

Businesses face a growing challenge: Customers want answers quickly, but support teams are overwhelmed. Support documents such as product manuals and knowledge base articles typically require users to search hundreds of pages, and support agents often run 20-30 customer queries per day to locate specific information.
This post demonstrates how to solve this challenge by creating an AI-powered website assistant using Amazon Bedrock and the Amazon Bedrock Knowledge Base. This solution is designed to benefit both internal teams and external customers, and can provide the following benefits:
- Quick, relevant answers for customers, reducing the need to search through documentation
- A powerful knowledge retrieval system for support agents, reducing resolution time
- 24/7 automated support
solution overview
The solution uses Retrieval-Augmented Generation (RAG) to extract relevant information from the knowledge base and return it based on the user’s access. It includes the following major components:
- Amazon Bedrock Knowledge Base – Content is crawled from the company’s website and stored in the knowledge base. Documents from Amazon Simple Storage Service (Amazon S3) buckets, including manuals and troubleshooting guides, are also indexed and stored in the knowledge base. With Amazon Bedrock Knowledge Base, you can configure multiple data sources and use filter configurations to distinguish between internal and external information. It helps protect internal data through advanced security controls.
- Amazon Bedrock Managed LLM – A large language model (LLM) from Amazon Bedrock generates AI-powered responses to user queries.
- Scalable Serverless Architecture , The solution uses Amazon Elastic Container Service (Amazon ECS) to host the UI and AWS Lambda functions to handle user requests.
- Automated CI/CD deployment – The solution uses AWS Cloud Development Kit (AWS CDK) to handle continuous integration and delivery (CI/CD) deployments.
The following figure shows the architecture of this solution.
The workflow includes the following steps:
- Amazon Bedrock Knowledge Base processes documents uploaded to Amazon S3 by segmenting and generating embeddings. Additionally, the Amazon Bedrock web crawler accesses selected websites to extract and consume their content.
- The web application runs as an ECS application. Internal and external users use browsers to access applications through Elastic Load Balancing (ELB). Users log in to the application using their login credentials registered in the Amazon Cognito user pool.
- When a user submits a query, the application invokes a Lambda function, which uses the Amazon Bedrock API to retrieve relevant information from the knowledge base. It also provides relevant data source IDs to Amazon Bedrock based on user type (external or internal) so that the knowledge base can retrieve information available only for that user type.
- Lambda functions invoke Amazon Nova Lite LLM to generate responses. The LLM leverages information from the knowledge base to generate a response to the user’s query, which is returned from a Lambda function and displayed to the user.
In the following sections, we demonstrate how to crawl and configure an external website as a knowledge base, and also upload internal documents.
Prerequisites
To deploy the solution in this post you must have the following:
Build a knowledge base and ingest website data
The first step is to create a knowledge base to ingest data from a website and operational documents from an S3 bucket. Complete the following steps to create your knowledge base:
- On the Amazon Bedrock console, select knowledge base under builder tools In the navigation pane.
