

Long-chain reasoning is one of the most computation-intensive tasks in modern large language models. When a model like DeepSeek-R1 or Qwen3 works through a complex math problem, it may generate thousands of tokens before arriving at an answer. Each of those tokens must be stored in a KV cache – a memory structure containing key and value vectors that the model needs to look back up during generation. The longer the logic chain, the larger the KV cache, and for many deployment scenarios, especially on consumer hardware, this increase eventually exhausts GPU memory entirely.
A team of researchers from MIT, NVIDIA, and Zhejiang University proposed a method called tridhyana Which directly solves this problem. On the AIME25 mathematical logic benchmark with 32K-token generation, TriAttention matches full attention accuracy while achieving 2.5× higher throughput or 10.7× KV memory reduction. Leading baselines achieve only half the accuracy at the same efficiency level.
Problem with existing KV cache compression
To understand why triattention is important, it helps to understand the standard approach to KV cache compression. Most existing methods – including SnapKV, H2O and R-KV – work by guessing which tokens are important in the KV cache and throwing out the rest. Importance is typically estimated by looking at the attention score: if a key receives high attention from recent queries, it is considered important and kept.
The problem is that these methods work in what the research team calls Post-ROPE space. RoPE, or Rotary Position EmbeddingLAMA is the positional encoding scheme used by most modern LLMs, including Queue and Mistral. RoPE encodes the state by rotating the query and key vectors in a frequency-dependent manner. As a result, a query vector at position 10,000 looks very different from the same semantic query at position 100, because its direction has been rotated by the position encoding.
This rotation means that only the most recently generated queries have orientations that are ‘up to date’ to predict which keys are important right now. Previous work has confirmed this empirically: increasing the observation window for importance estimation does not help – performance peaks at around 25 queries and declines thereafter. With such a small window, some keys that will become important later are permanently evicted.
This problem is particularly serious for what the research team calls recovery head – Attention heads whose function is to retrieve specific factual tokens from longer contexts. Tokens relevant to the recovery vertex may remain dormant for thousands of tokens before suddenly becoming necessary for the logic chain. Post-ROPE methods, operating on a narrow observation window, pay less attention to those tokens during the dormant period and permanently evict them. When the model later needs to recall that information, it is already gone, and the chain of thought is broken.
Pre-Rope Overview: Q/K Concentration
The main insight into TriAttention comes from looking at the query and key vectors First RoPE rotation is applied – pre-RoPE location. When the research team visualized the q and k vectors in this space, they found something consistent and striking: In most attention heads and many model architectures, both the q and k vectors cluster tightly around fixed, non-zero center points. The research team considers it an asset Q/K concentrationand measures it using mean resultant length R – A standard directional statistical measure where R → 1 means tight clustering and R → 0 means dispersion in all directions.
On Qwen3-8B, about 90% of the focus heads exhibit R > 0.95, meaning that their pre-RoPE Q/K vectors are almost perfectly centered around their respective centers. Critically, these centers are stable across different token conditions and different input sequences – they are an intrinsic property of the model’s learned weights, not a property of any particular input. The research team further confirms that the Q/K concentration is domain-agnostic: measuring the average resultant length in the math, coding, and chat domains on the Qwen3-8B yields nearly identical values of 0.977–0.980.
This stability is one that post-ROPE methods cannot exploit. RoPE rotation spreads these concentric vectors in an arc pattern that varies with position. But centers remain fixed in the pre-ROPE area.
From concentration to trigonometric series
The research team then shows mathematically that when the Q and K vectors are centered around their centers, the attention logit – the raw score prior to softmax that determines how much attention a query gives to a key – is dramatically simplified. By substituting the Q/K centers into the RoPE attention formula, the logit is reduced to a function that depends only on qq distance (relative positional difference between the query and the key), expressed as a trigonometric series:
logit(Δ)≈∑f‖q‾f‖‖k‾f‖⏟amplitudecos(ωfΔ+ϕ‾f⏟phase)=∑f(afcos(ωfΔ)+bfsin(ωfΔ)) text{logit}(Delta) approx sum_{f} underbrace{|bar{q}_f| !
