

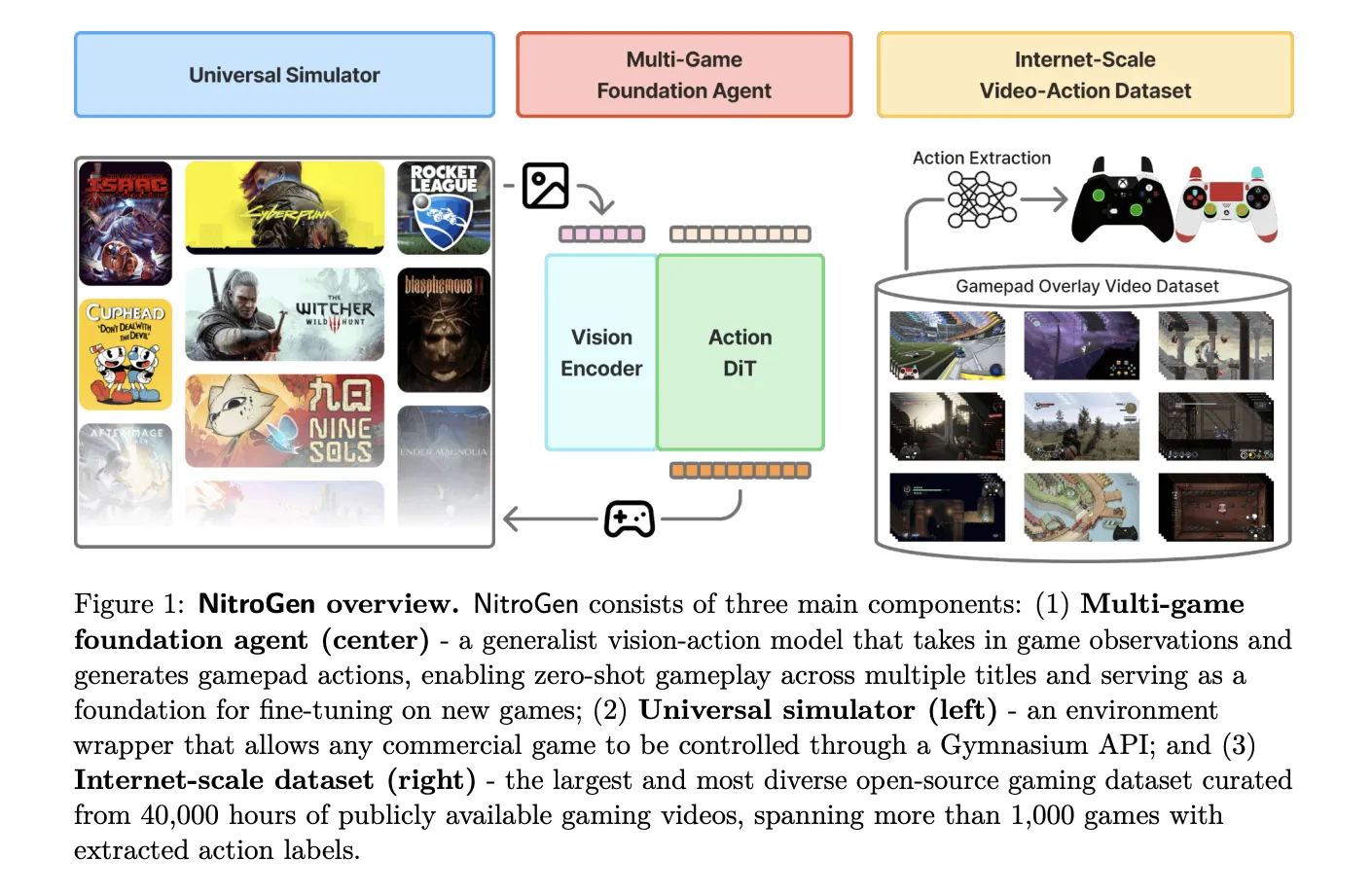
The NVIDIA AI research team released Nitrogen, an open vision action foundation model for generalist gaming agents that learns to play professional games directly from pixel and gamepad actions using large-scale Internet videos. Nitrogen has been trained on 40,000 hours of gameplay in over 1,000 games and comes with an open dataset, a universal simulator, and a pre-trained policy.
Internet Scale Video Action Dataset
The Nitrogen pipeline starts with publicly available gameplay videos that include input overlays, for example gamepad visualizations that streamers place in a corner of the screen. The research team collected 71,000 hours of raw video with such overlays, then applied quality filtering based on action density, which left 55% of the data, about 40,000 hours, spanning more than 1,000 games.
The curated dataset contains 38,739 videos from 818 creators. The distribution includes a wide range of titles. There are 846 games with more than 1 hour of data, 91 games with more than 100 hours of data, and 15 games with more than 1,000 hours of data. Action RPGs account for 34.9 percent of hours, platformers account for 18.4 percent, and action adventure titles account for 9.2 percent, with the remainder spread across sports, roguelikes, racing, and other genres.
To recover frame level actions from raw streams, Nitrogen uses a three-stage action extraction pipeline. First, a template matching module localizes the controller overlay using approximately 300 controller templates. For each video, the system samples 25 frames and matches SIFT and XFeat features between the frame and the template, then estimates an affine transform when at least 20 inliers support a match. This yields a crop of the controller region for all frames.
