

Serving large language models (LLMs) at scale is a major engineering challenge due to key-value (KV) cache management. As models grow in size and logic capacity, the KV cache footprint grows and becomes a major bottleneck to throughput and latency. For modern transformers, this cache can occupy several gigabytes.
NVIDIA researchers have introduced KVTC (KV Cache Transform Coding). This lightweight transform coder compresses KV cache for compact on-GPU and off-GPU storage. is achieved up to 20x Compression while maintaining logic and long-reference accuracy. For specific use cases, it can reach 40x or higher.
Memory dilemma in LLM estimation
In production, inference frameworks treat the local KV cache like a database. Strategies such as prefix sharing promote cache reuse to speed up responses. However, older caches consume scarce GPU memory. Developers are currently facing a difficult choice:
- Keep Cash: Occupies memory needed by other users.
- Discard cache: Bears high cost of recalibration.
- Offload the cache: The CPU moves the data to DRAM or SSDs, causing transfer overhead.
KVTC This dilemma has been substantially mitigated by reducing the cost of on-chip retention and reducing the bandwidth required for offloading.

How does the KVTC pipeline work??
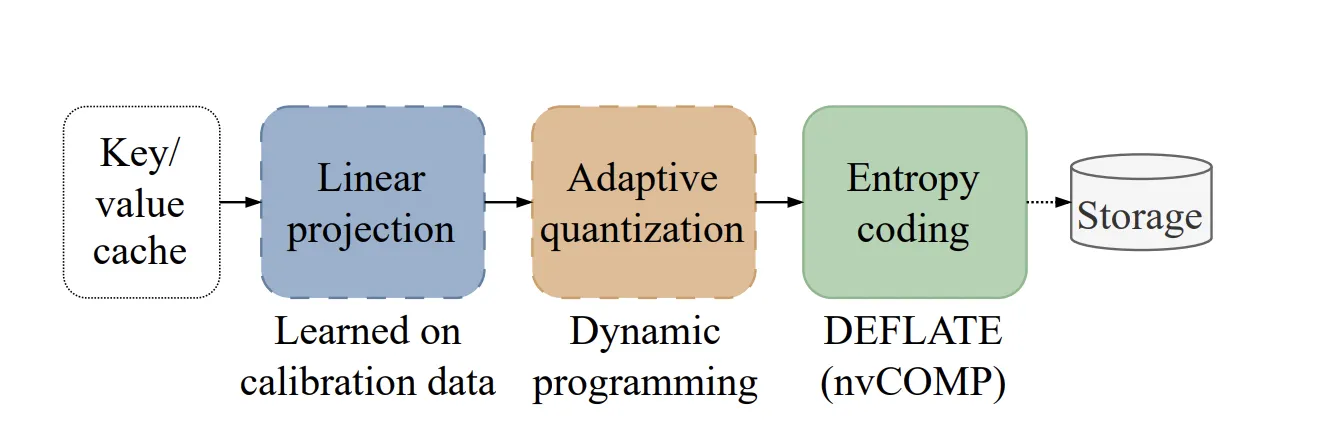
This method is inspired by classical media compression. It applies a learned orthonormal transform, followed by adaptive quantization and entropy coding.
1. Feature Decoration (PCA)
Different attention peaks often show similar patterns and a high degree of correlation. KVTC Uses Principal Component Analysis (PCA) to linearly concatenate features. Unlike other methods, which compute a separate decomposition for each prompt, KVTC PCA calculates the basis matrix V Once on the calibration dataset. This matrix is reused at inference time for all future caches.
2. Adaptive Quantization
The system exploits PCA order to allocate a fixed bit budget to the coordinates. High-variance components receive more bits, while others receive fewer bits. KVTC Uses a dynamic programming (DP) algorithm to find the optimal bit allocation that minimizes reconstruction error. The important thing is that DP often assigns 0 bits Leaving key components behind, allowing initial dimensionality reduction and faster performance.
3. Entropy Coding
Quantized symbols are packed and compressed using to spray Algorithm. To maintain momentum, KVTC takes advantage of nvCOMP Library, which enables parallel compression and decompression directly on the GPU.
Protecting key tokens
Not all tokens are compressed equally. KVTC avoids compressing two specific types of tokens because they contribute disproportionately to attention accuracy:
- Attention Sync: 4 Oldest tokens in order.
- sliding window: 128 Most recent tokens.
Ablation studies show that compressing these specific tokens can significantly reduce or even collapse accuracy at high compression ratios..
Benchmarks and Efficiency
The research team tested KVTC With models like Llama-3.1, Mistral-NEMO, and R1-Qwen-2.5.
