

Agent AI systems sit on top of larger language models and connect to tools, memory, and the external environment. They already support scientific discovery, software development, and clinical research, yet they still struggle with unreliable equipment utilization, weak long-term planning, and poor generalization. Latest Research Paper’Optimization of Agentic AI‘Stanford, Harvard, UC Berkeley, Caltech have proposed a unified approach to how these systems should be optimized and mapped existing methods into a compact, mathematically defined framework.
How this paper models an agentic AI system,
The research survey models an agentic AI system as a foundation model agent with 3 key components. A planning module decomposes goals into a sequence of actions that react to feedback, using static processes such as Chain-of-Thought and Tree-of-Thought, or dynamic processes such as React and Reflexion. A tool usage module connects the agent to web search engines, APIs, code execution environments, model reference protocols, and browser automation. A memory module stores short-term context and long-term knowledge, which is accessed through retrieval enhanced generation. Optimization changes signals or parameters for these components using supervised fine tuning, preference based methods such as direct preference optimization, reinforcement learning methods such as adjacency policy optimization and group relative policy optimization, and parameter efficient techniques such as low rank optimization.
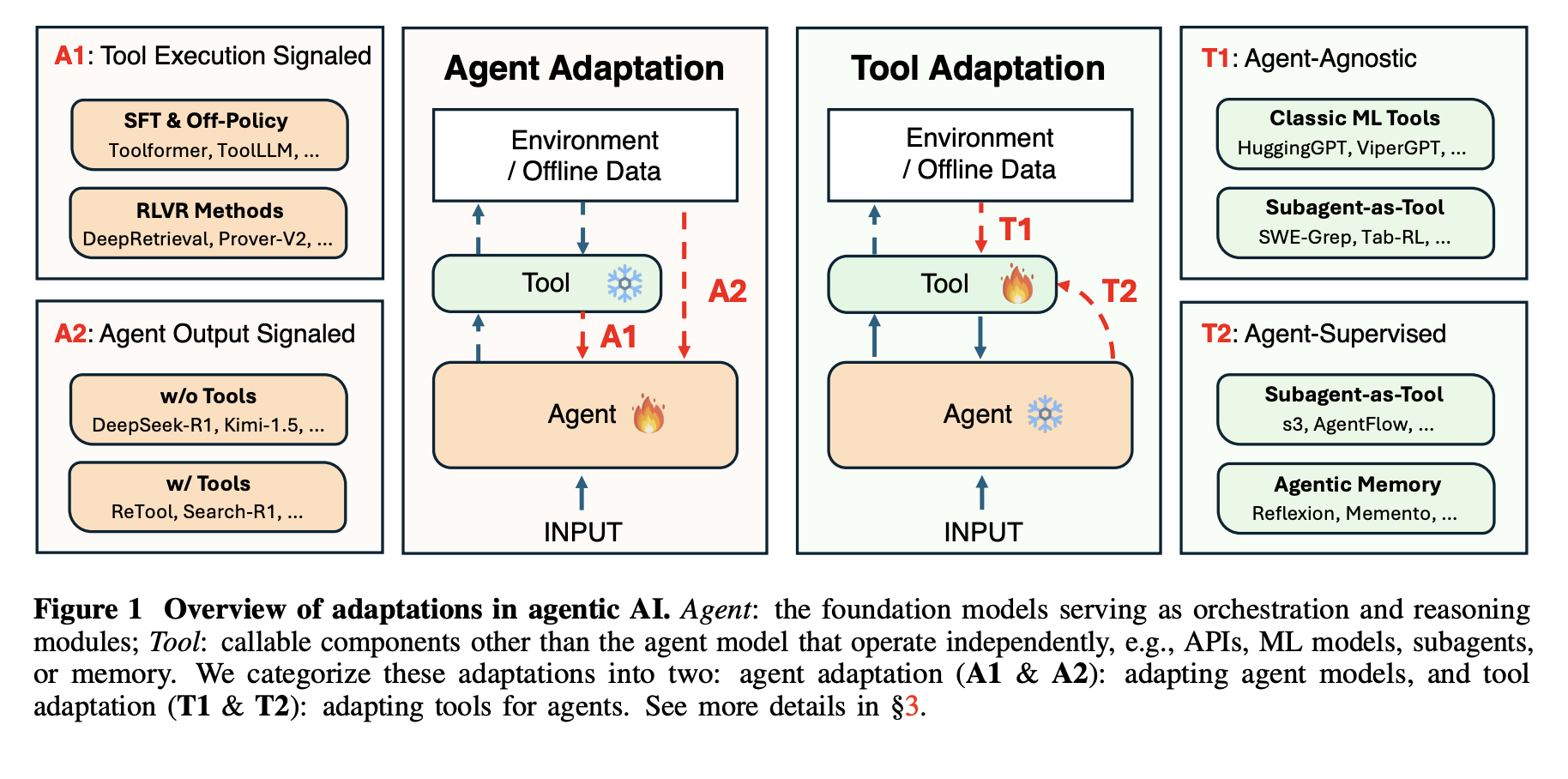
four optimization models
The framework defines 4 optimization patterns combining 2 binary options. The first dimension is goal,agent optimization versus device optimization. The second dimension is the supervision signal, device execution versus agent output. This yields A1 and A2 for optimizing the agent and T1 and T2 for optimizing the tool.
