

Large context windows have dramatically increased how much information modern language models can process in a single prompt. With models capable of handling hundreds of thousands or even millions of tokens, it is easy to assume that recovery-augmented generation (RAG) is no longer necessary. Why create a recovery pipeline if you can fit the entire codebase or documentation library into a context window?
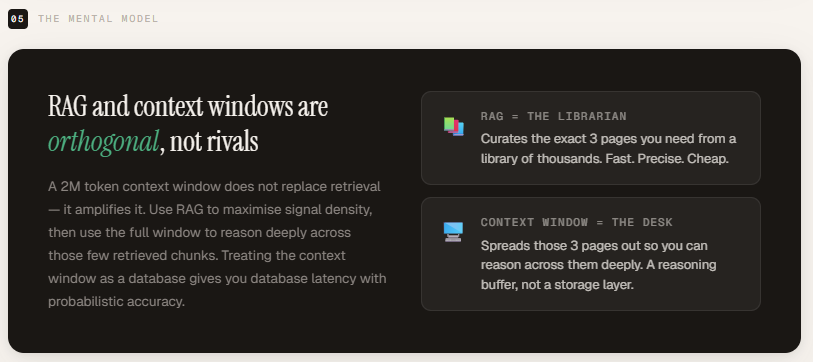
The main difference is that a context window defines how much the model can see, whereas a RAG determines what the model should see. A larger window increases capacity, but it does not improve relevancy. RAG filters and selects the most important information before it reaches the model, improving signal-to-noise ratio, efficiency and reliability. Both approaches solve different problems and are not substitutes for each other.
In this article, we compare both strategies directly. Using the OpenAI API, we evaluate retrieval-enhanced generation against brute-force context stuffing on the same documentation corpus. We measure token usage, latency, and cost – and demonstrate how burying important information inside larger signals can impact model performance. The results shed light on why larger context windows complement rather than replace RAGs.
install dependencies
import os
import time
import textwrap
import numpy as np
import tiktoken
from openai import OpenAI
from getpass import getpass
os.environ("OPENAI_API_KEY") = getpass('Enter OpenAI API Key: ')
client = OpenAI()We use Text-Embedding-3-Small as the embedding model to convert documents and queries into vector representations for efficient semantic retrieval. For generation and logic, we use gpt-4o, with token accounting handled through its associated TikTok encoding to accurately measure reference size and cost.
EMBED_MODEL = "text-embedding-3-small"
CHAT_MODEL = "gpt-4o"
ENC = tiktoken.encoding_for_model("gpt-4o")creation of document repository
This fund serves as the recovery source for our benchmark. In the RAG setup, embeddings are generated for each document and relevant parts are retrieved based on semantic similarity. In a context-stuffing setup, the entire corpus is injected into the prompt. Because documents contain specific numerical clauses (e.g., time frame, rate cap, refund window), they are suitable for testing retrieval accuracy, signal density, and “lost in between” effects under large-context conditions.
The corpus consists of 10 structured policy documents, totaling approximately 650 tokens, with each document containing between 54 and 83 tokens. This size keeps the dataset manageable while reflecting the diversity and density of realistic enterprise documentation sets.
Although relatively small, the corpus contains tightly packed numerical clauses, conditional rules, and compliance statements – making it suitable for evaluating retrieval precision, logic accuracy, and token efficiency. This provides a controlled environment to compare RAG-based selective retrieval against full reference stuffing without introducing external noise.
def count_tokens(text: str) -> int:
return len(ENC.encode(text))
DOCS = (
{
"id": 1, "title": "Refund Policy",
"content": (
"Customers may request a full refund within 30 days of purchase. "
"Refunds are processed within 5-7 business days to the original payment method. "
"Digital products are non-refundable once the download link has been accessed. "
"Subscription cancellations stop future charges but do not trigger automatic refunds "
"for the current billing cycle unless the cancellation is made within 48 hours of renewal."
