

Tencent AI Lab has released covo-audioA 7B-parameter end-to-end Large Audio Language Model (LALM). The model is designed to integrate speech processing and language intelligence by directly processing continuous audio input and generating audio output within the same architecture.
System Architecture
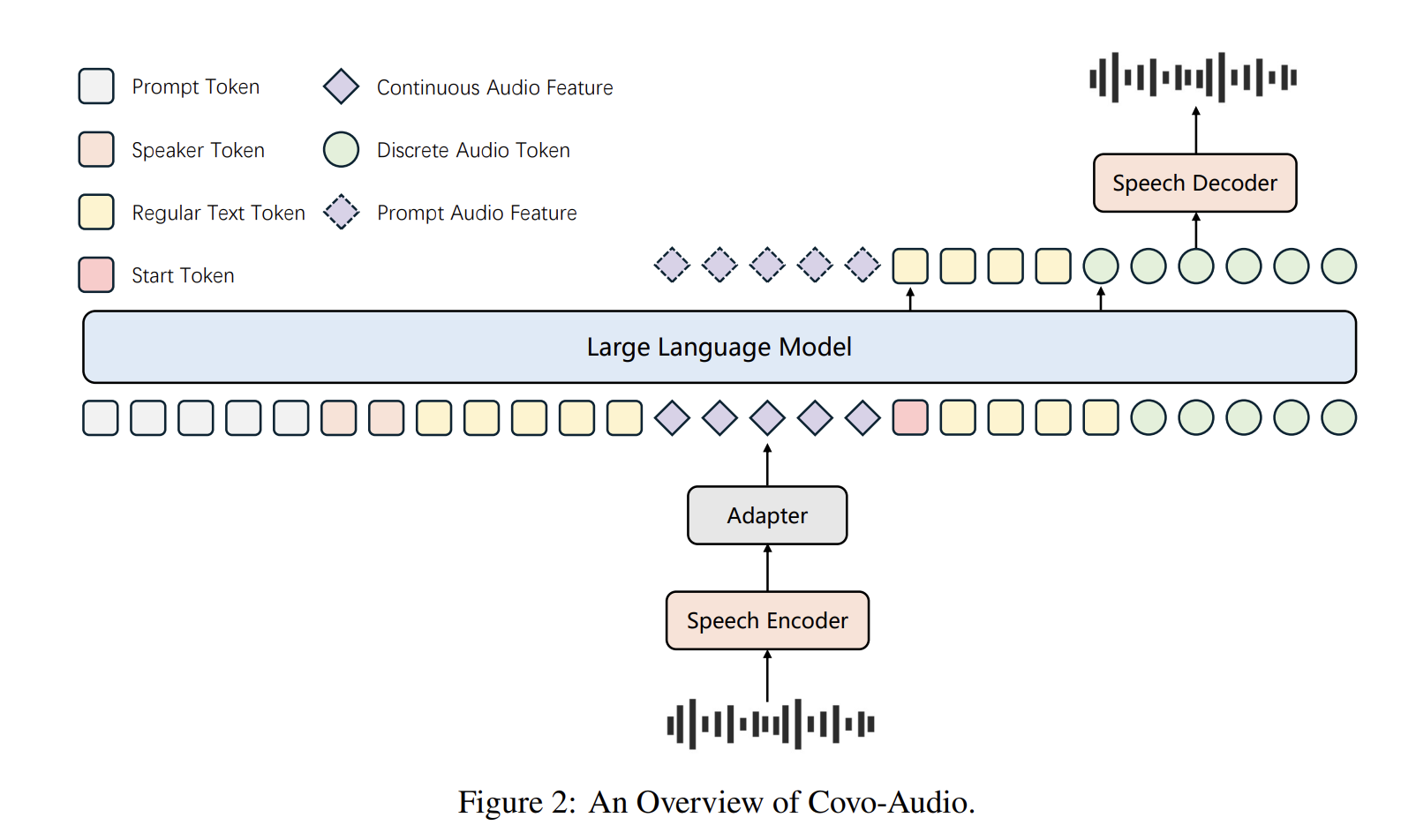
The Covo-Audio framework consists of four primary components designed for seamless cross-modal interaction:
- audio encoder: model uses whisper-big-v3 It is used as the primary encoder due to its robustness against background noise and various accents. This component operates at a frame rate 50Hz.
- audio adapter: To bridge the encoder and the LLM, a special adapter employs three downsampling modules, which integrate linear and convolution layers to reduce the frame rate. 50Hz to 6.25Hz.
- LLM Backbone: the system is built on Qwen2.5-7B-BaseWhich is optimized for processing interleaved sequences of continuous acoustic features and text tokens.
- Speech Tokenizer and Decoder:Tokenizer, based on WavLM-LargeUses a codebook size of 16,384 To produce discrete audio tokens 25Hz. Decoder uses a Flow-Matching (FM) based framework and a BigVGAN Vocoder for high-fidelity reconstruction 24K waveform.