A1, Tool Execution Signaled Agent Adaptation, adapts the agent using feedback received from tool execution. A2, Agent Output Signal Agent Optimization, optimizes the agent using only the signals defined at its final output. T1, agent-agnostic tool optimization, optimizes the tool without reference to any particular agent. T2, agent-supervised tool optimization, optimizes the tool under the supervision of a fixed agent.
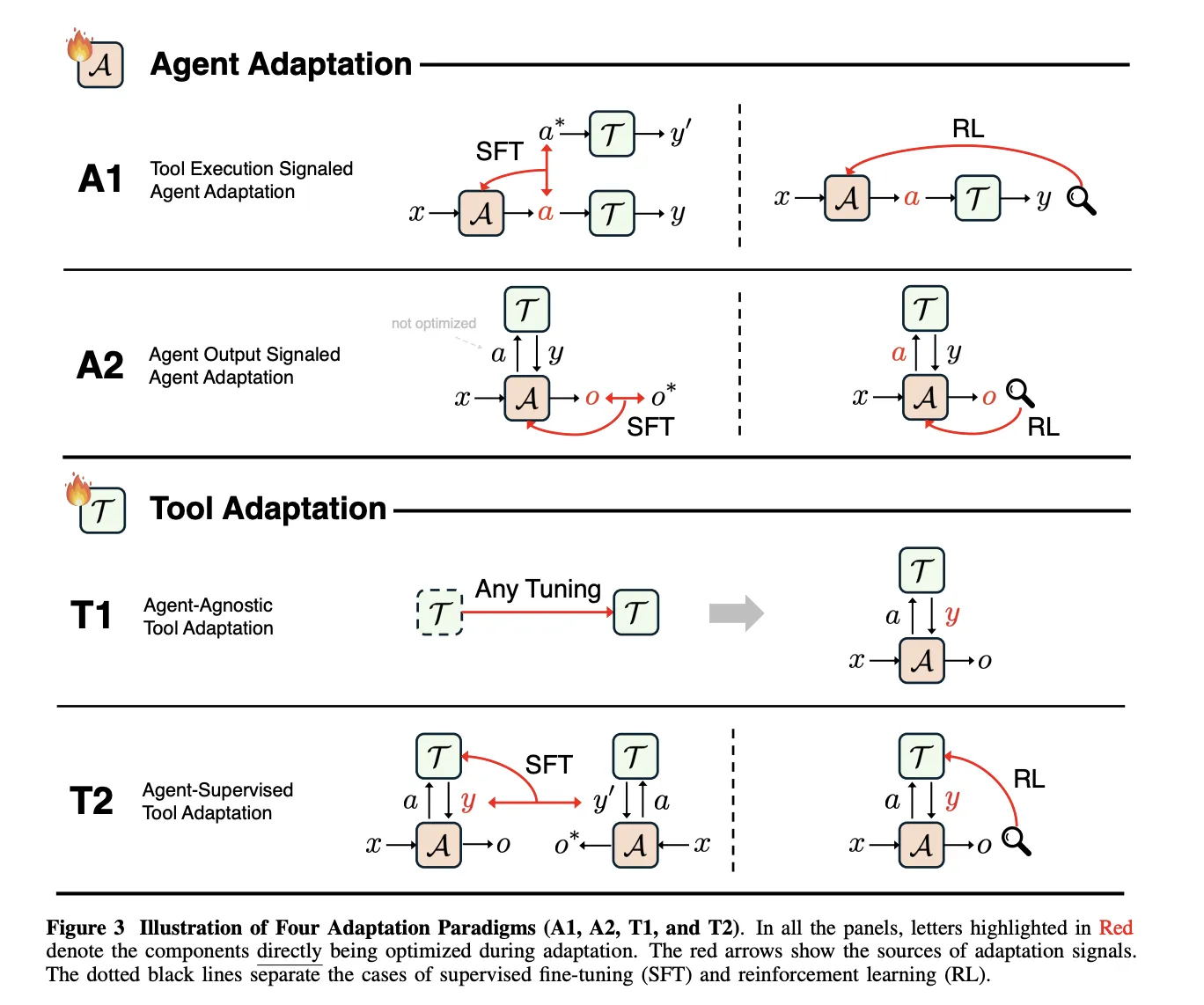
A1, Verifiable Tools Learning from Feedback
In A1, the agent receives an input x, generates a structured tool call a, the tool returns a result y, and the learning objective O_tool measures the success of the tool, for example execution correctness or retrieval quality. The paper covers both supervised copying of successful tool trajectories and reinforcement learning that uses verifiable tool outcomes as rewards.
ToolFormer, ToolAlpaca, and Gorilla describe supervised A1 methods, as each uses the execution results of a real tool to create or filter training traces before imitation. All these tools have observation signals defined at the behavior level, not at the final response level.
Deep retrieval is a central A1 example of reinforcement learning. It frames query reformulation as a Markov decision process where the state is the user query, the action is a rewritten query, and the reward combines recall and NDCG, a format term, and retrieval metrics for text of SQL, SQL execution accuracy. The policy is trained with KL regularized adjacency policy optimization and covers similar objectives like literature search, corpus question answering and text in SQL.
A2, learning from the final agent output