)
},
{
"id": 2, "title": "Shipping Information",
"content": (
"Standard shipping takes 5-7 business days. Express shipping delivers in 2-3 business days. "
"Orders over $50 qualify for free standard shipping within the continental US. "
"International shipping is available to 30 countries and takes 10-21 business days. "
"Tracking numbers are emailed within 24 hours of dispatch."
)
},
{
"id": 3, "title": "Account Security",
"content": (
"Two-factor authentication (2FA) can be enabled from the Security tab in account settings. "
"Passwords must be at least 12 characters and include one uppercase letter, one number, "
"and one special character. Active sessions expire after 30 days of inactivity. "
"Suspicious login attempts trigger an automatic account lock and a reset email."
)
},
{
"id": 4, "title": "API Rate Limits",
"content": (
"Free tier: 100 requests per day, max 10 requests per minute. "
"Pro tier: 10 000 requests per day, max 200 requests per minute. "
"Enterprise tier: unlimited requests, burst up to 1 000 per minute. "
"All responses include X-RateLimit-Remaining and X-RateLimit-Reset headers. "
"Exceeding limits returns HTTP 429 with a Retry-After header."
)
},
{
"id": 5, "title": "Data Privacy & GDPR",
"content": (
"All user data is encrypted at rest using AES-256 and in transit using TLS 1.3. "
"We never sell or rent personal data to third parties. "
"The platform is fully GDPR and CCPA compliant. "
"Data deletion requests are processed within 72 hours. "
"Users can export all their data in JSON or CSV format from the Privacy section."
)
},
{
"id": 6, "title": "Billing & Subscription Cycles",
"content": (
"Subscriptions renew automatically on the same calendar day each month. "
"Annual plans offer a 20 % discount compared to monthly billing. "
"Invoices are sent via email 3 days before each renewal. "
"Failed payments retry three times over 7 days before the account is downgraded."
)
},
{
"id": 7, "title": "Supported File Formats",
"content": (
"Supported upload formats: PDF, DOCX, XLSX, PPTX, PNG, JPG, WebP, MP4, MOV. "
"Maximum individual file size is 100 MB. "
"Batch uploads support up to 50 files simultaneously. "
"Files are virus-scanned on upload and quarantined if threats are detected."
)
},
{
"id": 8, "title": "Compliance Certifications",
"content": (
"The platform holds SOC 2 Type II certification, renewed annually. "
"ISO 27001 compliance is maintained with quarterly internal audits. "
"A HIPAA Business Associate Agreement (BAA) is available for healthcare customers on the Enterprise plan. "
"PCI-DSS Level 1 compliance covers all payment processing flows."
)
},
{
"id": 9, "title": "SLA & Uptime Guarantees",
"content": (
"Enterprise SLA guarantees 99.9 % monthly uptime (≤ 43 minutes downtime/month). "
"Scheduled maintenance windows occur every Sunday between 02:00-04:00 UTC. "
"Unplanned incidents are communicated via status.example.com within 15 minutes. "
"SLA breaches are compensated with service credits applied to the next invoice."
)
},
{
"id": 10, "title": "Cancellation Policy",
"content": (
"Users can cancel at any time from the Subscription tab in account settings. "
"Annual plan holders receive a pro-rated refund for unused months if cancelled within 30 days of renewal. "
"Cancellation takes effect at the end of the current billing period; access continues until then. "
"Re-activation within 90 days of cancellation restores all historical data."
)
},
)total_tokens = sum(count_tokens(d("content")) for d in DOCS)
print(f"Corpus: {len(DOCS)} documents | {total_tokens} tokens totaln")
for d in DOCS:
print(f" ({d('id'):02d}) {d('title'):<35} ({count_tokens(d('content'))} tokens)")Building embedding index
We generate vector embeddings for all 10 documents using the text-embedding-3-small model and store them in a NumPy array. Each document is converted to a 1,536-dimensional float32 vector, creating an index with size (10, 1536).