- But create dropdown menu, select Knowledge Base with Vector Store,
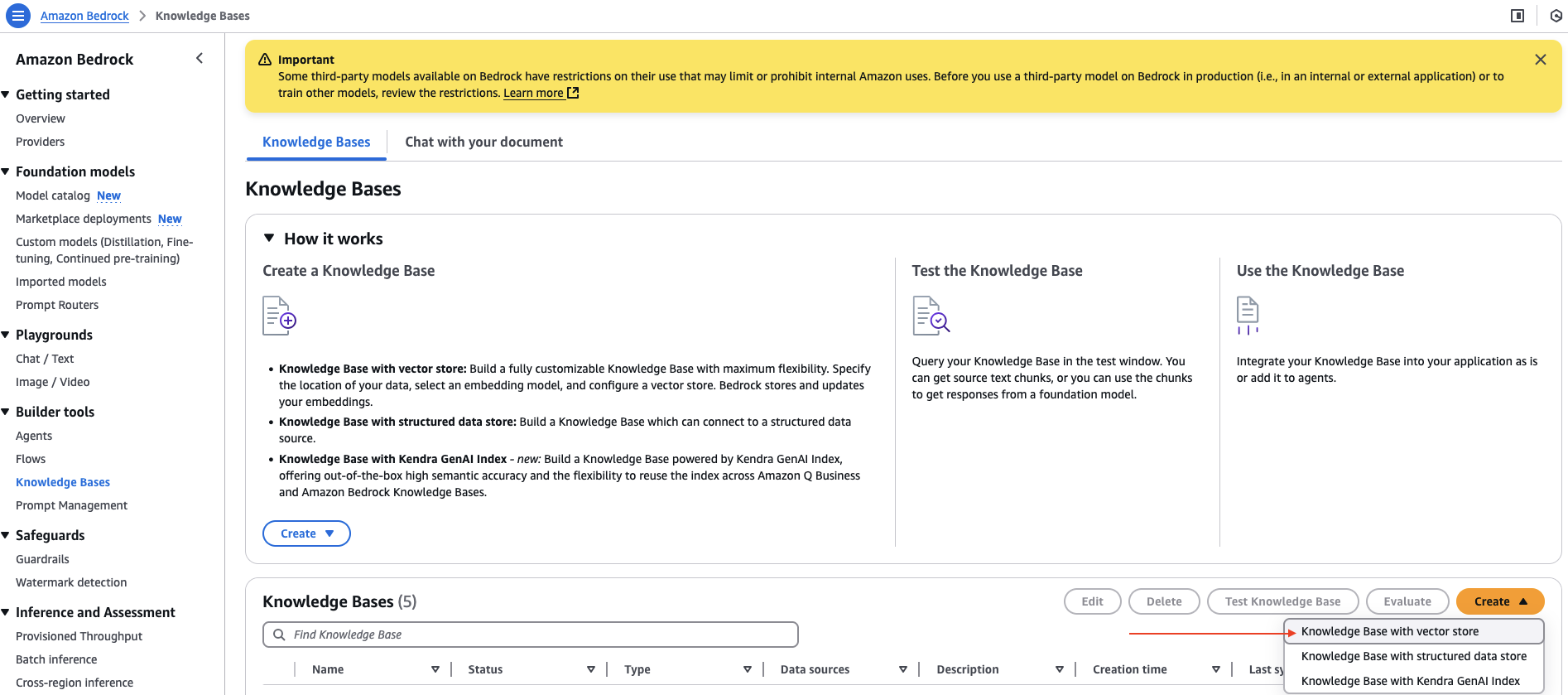
- For name of encyclopediaenter a name.
- For Select a data sourcechoose web crawler,
- choose next,
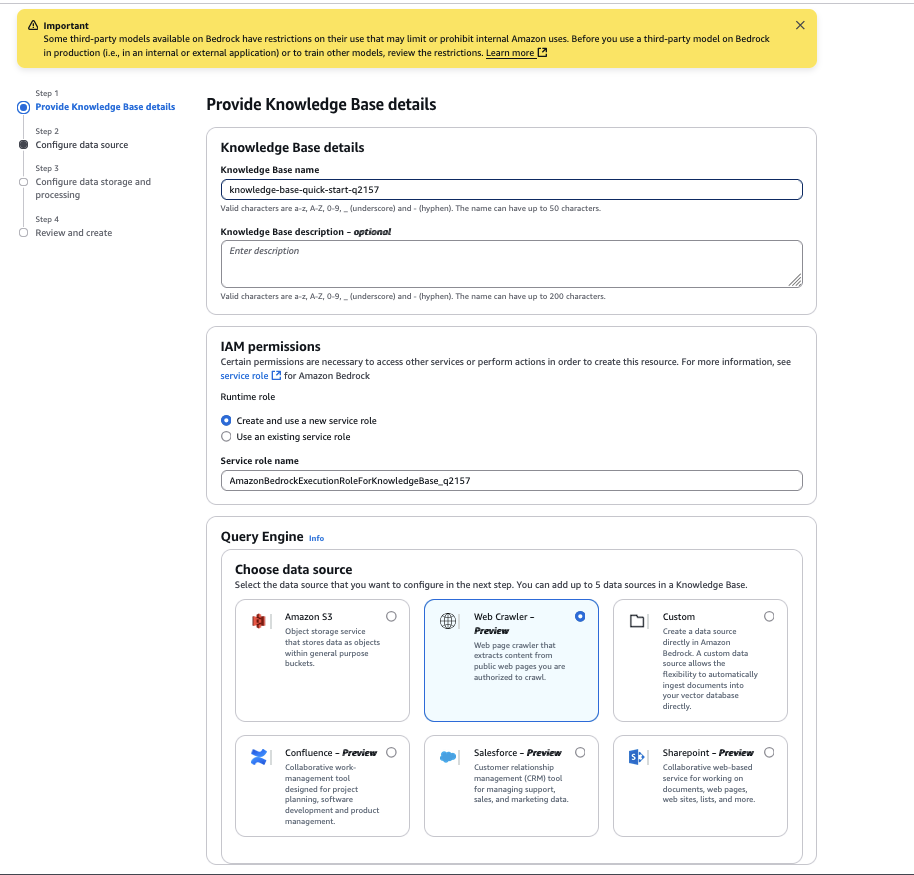
- For data source nameEnter a name for your data source.