Hierarchical Tri-Modal Interleaving
A major contribution of this work is Hierarchical Tri-Modal Speech-Text Interleaving strategy. Unlike traditional methods that work only at the word or character level, this framework aligns acoustic features across continuous discrete speech tokens and natural language text
- sequential interleaving : Continuous features, text, and individual tokens arranged in a progressive series.
- parallel integration : Continuous features are aligned with a paired text-discrete entity.
The hierarchical aspect ensures structural coherence by using phrase-level interleaving for fine-grained alignment and sentence-level interleaving to preserve global semantic integrity in long-form utterances.. The training process overall consisted of a two-step pre-training pipeline processing 2T token.
Intelligence-Speaker Decoupling
To reduce the high cost of producing large-scale dialogue data for specific speakers, the research team proposed a Intelligence Speaker Decoupling strategy. This technology separates dialogue intelligence from voice rendering, allowing flexible voice customization using minimal text-to-speech (TTS) data.
This method reformats high-quality TTS recordings into pseudo-conversations hidden text loss. By excluding the text response part from the loss calculation, the model preserves its reasoning capabilities while still achieving the naturalness of a TTS speaker.. This enables personalized conversations without the need for extensive, speaker-specific conversation datasets.
Full-duplex voice interaction
Covo-audio developed quovo-audio-chat-fdA version capable of simultaneous dual-stream communication. The audio encoder is reformatted in a chunk-streaming manner, and the user and model streams are chunk-interleaved. 1:4 ratio. each piece represents 0.16s of audio.
The system manages conversation states through specific architectural tokens:
- think token: indicates a listen-only state while the model waits to respond.
- shift token: Symbolizes the transition to the model’s speaking turn.
- break token: Detects interference signals (barge-ins), causing the model to immediately stop speaking and return to listening.
For multi-turn scenarios, the model applies Recursive context-filling strategywhere continuous audio features from user input and tokens generated from the previous turn are prefixed as historical context.
Audio Reasoning and Reinforcement Learning
To enhance complex reasoning, the model includes Chain of Thought (COT) logic and Group Relative Policy Optimization (GRPO). The model is optimized using a verifiable aggregate reward function:
$$R_{total} = R_{accuracy} + R_{format} + R_{stability} + R_{think}$$
This structure allows the model to be optimized for accuracy structured output follow logical consistency and depth of logic .
evaluation and performance
Covo-Audio (7b) shows competitive or better results on several evaluated benchmarks, with the strongest claims being made for models of comparable scale and selected speech/audio tasks. But MMAU benchmark, it achieved an average score 75.30%Highest rated 7B-scale model. It excelled significantly in musical understanding 76.05%. But MMSU benchmark, Covo-Audio achieved leading 66.64% average accuracy.
Regarding its interactive forms, quovo-audio-chat gave a strong performance at euro-benchParticularly in speech reasoning and spoken dialogue tasks, better performing models such as QUEN3-Omni on the sugar track. for empathetic conversation vstyle benchmark, it achieved state-of-the-art results in Mandarin for anger (4.89), sadness (4.93), and anxiety (5.00).
The research team noted an ‘early-response’ issue on the GaokaoEval full-duplex setting, where unusually long silent pauses between tone fragments could lead to premature responses. This ‘early-response’ behavior is related to the pause-handling success metric of the model and is identified as an important direction for future optimization.
key takeaways
- Integrated end-to-end architecture: Covo-Audio is a 7B-parameter model that natively processes continuous audio input and produces high-fidelity audio output within a single, unified architecture. This eliminates the need for cascaded ASR-LLM-TTS pipelines, reducing error propagation and information loss.
- Hierarchical Tri-Modal Interleaving: The model uses a special strategy to align continuous acoustic features, discrete speech tokens, and natural language text. By combining these modalities at both the phrase and sentence levels, it preserves global semantic integrity while capturing fine-grained prosody nuances.
- Intelligence-Speaker Decoupling: Tencent research team has introduced a technique to separate dialogue intelligence from specific voice rendering. This allows flexible voice customization using lightweight text-to-speech (TTS) data, significantly reducing the cost of developing personalized conversation agents.
- Native full-duplex interaction:kovo-audio-chat-fd variant supports simultaneous listening and speaking. It uses specific architectural tokens – think, shift and brake – to manage complex real-time dynamics such as smooth turn-taking, backchanneling and user barge-in.
- Superior parameter efficiency: Despite its compact 7B scale, Covo-Audio achieves state-of-the-art or highly competitive performance in key benchmarks including MMAU, MMSU and URO-Bench. This often matches or exceeds the performance of much larger systems, such as 32b-parameter models, in audio and speech understanding tasks.
check it out paper, Model on HF And repo. Also, feel free to follow us Twitter And don’t forget to join us 120k+ ml subreddit and subscribe our newsletter. wait! Are you on Telegram? Now you can also connect with us on Telegram.

Michael Sutter is a data science professional and holds a Master of Science in Data Science from the University of Padova. With a solid foundation in statistical analysis, machine learning, and data engineering, Michael excels in transforming complex datasets into actionable insights.