

NVIDIA researchers released PersonaPlex-7b-v1, a full-duplex speech-to-speech conversation model that targets natural voice interactions with precise persona control.
From ASR→LLM→TTS to a single full-duplex model
Traditional voice assistants typically run a cascade. Automatic speech recognition (ASR) converts speech to text, a language model generates a text response, and text-to-speech (TTS) converts back to audio. Each step adds latency, and the pipeline cannot handle overlapping speech, natural interruptions, or dense backchannels.
PersonPlex replaces this stack with a single transformer model that performs streaming speech understanding and speech generation across a network. The model works on continuous audio encoded with a neural codec and automatically predicts both text tokens and audio tokens. Incoming user audio is encoded sequentially, while PersonPlex simultaneously generates its own speech, enabling barge ins, overlaps, fast turn taking, and contextual backchannels.
PersonPlex runs in a dual stream configuration. One stream tracks the user’s audio, the other stream tracks the agent’s speech and text. Both streams share the same model state, so the agent can listen while the user is speaking and adjust its response when the user intervenes. The design is directly inspired by Kyūtai’s Moshi full-duplex framework.
Hybrid prompting, voice control and role control
PersonPlex uses two prompts to define conversational identity.
- A voice prompt is a sequence of audio tokens that encode vocal characteristics, speaking style, and prosody.
- The text prompt describes the role, background, organization information, and scenario context.
Together, these signals constrain both the linguistic content and the acoustic behavior of the agent. On top of that, a system prompt supports fields like name, business name, agent name, and business information along with a budget of up to 200 tokens.
Architecture, helium backbone and audio path
The PersonPlex model has 7B parameters and follows the Moshi network architecture. A MM speech encoder that combines ConvNet and Transformer layers converts waveform audio into discrete tokens. The temporal and depth transformers process multiple channels representing user audio, agent text, and agent audio. A MM speech decoder that also combines Transformer and ConvNet layers generates the output audio tokens. Uses a 24 kHz sample rate for both audio input and output.
PersonaPlex is built on Moshi’s weight and usage helium The underlying language model as the backbone. Helium provides semantic understanding and enables generalization outside of supervised conversation scenarios. This is visible in the ‘space emergency’ example, where a prompt about reactor core failure on a Mars mission leads to a coherent technical argument with an appropriate emotional tone, even though this situation is not part of the training delivery.
Mixing training data, real conversations and synthetic roles
The training consists of 1 phase and uses a mixture of real and synthetic dialogues.
The actual conversations in the Fisher English Corpus come from 7,303 calls, approximately 1,217 hours. These conversations are back annotated with signals using GPT-OSS-120B. The prompts are written at different granularity levels, ranging from simple personality prompts like ‘You enjoy good conversation’ to longer descriptions that include life history, location, and preferences. This repository provides natural backchannels, confusion, pauses and emotional patterns that are difficult to achieve with TTS alone.
Synthetic data covers assistant and customer service roles. The NVIDIA team reports 39,322 synthetic support conversations, about 410 hours, and 105,410 synthetic customer service conversations, about 1,840 hours. Qwen3-32B and GPT-OSS-120B generate transcripts, and Chatterbox TTS converts them to speech. For supportive interactions, the text prompt was set as ‘You are an intelligent and friendly teacher’. Answer questions or give advice in a clear and engaging way.’ For customer service scenarios, prompts encode structured business rules such as organization, role type, agent name, and pricing, hours, and constraints.
This design allows PersonaPlex to reconcile natural conversational behavior, which comes primarily from Fisher, with task adherence and role conditioning, which comes primarily from synthetic scenarios.
Evaluation on FullDuplexBench and ServiceDuplexBench
PersonPlex is evaluated on FullDuplexBench, a benchmark for full-duplex spoken dialogue models, and on a new extension called ServiceDuplexBench for customer service scenarios.