- For source urlEnter the target website HTML page to crawl. For example, we use
https://docs.aws.amazon.com/AmazonS3/latest/userguide/GetStartedWithS3.html, - For website domain rangechoose default As the scope of creep. You can also configure it to only host domains or subdomains if you want to limit crawling to a specific domain or subdomain.
- For url regex filterYou can configure URL patterns to include or exclude specific URLs. For this example, we leave this setting blank.
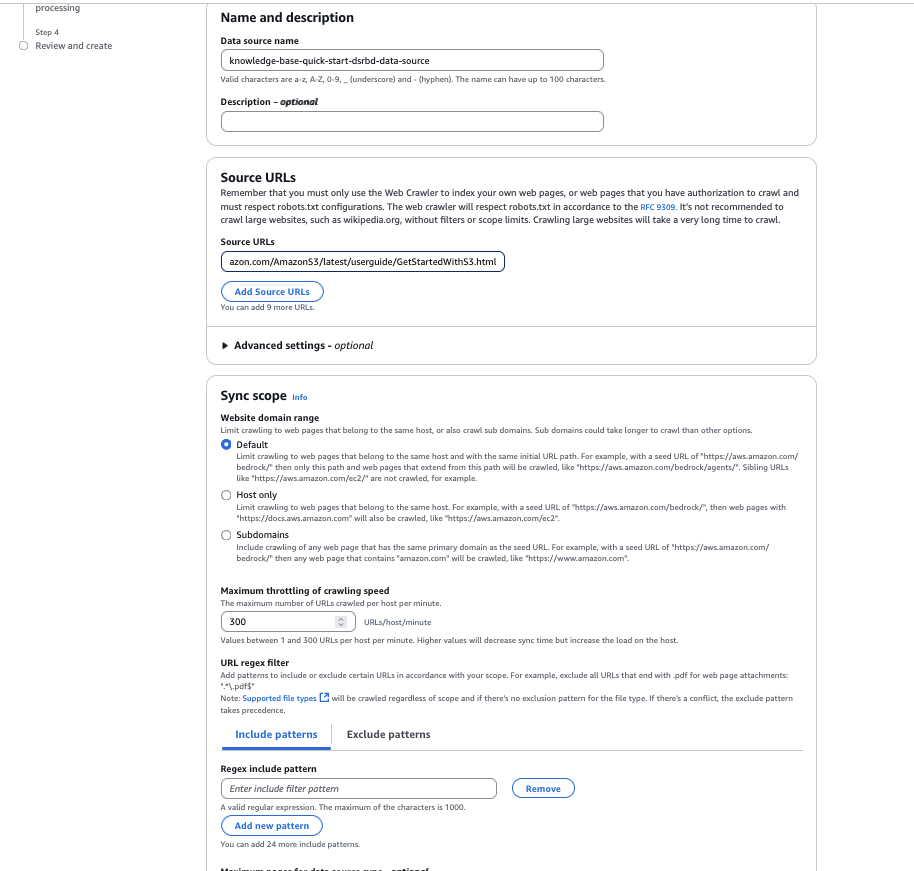
- For fragmentation strategyYou can configure content parsing options to customize the data chunking strategy. For this example, we leave it as is default chunking,
- choose next,
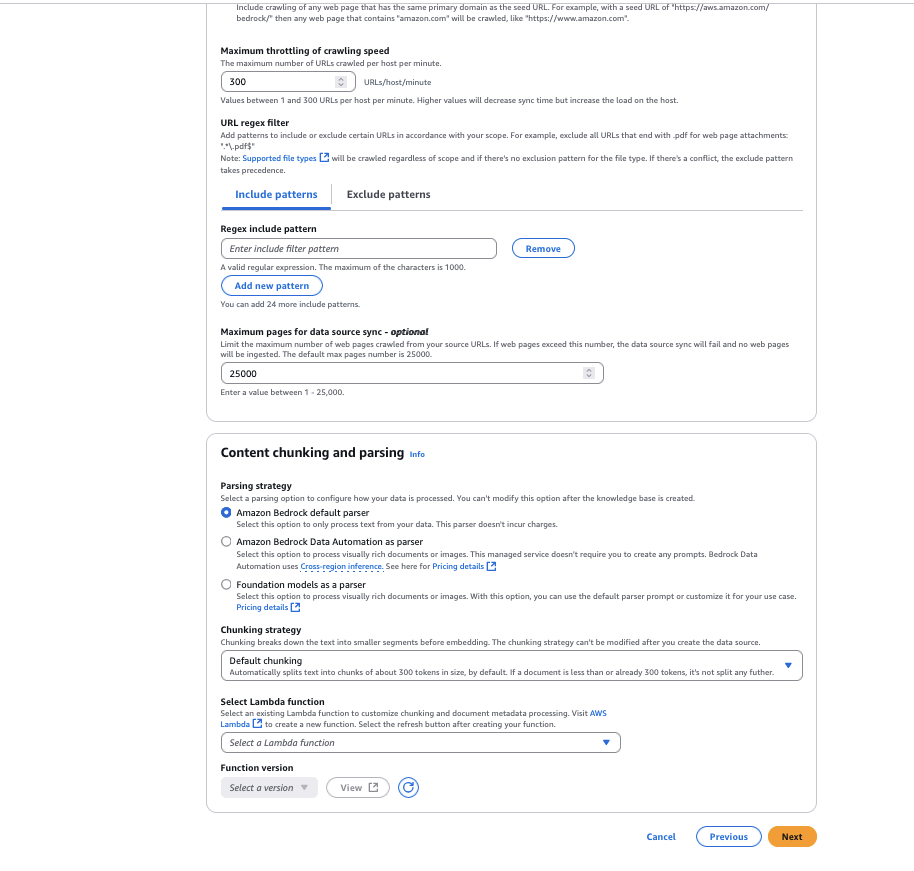