Here, Δ is the positional distance, ωF The RoPE rotation frequencies and coefficients a for each frequency band f areF and bF Q/K is determined by the centres. This series produces a specific focus-versus-distance curve for each head. Some heads prefer nearby keys (local attention), others prefer far away keys (attention-seeking). The centers calculated offline from the calibration data completely determine which distance is preferred.
The research team verified this experimentally with 1,152 attention heads in Qwen3-8B and Qwen2.5 and Llama3 architectures. The Pearson correlation between the estimated trigonometric curve and the actual attention log has a mean above 0.5 across all vertices, with many vertices achieving correlations of 0.6–0.9. The research team validates it on GLM-4.7-Flash, using Multi-Head Latent Attention (MLA) Instead of the standard grouped-query attention – a meaningfully different attention architecture. On MLA, 96.6% of the heads exhibit R > 0.95, while for GQA it is 84.7%, which confirms that Q/K concentration is not specific to an attention design but is a general property of modern LLMs.
How does TriAttention use it?
Triattention is a KV cache compression method that uses these inferences to score keys without requiring any live query observation. The scoring function is Two components:
Trigonometric Series Score (Strig) uses the offline-computed queue center and the actual cached key representation to predict how much attention a key will receive, based on its positional distance from future queries. Because queries can be answered at multiple future positions on a key, triattention averages this score over a set of future offsets using geometric spacing.
Strig(k,Δ)=∑f‖𝔼(qf)‖⋅‖kf‖⋅cos(ωfΔ+ϕf)S_{text{trig}}(k, Delta) = sum_{f} |mathbb{E}(q_f)| cdot |k_f| cdot cos(omega_f Delta + phi_f)
standards-based scores (SIdeal) handles attentional minorities where Q/K concentration is low. It weights each frequency band based on its expected query norm contribution, providing complementary information about token prominence beyond just distance preference.
Snorm(0)(k)=∑f𝔼(‖qf‖)⋅‖kf‖S_{text{norm}}^{(0)}(k) = sum_{f} mathbb{E}(|q_f|) cdot |k_f|
Both scores are combined using the average resulting length R as an adaptive weight: when the concentration is high, Strig dominates; When the concentration is low, SIdeal Contributes more. For each of the 128 generated tokens, TriAttention scores all the keys in the cache and retains only the top-B, throwing out the rest.
results on mathematical logic
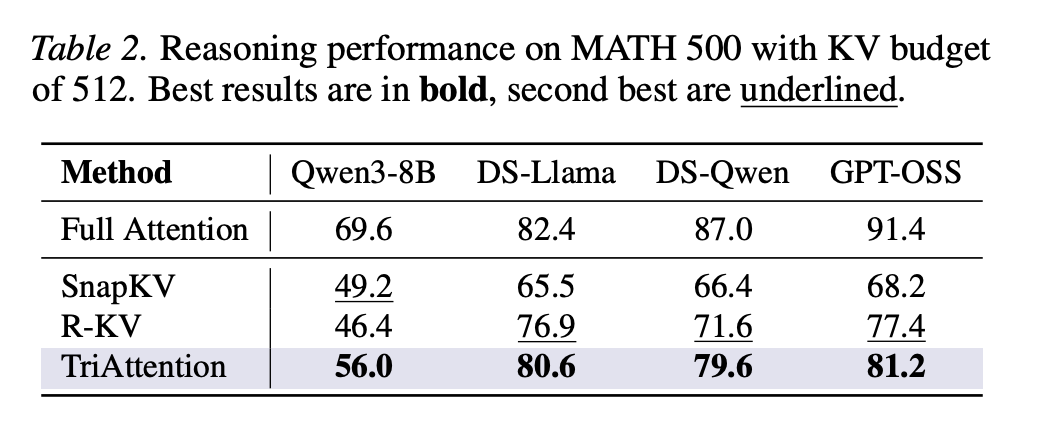
On AIME24 with Qwen3-8B, TriAttention achieves 42.1% accuracy versus 57.1% for Full Attention, while R-KV achieves only 25.4% on the same KV budget of 2,048 tokens. On AIME25, TriAttention achieved 32.9% versus R-KV’s 17.5% – a difference of 15.4 percentage points. With only 1,024 tokens in the KV cache out of a possible 32,768 on MATH 500, TriAttention achieves 68.4% accuracy versus 69.6% for Full Attention.

