

How can a trillion-parameter large language model achieve state-of-the-art enterprise performance while reducing its total parameter count by 33.3% and increasing pre-training efficiency by 49%? Yuan Lab AI releases Yuan3.0 Ultra, an open-source mixture-of-experts (MOE) large language model 1T total parameters And 68.8b active parameter. Model architectures are designed to optimize performance in enterprise-specific tasks while maintaining competitive general-purpose capabilities. Unlike traditional dense models, Yuan3.0 Ultra uses sparseness to increase capacity without linear increase in computational cost.
Layer-Adaptive Expert Pruning (LAEP)
Yuan3.0 is the primary innovation in Ultra’s training Layer-Adaptive Expert Pruning (LAEP) algorithm. While expert pruning is usually applied after training, LAEP identifies and removes underutilized experts directly during training. pre-training phase.
Research into expert load distribution revealed two distinct phases during pre-training:
- Initial infection stage: Characterized by high volatility in expert weights inherited from random initialization.
- Stationary Phase: Expert weights are aggregated, and the relative ranking of experts based on token assignments remains largely fixed.
Once stationary phase is reached, LAEP applies pruning based on two constraints:
- Personal Weight Constraint (⍺): Targets experts whose token load layer is well below average.
- Cumulative load constraint (β): Identifies the subgroup of experts who contributed the least to total token processing.
By applying LAEP with β=0.1 and varying ⍺, the model was reduced to the initial 1.5T parameters all the way down 1T parameter. it 33.3% decrease The aggregate parameters preserved the model’s multi-domain performance while significantly reducing memory requirements for deployment. In the 1T configuration, the number of experts per layer was reduced from 64 to the maximum 48 protected experts.
Hardware efficiency and expert rearrangement
MoE models often suffer from device-level load imbalance when experts are distributed across a computing cluster.. To address this, Yuan3.0 Ultra implements a Expert Rearrangement Algorithm.