- Select the Amazon Titan Text Embedding V2 model, then select apply,
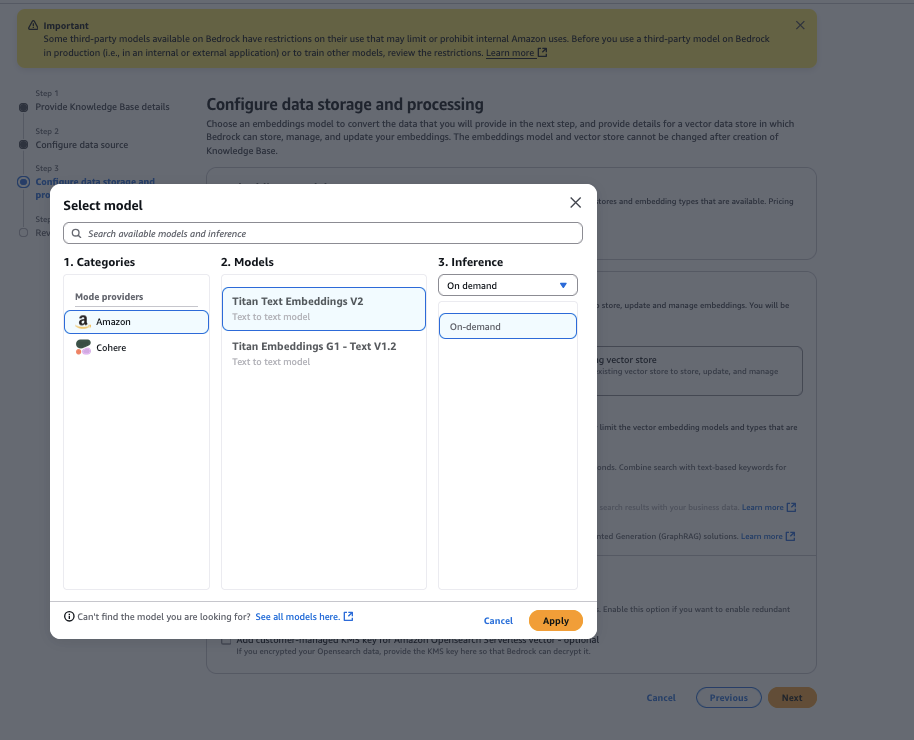
- For vector store typechoose Amazon OpenSearch Serverlessthen choose next,
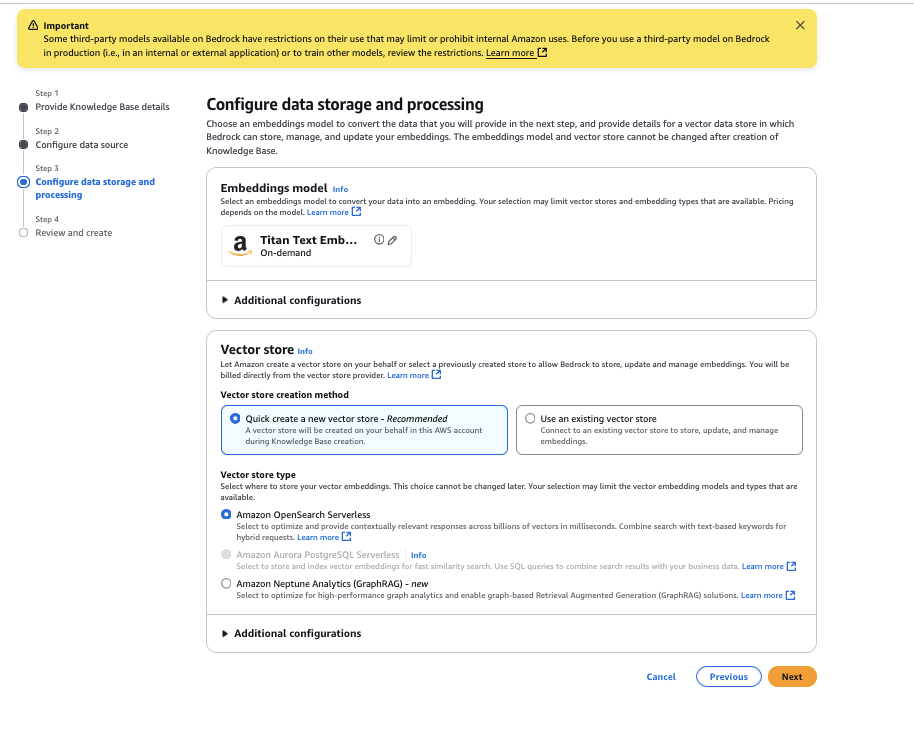
- Review and select configuration create knowledge base,
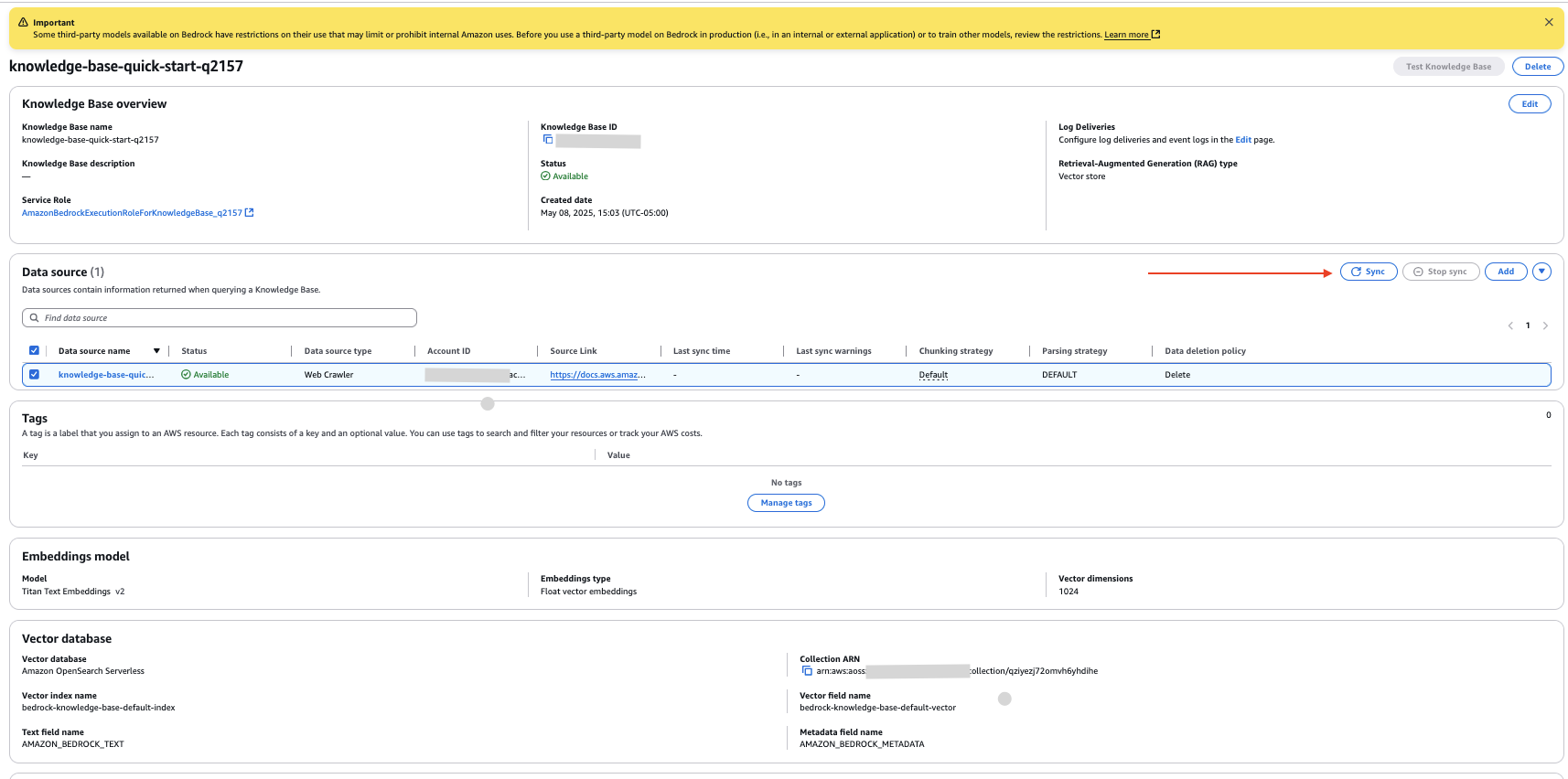
You have now created a knowledge base with the data source configured as the website link you provided.
- On the knowledge base details page, select your new data source and select to do together To crawl the website and capture data.
Configure Amazon S3 data source
Complete the following steps to configure documents from your S3 bucket as an internal data source:
- On the knowledge base details page, select Add In data source Section.