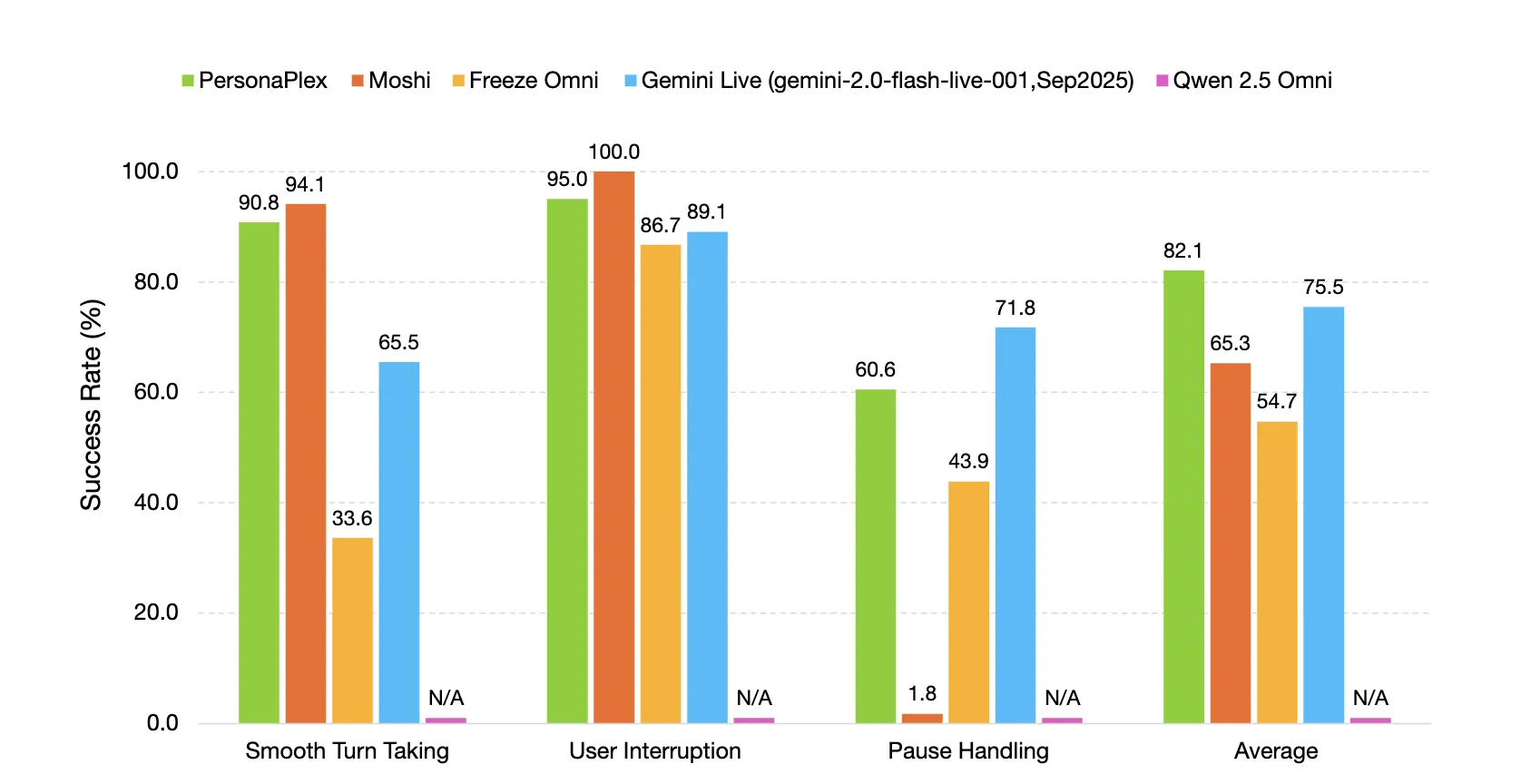
FullDuplexBench measures interaction dynamics with takeover rate and latency metrics for tasks such as smooth turn taking, user interruption handling, pause handling, and backchanneling. GPT-4o acts as an LLM judge for response quality in question answer categories. PersonPlex reaches the smooth curve taking TOR 0.908 with a latency of 0.170 seconds and TOR 0.950 with a latency of 0.240 seconds. The speaker similarity between sound signals and output on the user interference subset uses the WavLM TDNN embedding and reaches 0.650.
PersonaPlex outperforms many other open source and closed systems on conversational mobility, response latency, interruption latency and task adherence in both assistant and customer service roles.
key takeaways
- Personplex-7b-v1 is NVIDIA’s 7b parameter full-duplex speech-to-speech conversational model, built on the Moshi architecture with the Helium language model backbone, coded under MIT, and weights under the NVIDIA Open Model License.
- The model uses a dual stream transformer with mm speech encoder and decoder at 24 kHz, it encodes continuous audio into separate tokens and generates text and audio tokens at the same time, enabling barge ins, overlaps, fast turn taking and natural backchannel.
- Persona control is handled by hybrid prompting, with a voice prompt composed of audio tokens setting the timing and style, a text prompt and a system prompt of up to 200 tokens defining roles, business context and constraints, with ready-made voice embeddings such as the NATF and NATM families.
- The training uses a mixture of 7,303 Fisher conversations, approximately 1,217 hours, annotated with GPT-OSS-120B, as well as synthetic assistant and customer service dialogues, approximately 410 hours and 1,840 hours, respectively, generated with Qwen3-32B and GPT-OSS-120B and presented with Chatterbox TTS, which separates the naturalness of the conversation from task adherence.
- On FullDuplexBench and ServiceDuplexBench, PersonaPlex reaches smooth turn takeover rate of 0.908 and user interruption takeover rate of 0.950 with sub-second latency and better task adherence.
check it out technical details, model weight And repo. Also, feel free to follow us Twitter And don’t forget to join us 100k+ ml subreddit and subscribe our newsletter. wait! Are you on Telegram? Now you can also connect with us on Telegram.
Asif Razzaq Marktechpost Media Inc. Is the CEO of. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. Their most recent endeavor is the launch of MarketTechPost, an Artificial Intelligence media platform, known for its in-depth coverage of Machine Learning and Deep Learning news that is technically robust and easily understood by a wide audience. The platform boasts of over 2 million monthly views, which shows its popularity among the audience.