A2 covers cases where the optimization objective O_agent depends only on the final output o produced by the agent, even when the agent uses the tool internally. The survey shows that merely supervising O to teach the tool is not enough, because the agent can ignore the tool and still improve the probability. Effective A2 systems therefore combine supervision over tool calls with supervision over final answers, or provide sparse rewards such as perfect match accuracy from O and broadcast them back through the full trajectory.
T1, agent agnostic tool training
T1 freezes the core agents and optimizes the tools so they are widely reusable. Objective O_tool depends only on tool output and is measured by metrics such as retrieval accuracy, ranking quality, simulation fidelity, or downstream task success. A1 trained search strategies, such as deep retrieval, can later be reused as T1 tools inside new agentic systems without modifying the main agent.
T2, optimized equipment under frozen agent
T2 assumes a powerful but fixed agent A, which is common when the agent is a closed source foundation model. The tool executes the call and returns the result which the agent uses to generate O. The optimization objective again resides on the O_agent, but the trainable parameters are related to the device. The paper describes variants of quality weighted training, goal based training and reinforcement learning which all derive learning signals for the device from the final agent output.
The survey treats long-term memory as a special case of T2. Memory is an external store that is written to and read from learned actions, and the agent remains frozen. Recent T2 systems include s3, which trains a 7 billion parameter searcher that maximizes the Gain Beyond RAG reward defined by the frozen generator, and agentflow, which trains a planner to organize mostly frozen Qwen2.5 based modules using Flow GRPO.