The entire indexing phase completes in 1.82 seconds, which shows how lightweight semantic indexing is at this scale. This vector matrix now serves as our retrieval layer – enabling faster similarity search during the RAG workflow instead of scanning the raw text at inference time.
def embed_texts(texts: list(str)) -> np.ndarray:
"""Call OpenAI Embeddings API and return a (N, 1536) float32 array."""
response = client.embeddings.create(model=EMBED_MODEL, input=texts)
return np.array((item.embedding for item in response.data), dtype=np.float32)
print("Building index ... ", end="", flush=True)
t0 = time.perf_counter()
corpus_texts = (d("content") for d in DOCS)
index = embed_texts(corpus_texts) # shape: (10, 1536)
elapsed = time.perf_counter() - t0
print(f"done in {elapsed:.2f}s | index shape: {index.shape}")Recovery and prompt helper
The functions below implement the full comparison pipeline between RAG and reference stuffing.
- retrieve() embeds the user query, calculates cosine similarity via a dot product against a pre-computed index, and returns the top-k most relevant documents with similarity scores. Because text-embeddings-3-small output unit-norm vectors, the dot product directly represents cosine similarity – keeping retrieval both simple and efficient.
- build_rag_prompt() creates a focused prompt using only retrieved segments, ensuring high signal density and minimal irrelevant references.
- build_stuffed_prompt() builds a brute-force prompt by injecting the entire corpus into the context, emulating the “just use the whole window” approach.
- call_llm() sends signals to gpt-4o, measures latency, and captures token usage, allowing us to directly compare cost, speed, and efficiency between the two strategies.
Together, these aids create a controlled environment to benchmark retrieval precision versus raw reference capability.
def retrieve(query: str, k: int = 3) -> list(dict):
"""
Embed the query, compute cosine similarity against the index,
and return the top-k document dicts with their scores.
text-embedding-3-small returns unit-norm vectors, so the dot product
IS cosine similarity -- no extra normalisation needed.
"""
q_vec = embed_texts((query))(0) # shape: (1536,)
scores = index @ q_vec # dot product = cosine similarity
top_idx = np.argsort(scores)(::-1)(:k) # top-k indices, highest first
return ({"doc": DOCS(i), "score": float(scores(i))} for i in top_idx)
def build_rag_prompt(query: str, chunks: list(dict)) -> str:
"""Build a focused prompt from only the retrieved chunks."""
context_parts = (
f"(Source: {c('doc')('title')})n{c('doc')('content')}"
for c in chunks
)
context = "nn---nn".join(context_parts)
return (
f"You are a helpful support assistant. "
f"Answer the question below using the provided context. "
f"Be specific and direct.nn"
f"CONTEXT:n{context}nn"
f"QUESTION: {query}"
)
def build_stuffed_prompt(query: str) -> str:
"""Build a prompt that dumps the entire corpus into the context."""
context_parts = (
f"(Source: {d('title')})n{d('content')}"
for d in DOCS
)
context = "nn---nn".join(context_parts)
return (
f"You are a helpful support assistant. "
f"Answer the question below using the provided context. "
f"Be specific and direct.nn"
f"CONTEXT:n{context}nn"
f"QUESTION: {query}"
)
def call_llm(prompt: str) -> tuple(str, float, int, int):
"""Returns (answer, latency_ms, input_tokens, output_tokens)."""
t0 = time.perf_counter()
res = client.chat.completions.create(
model = CHAT_MODEL,
messages = ({"role": "user", "content": prompt}),
temperature = 0,
)
latency_ms = (time.perf_counter() - t0) * 1000
answer = res.choices(0).message.content.strip()
return answer, latency_ms, res.usage.prompt_tokens, res.usage.completion_tokenscomparing viewpoints
This block runs a direct, side-by-side comparison between Retrieval-Augmented Generation (RAG) and brute-force context stuffing using the same user query. In the RAG approach, the system first retrieves the top three most relevant documents based on semantic similarity, creates a focused signal using only those parts, and then sends that summary context to the model. It also prints similarity scores, token counts, and latency, allowing us to see how much context is actually needed to effectively answer the question.