The research team also provides an introduction Recursive State Query Benchmark Based on iterative simulation using depth-first search. Recursive functions put a strain on memory retention because the model must maintain intermediate states in long chains and later track them back – if an intermediate state is evicted, the error propagates through all subsequent return values, corrupting the final result. Under moderate memory pressure up to depth 16, TriAttention performs comparable to full attention, while R-KV shows catastrophic accuracy degradation – falling from about 61% at depth 14 to 31% at depth 16. This indicates that R-KV incorrectly excludes important intermediate logic states.
On throughput, TriAttention achieves 1,405 tokens per second on MATH 500 compared to Full Attention’s 223 tokens per second, a 6.3× speedup. On AIME25, it fetches 563.5 tokens per second versus 222.8, which is a 2.5× speedup on matching accuracy.
Generalization beyond mathematical logic
The results extend far beyond mathematics standards. But longbench – 16-subtask benchmark covering question answering, summarization, few-shot classification, retrieval, counting, and code tasks – TriAttention achieved the highest average score of 48.1 among all compression methods on Qwen3-8B at 50% KV budget, winning 11 out of 16 subtasks and surpassing the next best baseline, Ada-KV+SnapKV, by 2.5 points. But ruler On the 4K reference length retrieval benchmark, TriAttention achieves 66.1, a 10.5-point difference over SnapKV. These results confirm that the method is not limited to mathematical logic – the underlying Q/K concentration phenomenon transfers to general language tasks.
key takeaways
- There is a fundamental blind spot in existing KV cache compression methods.: Methods like SnapKV and R-KV estimate token importance using recent post-ROPE queries, but because ROPE rotates query vectors with state, only a small window of queries is usable. This causes critical tokens – especially those required to recover heads – to be permanently evicted before they become critical.
- Pre-ROPE query and key vectors cluster around stable, fixed centers in almost all attention heads: This property, called Q/K concentration, holds regardless of input content, token state, or domain, and is consistent across multi-head latent attention architectures such as Qwen3, Qwen2.5, Llama3, and even GLM-4.7-Flash.
- These stable centers make the attention patterns mathematically predictable without observing any live question: When Q/K vectors are centered, the attention score between any query and key reduces to a function that depends only on their positional distance – encoded as a trigonometric series. TriAttention uses this to score each cached key offline using calibration data alone.
- TriAttention matches full attention logic accuracy at a fraction of the memory and computation cost.: On AIME25 with 32K-token generation, this achieves 2.5× higher throughput or 10.7× KV memory reduction while matching full attention accuracy – almost double the accuracy of R-KV on the same memory budget in both AIME24 and AIME25.
- This method generalizes beyond mathematics and works on consumer hardware. TriAttention outperforms all baselines on Longbench on 16 common NLP subtasks and the ruler retrieval benchmark, and enables 32B reasoning models to be run on a single 24GB RTX 4090 via OpenClause – a task that would cause out-of-memory errors under Full Attention.
check it out paper, repo And project page. Also, feel free to follow us Twitter And don’t forget to join us 120k+ ml subreddit and subscribe our newsletter. wait! Are you on Telegram? Now you can also connect with us on Telegram.
Do you need to partner with us to promote your GitHub repo or Hugging Face page or product release or webinar, etc?join us
The post Researchers from MIT, NVIDIA, and Zhejiang University Propose Post TriAttention: A KV Cache Compression Method That Matches Full Attention at 2.5× Higher Throughput appeared first on MarkTechPost.