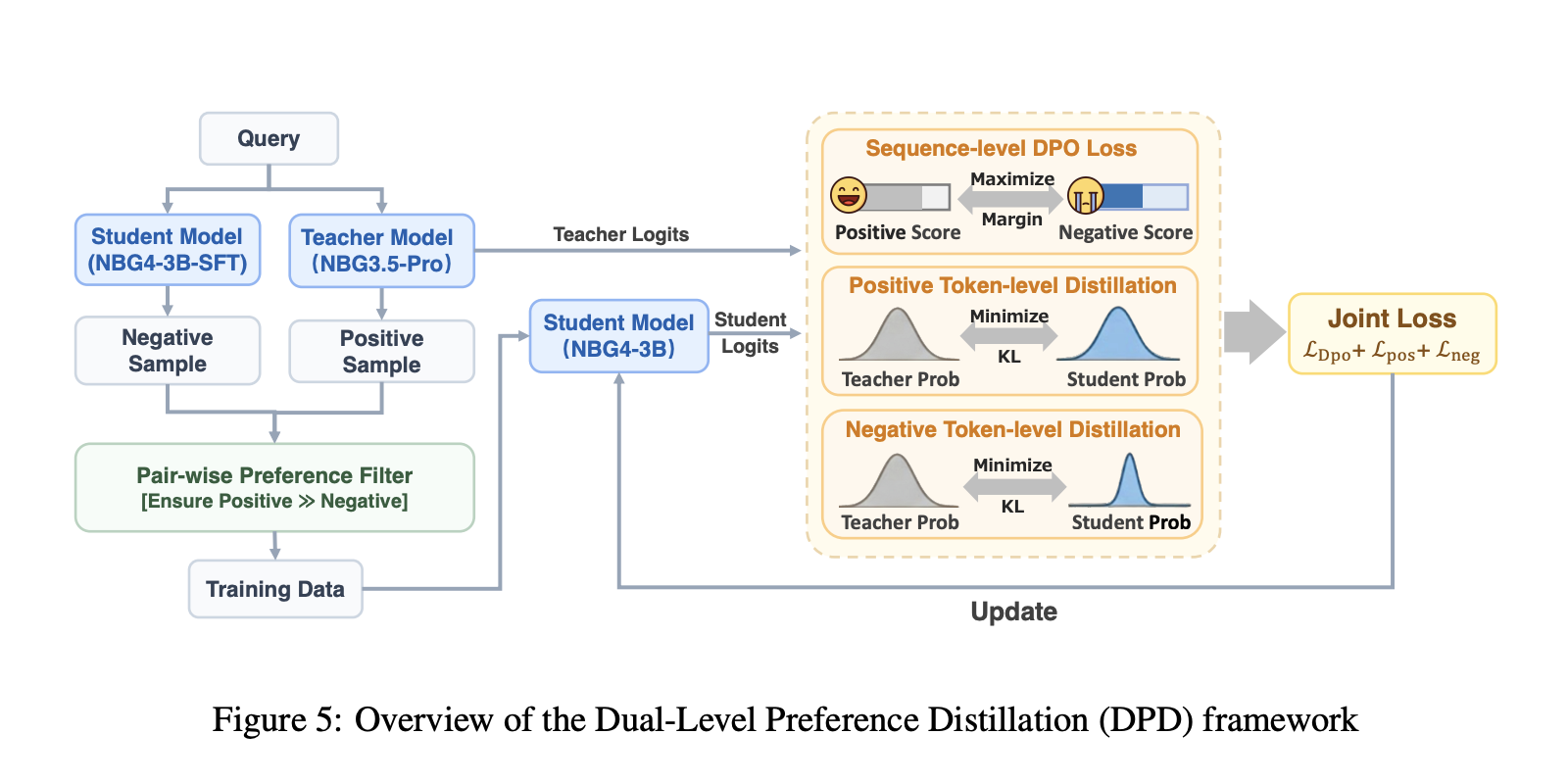
DPD distillation, then multi stage RL with validators
Distillation uses dual-stage preferential distillation, DPD. The student teacher learns token level distributions from the model, while the sequence level DPO objective is to maximize the difference between positive and negative responses. The positives come from the teacher Nanbeez3.5-Pro sample, the negatives are taken from the 3B student, and distillation is applied to both sample types to reduce confidence errors and improve the choices.
Reinforcement learning is staged by domain, and each stage uses the policy GRPO. The research team describes a data filtering policy using an avg@16 pass rate to avoid trivial or impossible objects and strictly maintaining samples between 10% and 90%. STEM RL uses an agentic validator that calls a Python interpreter to check equivalence beyond string matching. Coding RL uses synthetic test functions, validated through sandbox execution, and uses pass fail rewards from those tests. Human Preference Alignment RL uses a pairwise reward model that is designed to generate preferences across certain tokens and reduce reward hacking risk compared to ordinary language model rewarders.
comparison table
| benchmark, metric | QUEN3-14B-2504 | QUEN3-32B-2504 | Nanbeez4-3B-2511 |
|---|---|---|---|
| AIME2024,Avg@8 | 79.3 | 81.4 | 90.4 |
| AIME2025,Avg@8 | 70.4 | 72.9 | 85.6 |
| GPQA-Diamond, avg@3 | 64.0 | 68.7 | 82.2 |
| SuperGPQA, Average@3 | 46.8 | 54.1 | 53.2 |
| BFCL-V4, Avg@3 | 45.4 | 47.9 | 53.8 |
| fullstack bench, avg@3 | 55.7 | 58.2 | 48.0 |
| arenahard-v2, avg@3 | 39.9 | 48.4 | 60.0 |
key takeaways
- The average sampling setup of the paper can lead to much larger open models on the 3B argument. NanBiz4-3b-Thinking reports AIME 2024 AVG@8 90.4 vs Qwen3-32b 81.4, and GPQA-Diamond AVG@3 82.2 vs Qwen3-14b 64.0.
- The research team is careful about the evaluation, these are avg@k results with specific decoding, not single shot accuracy. AIME is avg@8, most others are avg@3, with temp 0.6, peak P 0.95, and long max generation.
- The benefit of pretraining is tied to the data curriculum, not just more tokens. Fine-grained WSD schedules a higher quality mix later, and 1B ablation shows GSM8K moving from 27.1 to 34.3 versus vanilla scheduling.
- After training the focus is on supervised quality, then conscious distillation is preferred. The pipeline uses chain-of-thought reconstruction along with deliberate solution refinement, then dual preference distillation that combines token distribution matching with sequence level preference optimization.
check it out paper And model weightFeel free to check us out GitHub page for tutorials, code, and notebooksAlso, feel free to follow us Twitter And don’t forget to join us 100k+ ml subreddit and subscribe our newsletterwait! Are you on Telegram? Now you can also connect with us on Telegram.

Michael Sutter is a data science professional and holds a Master of Science in Data Science from the University of Padova. With a solid foundation in statistical analysis, machine learning, and data engineering, Michael excels in transforming complex datasets into actionable insights.