In contrast, the context-filling approach constructs a prompt that includes all 10 documents regardless of relevance, and passes the entire corpus to the model. By measuring input tokens, output tokens, and response times for both methods under identical conditions, we isolate architectural differences between selective retrieval and brute-force loading. This makes the trade-offs in efficiency, cost, and performance concrete rather than theoretical.

QUERY = "How do I request a refund and how long does it take" DIVIDER = "─" * 65
print(f"n{'='*65}")
print(f" QUERY: {QUERY}")
print(f"{'='*65}n")
# ── RAG ──────────────────────────────────────────────────────────────────────
print("( APPROACH 1 ) RAG (retrieve then reason)")
print(DIVIDER)
chunks = retrieve(QUERY, k=3)
rag_prompt = build_rag_prompt(QUERY, chunks)
print(f"Top-{len(chunks)} retrieved chunks:")
for c in chunks:
preview = c("doc")("content")(:75).replace("n", " ")
print(f" • {c('doc')('title'):<40} similarity: {c('score'):.4f}")
print(f" "{preview}..."")
print(f"nTotal tokens being sent to LLM: {count_tokens(rag_prompt)}n")
rag_answer, rag_latency, rag_in, rag_out = call_llm(rag_prompt)
print(f"Answer:n{textwrap.fill(rag_answer, 65)}")
print(f"nTokens → input: {rag_in:>6,} | output: {rag_out:>4,} | total: {rag_in+rag_out:>6,}")
print(f"Latency → {rag_latency:,.0f} msn")
# ── Approach 2: Context Stuffing ──────────────────────────────────────────────
print("( APPROACH 2 ) Context Stuffing (dump everything, then reason)")
print(DIVIDER)
stuffed_prompt = build_stuffed_prompt(QUERY)
print(f"Sending all {len(DOCS)} documents ({count_tokens(stuffed_prompt):,} tokens) to the LLM ...n")
stuff_answer, stuff_latency, stuff_in, stuff_out = call_llm(stuffed_prompt)
print(f"Answer:n{textwrap.fill(stuff_answer, 65)}")
print(f"nTokens → input: {stuff_in:>6,} | output: {stuff_out:>4,} | total: {stuff_in+stuff_out:>6,}")
print(f"Latency → {stuff_latency:,.0f} msn")The results show that both approaches give correct and almost identical answers – but the efficiency profile is very different.
With RAG, only the three most relevant documents were retrieved, resulting in 278 tokens sent to the model (285 actual prompt tokens). Total token usage was 347, and response latency was 783 ms. The retrieved segments clearly prioritized the refund policy, which contains the direct answer, while the remaining two documents were secondary matches based on semantic similarity.
Along with the reference material, all 10 documents were injected into the prompt, increasing the input size to 775 tokens and the total usage to 834 tokens. Latency almost doubled to 1,518 ms. Despite processing more than twice as many input tokens, the model gave essentially the same answer.
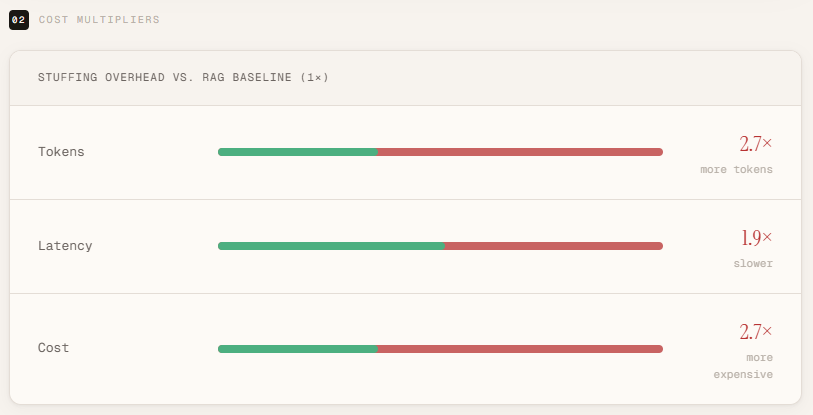
The point is not that stuffing fails – it works on a smaller scale – but that it is inefficient. RAG achieved the same output with less than half the tokens and almost half the latency. As the corpus size increases from 10 documents to thousands, this difference increases dramatically. What seems harmless at 768 tokens becomes extremely expensive and slow at 500k+ tokens. This is the economic and architectural rationale for recovery: optimize the signal before the logic.