This algorithm ranks experts based on token load and uses a greedy strategy to distribute them across GPUs so that the cumulative token variance is minimized..
| Method | TFLOPS per GPU |
| Base Model (1515B) | 62.14 |
| deepseek-v3 aux loss | 80.82 |
| Yuan3.0 Ultra (LAEP) | 92.60 |
Overall pre-training efficiency improved 49%. This improvement can be attributed to two factors:
- Model Pruning: Contribution 32.4% To achieve efficiency.
- Expert Rearrangement: Contribution 15.9% To achieve efficiency.
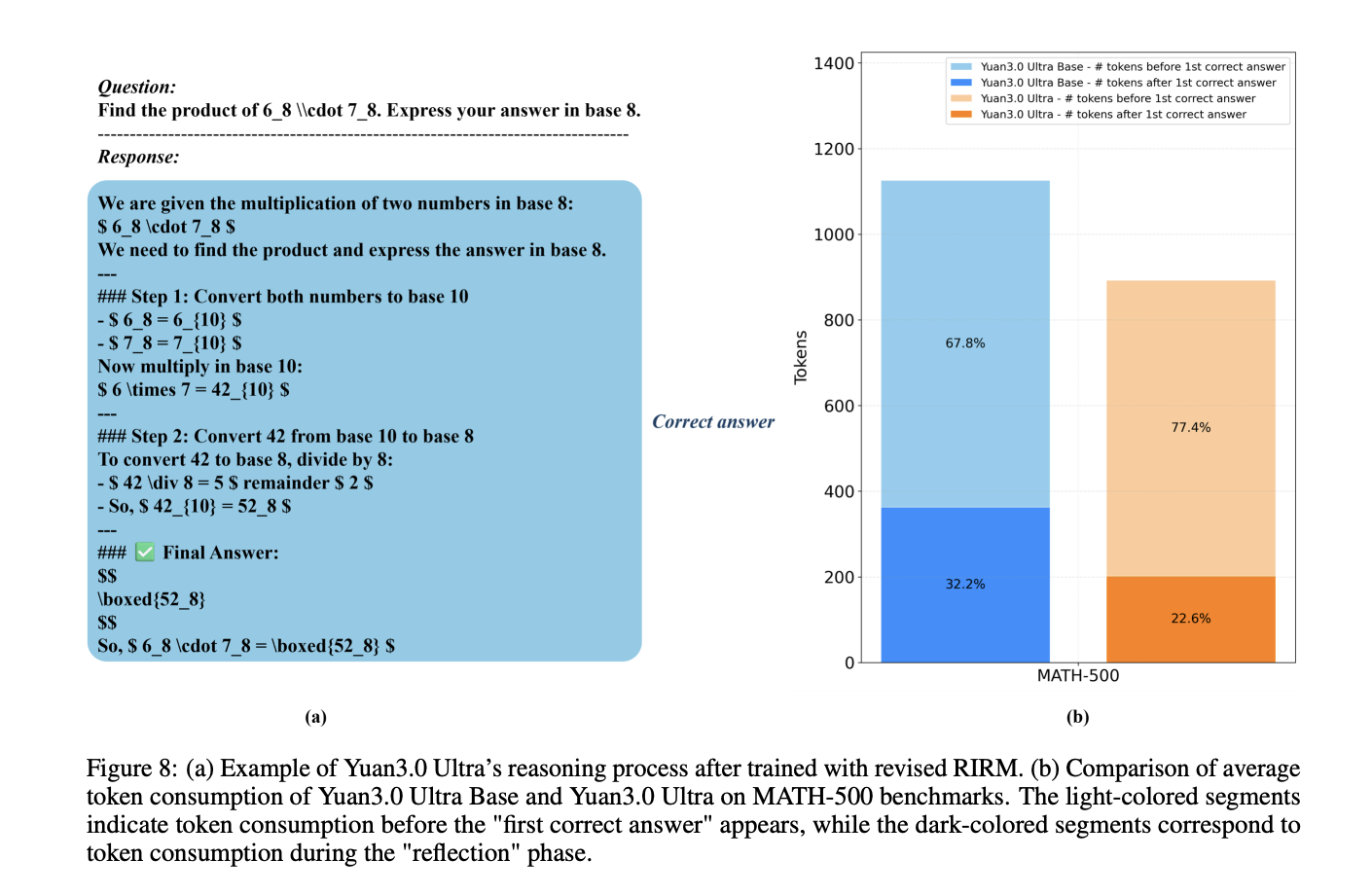
Reducing Overthinking with the Revised RIRM
In the reinforcement learning (RL) stage, the model employs a sophisticated Reflection Inhibition Reward Mechanism (RIRM) To prevent excessively long logic chains for simple functions.
The reward for reflection, $R_{ver}$, is calculated using a threshold-based penalty system: :
- Rmin=0: Ideal number of reflection steps for direct reactions.
- Rmaximum=3: Maximum tolerable reflectance limit.
For correct samples, the reward decreases as the reflection phase approaches R.maximumWhereas erroneous samples that ‘overthink’ (over R).maximum Receive maximum penalty. As a result of this mechanism a 16.33% gain in training accuracy and a 14.38% reduction in output token length.

enterprise benchmark performance
The Yuan3.0 Ultra was evaluated in specialized enterprise benchmarks against multiple industry models, including GPT-5.2 and Gemini 3.1 Pro..
| benchmark | Job Category | Yuan3.0 Ultra Score | leading competitor score |
| Docmatix | multimodal RAG | 67.4% | 48.4% (GPT-5.2) |
| ChatRAG | Text retrieval (average) | 68.2% | 53.6% (km K2.5) |
| mmtab | table logic | 62.3% | 66.2% (km K2.5) |
| Summary | lesson summarization | 62.8% | 49.9% (Cloud Opus 4.6) |
| spider 1.0 | text-to-sql | 83.9% | 82.7% (km K2.5) |
| BFCL V3 | device invocation | 67.8% | 78.8% (Gemini 3.1 Pro) |
The results show that Yuan3.0 achieves state-of-the-art accuracy in multimodal retrieval (DOCMATICS) and long-context retrieval (ChatRAG) while maintaining strong performance in ultra-structured data processing and tool calling..
check it out paper And repo. Also, feel free to follow us Twitter And don’t forget to join us 120k+ ml subreddit and subscribe our newsletter. wait! Are you on Telegram? Now you can also connect with us on Telegram.