Second, a Segformer based hybrid classification parses the segmentation model controller crops. The model takes two consecutive frames spatially combined and outputs joystick locations on an 11 by 11 grid plus binary button positions. It is trained on 8 million synthetic images provided with different controller templates, opacity, size and compression settings using AdamW with learning rate 0.0001, weight decay 0.1 and batch size 256.
Third, the pipeline refines the joystick position and filters out segments with low activity. Joystick coordinates are normalized to a range of -1.0 to 1.0 using the 99th percentile of absolute x and y values to reduce outliers. The chunks that contain non-null actions in less than 50 percent of the timesteps are removed, thereby avoiding predicting null actions during policy training.
A separate benchmark with ground truth controller logs shows that joystick predictions reach an average R² of 0.84 and button frame accuracy reaches 0.96 across major controller families like Xbox and PlayStation. This confirms that automated annotations are accurate enough for large-scale behavioral cloning.
Universal Simulator and Multi Game Benchmark
NitroGen includes a universal simulator that wraps commercial Windows games into a Gymnasium compatible interface. The wrapper intercepts the game engine system clock to control simulation timing and supports frame by frame interactions without modifying game code, for any title that uses the system clock for physics and interactions.
Observations in this benchmark are single RGB frames. The actions are defined as a unified controller space with a 16 dimensional binary vector for the gamepad buttons, four D pad buttons, four face buttons, two shoulders, two triggers, two joystick thumb buttons, start and back, as well as a 4 dimensional continuous vector for the joystick positions, left and right x,y. This integrated layout allows direct transfer of a policy across multiple games.
The evaluation suite includes 10 business games and 30 tasks. There are 5 two-dimensional games, three side scrollers and two top-down roguelikes, and 5 three-dimensional games, two open world games, two combat focused action RPGs and one sports title. The tasks come in 11 combat tasks, 10 navigation tasks and 9 game specific tasks with custom objectives.
nitrogen model architecture
The Nitrogen Foundation policy follows the GR00T N1 architecture pattern for embedded agents. It removes the language and state encoders, and keeps a vision encoder and a single action head. The input is an RGB frame at 256 by 256 resolution. A SigLIP 2 vision transformer encodes this frame into 256 image tokens.
A diffusion transformer, the DIT, generates 16 phase portions of future activity. During training, noisy action segments are embedded into action tokens by a multilayer perceptron, processed by a stack of DIT blocks with cross attention on self-attention and visual tokens, then decoded into continuous action vectors. The training objective is conditional flow matching with 16 denoising steps on each 16 action segments.
The released checkpoint has 4.93 × 10^8 parameters. The model describes the card output as a 21 by 16 tensor, where 17 dimensions correspond to binary button positions and 4 dimensions store two two-dimensional joystick vectors at 16 future timesteps. This representation corresponds to a unified action space, up to reshaping of the joystick components.
Training results and transfer benefits
Nitrogen is trained entirely on Internet video datasets with large-scale behavioral cloning. The base model has no reinforcement learning and no reward design. Image enhancements include random brightness, contrast, saturation, hue, small rotations, and random crops. Training uses AdamW with weight decay 0.001, a warmup constant decay learning rate schedule with a constant phase at 0.0001, and an exponential moving average of weights with decay 0.9999.
After pre-training on the entire dataset, NitroGen 500M already achieves non-trivial task completion rates in zero shot evaluation across all games in the benchmark. Despite noise in Internet observation, average completion rates remain around 45 percent to 60 percent for combat, navigation, and game specific tasks, and in two-dimensional and three-dimensional games.
To transfer to unseen games, the research team holds a title, pre-trains on the remaining data, and then focuses on the games held under a certain data and calculates the budget. On an isometric roguelike, fine tuning with Nitrogen gives an average relative improvement of about 10 percent compared to training from scratch. On three-dimensional action RPGs, the average gain is about 25 percent, and for some combat tasks in a low data regime, say 30 hours, the relative improvement reaches 52 percent.
key takeaways
- Nitrogen is a generalist vision action foundation model for sports: It maps 256×256 RGB frames directly onto standardized gamepad actions and is trained with pure behavior cloning on Internet gameplay, without any reinforcement learning.
- The dataset is large-scale and automatically labeled from the controller overlay:Nitrogen uses 40,000 hours of filtered gameplay from 38,739 videos in over 1,000 games, where frame level activities are extracted from the view controller overlay using a Segformer based parsing pipeline.
- Integrated controller enables action space cross game transfer:Actions are represented in a shared space of approximately 20 dimensions per timestep, consisting of binary gamepad buttons and continuous joystick vectors, allowing the same policy to be deployed across multiple commercial Windows games using a universal gymnasium style simulator.
- Diffusion Transformer Policy with Conditional Flow Matching: 4.93 × 10^8 parameter model uses a Siglip2 vision encoder plus a DIT based action head trained with conditional flow matching on 16 step action chunks, achieving robust control from noisy web scale data.
- Pretraining on nitrogen improves downstream game performance: When fine-tuning titles kept under the same data and compute budget, nitrogen-based initialization consistently gives relative gains, averaging about 10 percent to 25 percent and up to 52 percent in low-data warfare tasks, compared to training from scratch.
check it out paper And model hereAlso, feel free to follow us Twitter And don’t forget to join us 100k+ ml subreddit and subscribe our newsletterwait! Are you on Telegram? Now you can also connect with us on Telegram.

Michael Sutter is a data science professional and holds a Master of Science in Data Science from the University of Padova. With a solid foundation in statistical analysis, machine learning, and data engineering, Michael excels in transforming complex datasets into actionable insights.