token_ratio = stuff_in / rag_in
latency_ratio = stuff_latency / rag_latency
COST_PER_1M = 2.5
rag_cost = (rag_in / 1_000_000) * COST_PER_1M
stuff_cost = (stuff_in / 1_000_000) * COST_PER_1M
print(f"n{'='*65}")
print(f" HEAD-TO-HEAD SUMMARY")
print(f"{'='*65}")
print(f" {'Metric':<30} {'RAG':>10} {'Stuffing':>10}")
print(f" {DIVIDER}")
print(f" {'Input tokens':<30} {rag_in:>10,} {stuff_in:>10,}")
print(f" {'Output tokens':<30} {rag_out:>10,} {stuff_out:>10,}")
print(f" {'Latency (ms)':<30} {rag_latency:>10,.0f} {stuff_latency:>10,.0f}")
print(f" {'Cost per call (USD)':<30} ${rag_cost:>9.6f} ${stuff_cost:>9.6f}")
print(f" {DIVIDER}")
print(f" {'Token multiplier':<30} {'1x':>10} {token_ratio:>9.1f}x")
print(f" {'Latency multiplier':<30} {'1x':>10} {latency_ratio:>9.1f}x")
print(f" {'Cost multiplier':<30} {'1x':>10} {token_ratio:>9.1f}x")
print(f"{'='*65}")A head-to-head comparison makes the trade-offs clear. Context stuffing requires 2.7× more input tokens, about 2× latency, and 2.7× cost per call – while producing essentially the same answer as RAG. The output token count remained the same, meaning the additional spend came from a completely unnecessary context.

lost in mid impact
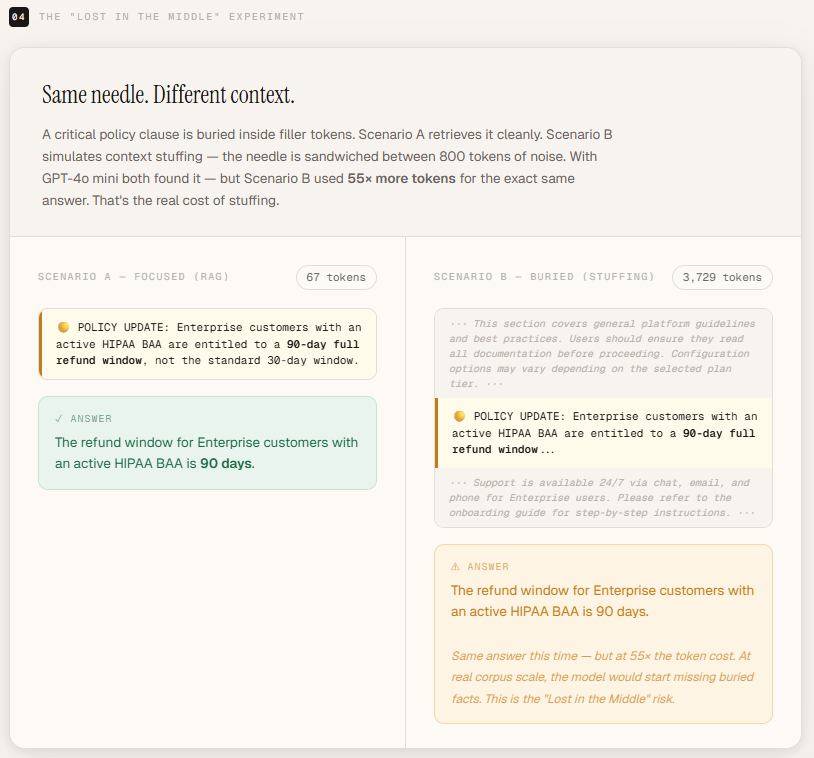
To demonstrate the “lost in the middle” effect, we create a controlled setup where an important policy update – the needle – states that enterprise customers with an active HIPAA BAA are entitled to a 90-day refund window instead of the standard 30 days. This section answers the question directly, but is intentionally hidden inside approximately 800 tokens of irrelevant filler text, designed to simulate a bloated, overfilled prompt. By asking, “What is the refund window for enterprise customers with HIPAA BAA?”, we can test whether the model reliably extracts suppressed segments when surrounded by noise, showing how large context alone does not guarantee accurate attention or retrieval.