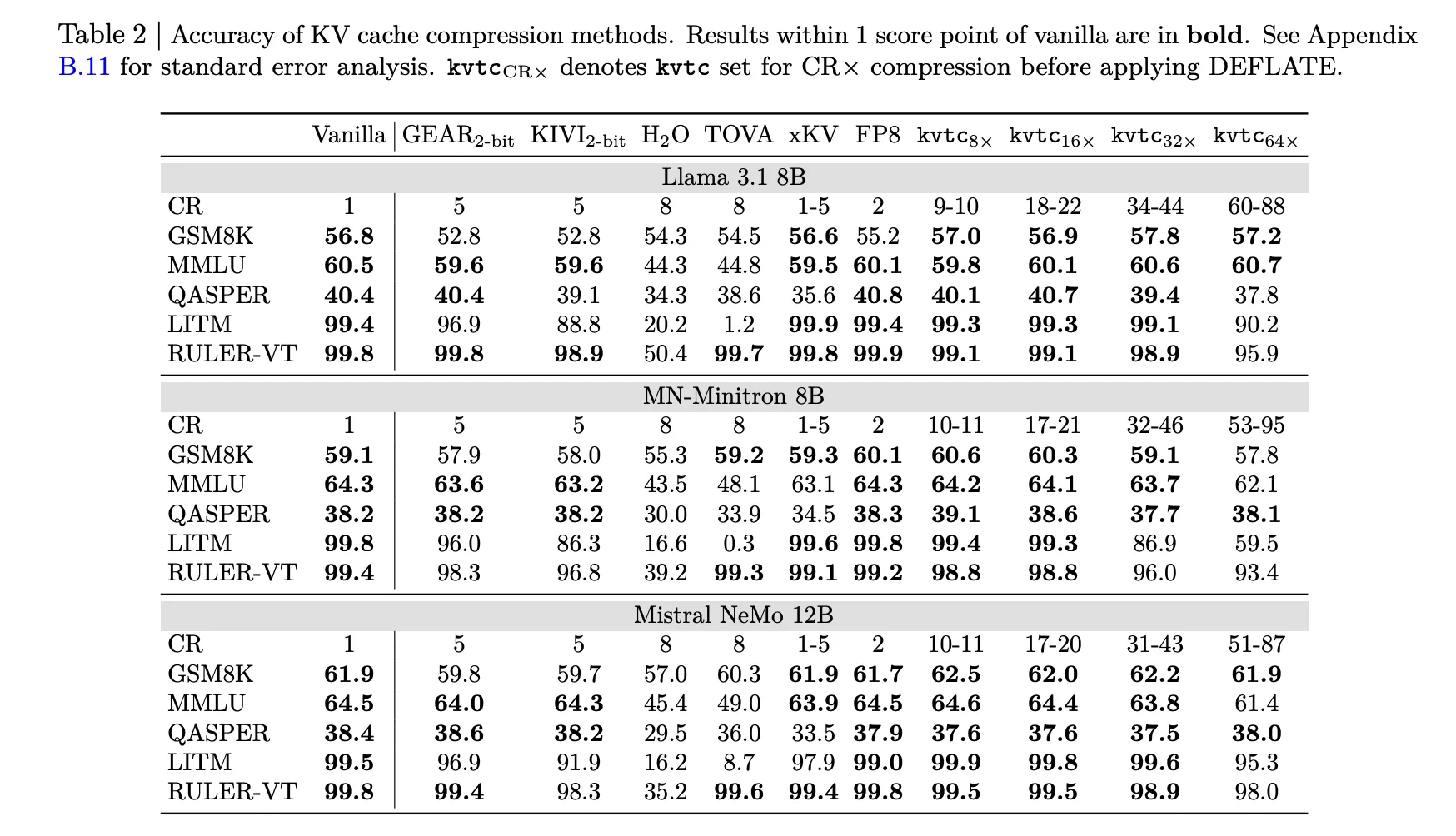
- accuracy: But 16x Compression (roughly) 20x After DEFLATE), the model maintains consistent results 1 Score points of the vanilla model.
- Reduction in TTFT: for one 8K reference length, kvtc Can reduce time-to-first-token (TTFT) by up to 8x Than a full recalculation.
- pace: calibration is fast; For 12B models, this can be accomplished within 10 Minutes on NVIDIA H100 GPU.
- Storage Overhead: The additional data stored per model is small, representing only 2.4% Model parameters for Lama-3.3-70B.
KVTC Memory-efficient LLM is a practical building block for service. This model does not modify the weights and is directly compatible with other token removal methods.
key takeaways
- High compression with low accuracy loss: KVTC achieves a standard 20x Compression ratio while maintaining results 1 digit digit Vanilla (uncompressed) models in most logic and long-context benchmarks.
- Transform Coding Pipeline: This method uses a pipeline inspired by classical media compression, combining PCA-based feature decoration, adaptive quantization through dynamic programming, and lossless entropy coding (Deflate).
- Important token security: To maintain model performance, KVTC avoids compressing 4 The oldest ‘attention sink’ tokens and a ‘sliding window’ 128 Most recent tokens.
- operating efficiency: The system is ‘tuning-free’, requiring only a brief initial calibration (under 10 minutes 12b) which leaves the model parameters unchanged and adds only minimal storage overhead. 2.4% For 70B model.
- Significant latency reduction: By reducing the amount of data stored and transferred, KVTC Can reduce time-to-first-token (TTFT) by up to 8x Than a full recalculation of the KV cache for long references.
check it out paper here. Also, feel free to follow us Twitter And don’t forget to join us 100k+ ml subreddit and subscribe our newsletter. wait! Are you on Telegram? Now you can also connect with us on Telegram.