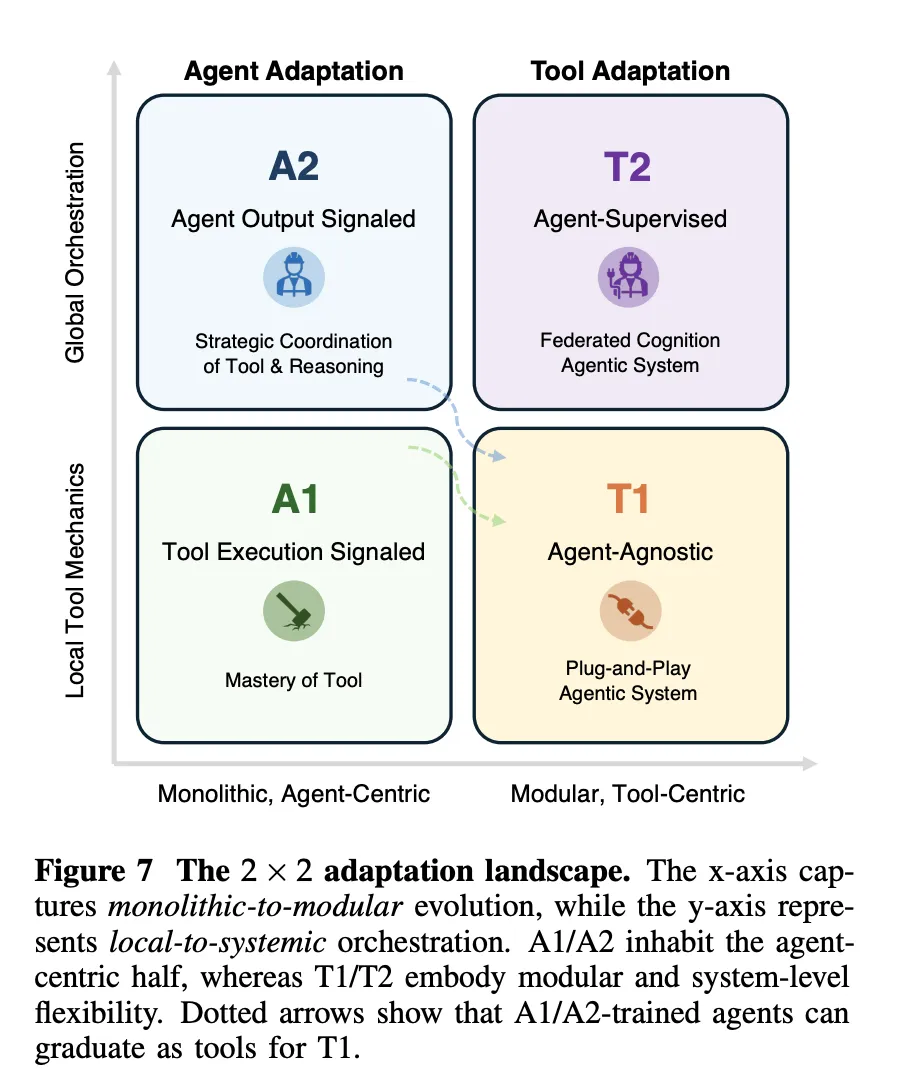
key takeaways
- The research defines a precise 4 paradigm framework for optimizing agentic AI by crossing 2 dimensions, whether the optimization targets the agent or the tool, and whether the supervision signal comes from the tool execution or from the final agent output.
- A1 methods such as ToolFormer, ToolAlpaca, Gorilla, and DeepRetrieval optimize the agent directly from verifiable tool feedback, including retrieval metrics, SQL execution accuracy, and code execution results, often optimized with KL regularized adjacency policy optimization.
- A2 methods optimize the agent from signals on the final output, for example answer accuracy, and the paper shows that the system must still monitor tool calls or propagate sparse rewards through the full trajectory, otherwise the agent may ignore the tool even while improving the probability.
- T1 and T2 transfer learning to tools and memory, T1 typically trains useful retrievers, searchers, and simulators without any specific agent in mind, while T2 optimizes tools under a frozen agent, such as in s3 and AgentFlow where a fixed generator supervises a learned searcher and planner.
- The research team presents an optimization scenario that deals with monolithic versus modular and local versus systemic control, and they argue that practical systems will combine infrequent A1 or A2 updates on a strong base model with frequent T1 and T2 optimizations of retrievers, search policies, simulators, and memory for robustness and scalability.
check it out paper And GitHub repoAlso, feel free to follow us Twitter And don’t forget to join us 100k+ ml subreddit and subscribe our newsletterwait! Are you on Telegram? Now you can also connect with us on Telegram.

Michael Sutter is a data science professional and holds a Master of Science in Data Science from the University of Padova. With a solid foundation in statistical analysis, machine learning, and data engineering, Michael excels in transforming complex datasets into actionable insights.