NEEDLE = (
"POLICY UPDATE: Enterprise customers with an active HIPAA BAA "
"are entitled to a 90-day full refund window, not the standard 30-day window."
)
# ~800 tokens of irrelevant padding to simulate a bloated document
FILLER = (
"This section covers general platform guidelines and best practices. "
"Users should ensure they read all documentation before proceeding. "
"Configuration options may vary depending on the selected plan tier. "
"Please refer to the onboarding guide for step-by-step instructions. "
"Support is available 24/7 via chat, email, and phone for Enterprise users. "
) * 30NEEDLE_QUERY = "What is the refund window for Enterprise customers with a HIPAA BAA?"def run_lost_in_middle():
print(f"n{'='*65}")
print(" 'LOST IN THE MIDDLE' EXPERIMENT")
print(f"{'='*65}")
print(f"Query : {NEEDLE_QUERY}")
print(f"Needle: "{NEEDLE(:65)}..."n")
# Scenario A: Focused (simulates a good RAG retrieval)
prompt_a = (
f"You are a helpful support assistant. "
f"Answer the question using the context below.nn"
f"CONTEXT:n{NEEDLE}nn"
f"QUESTION: {NEEDLE_QUERY}"
)
# Scenario B: Buried (simulates stuffing -- needle is in the middle of noise)
buried = f"{FILLER}nn{NEEDLE}nn{FILLER}"
prompt_b = (
f"You are a helpful support assistant. "
f"Answer the question using the context below.nn"
f"CONTEXT:n{buried}nn"
f"QUESTION: {NEEDLE_QUERY}"
)
print(f"( A ) Focused context ({count_tokens(prompt_a):,} input tokens)")
ans_a, _, _, _ = call_llm(prompt_a)
print(f"Answer: {ans_a}n")
print(f"( B ) Needle buried in filler ({count_tokens(prompt_b):,} input tokens)")
ans_b, _, _, _ = call_llm(prompt_b)
print(f"Answer: {ans_b}n")
print("─" * 65)In this experiment, both setups give the correct answer – 90 days – but the difference in context size is significant. The focused version requires only 67 input tokens, providing correct responses with minimal context. In contrast, the stuffed version required 55× more inputs, with 3,729 input tokens to arrive at the same answer.
At this scale, the model was still able to detect the buried section. However, the result highlights an important principle: accuracy is not the only metric – efficiency and reliability are. As the context size further increases, attention propagation, latency, cost composition, and retrieval precision become increasingly important. The experiment shows that larger context windows can still succeed, but they do so at dramatically higher computational expense and with greater risk as documents become longer and more complex.

I am a Civil Engineering graduate (2022) from Jamia Millia Islamia, New Delhi, and I have a keen interest in Data Science, especially Neural Networks and their application in various fields.