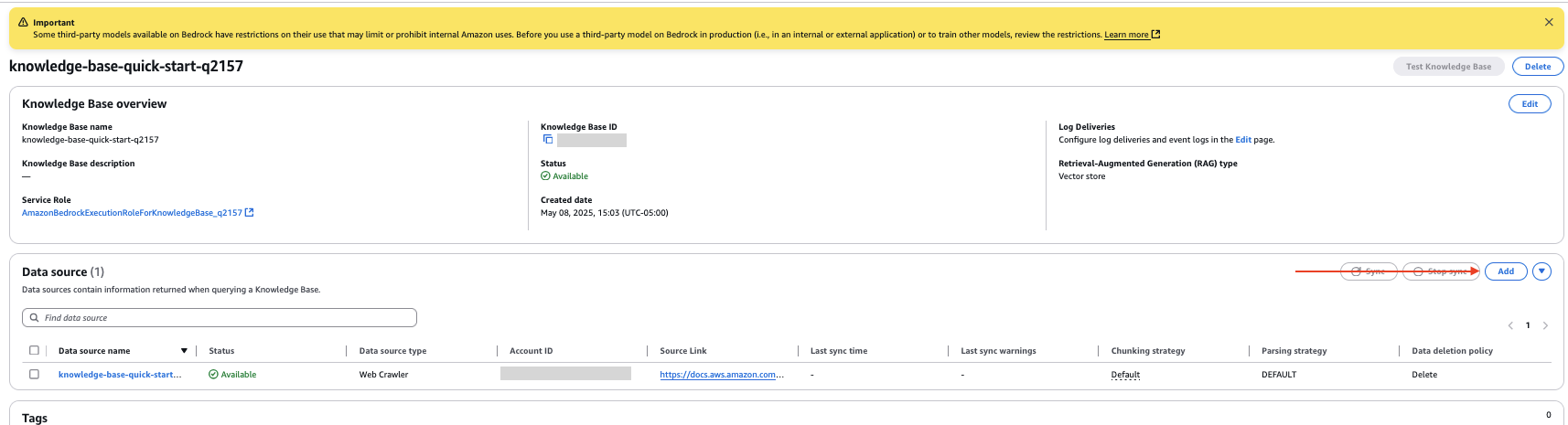
- Specify the data source as Amazon S3.
- Select your S3 bucket.
- Leave the parsing strategy as the default setting.
- choose next,
- Review and select configuration Add data source,
- In data source In the Knowledge Base Details section of the page, select your new data source and select to do together To index data from documents in an S3 bucket.
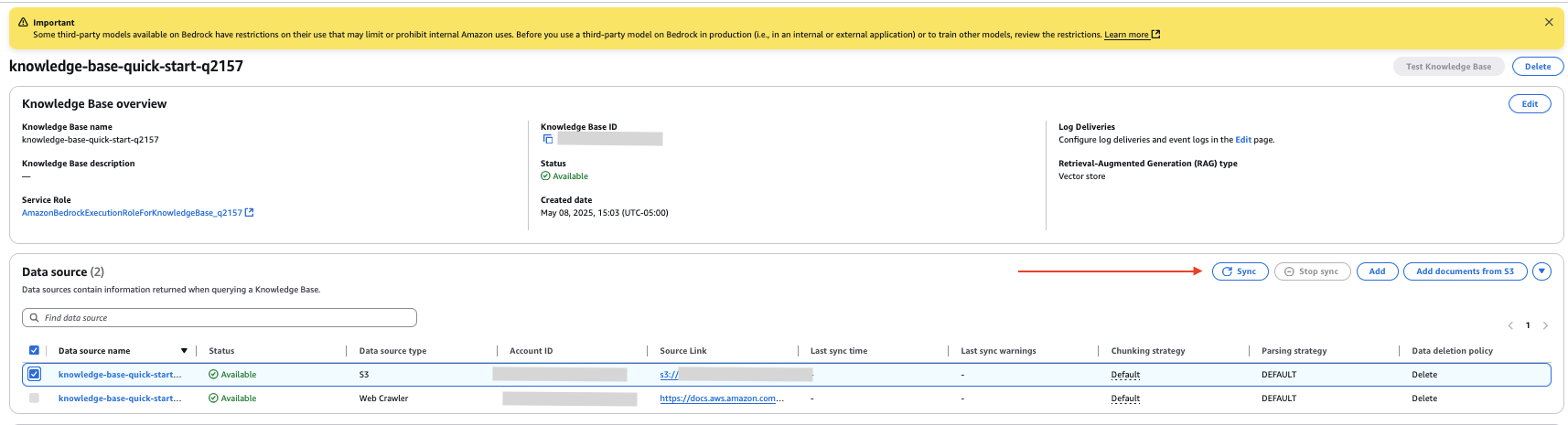
Upload Internal Document
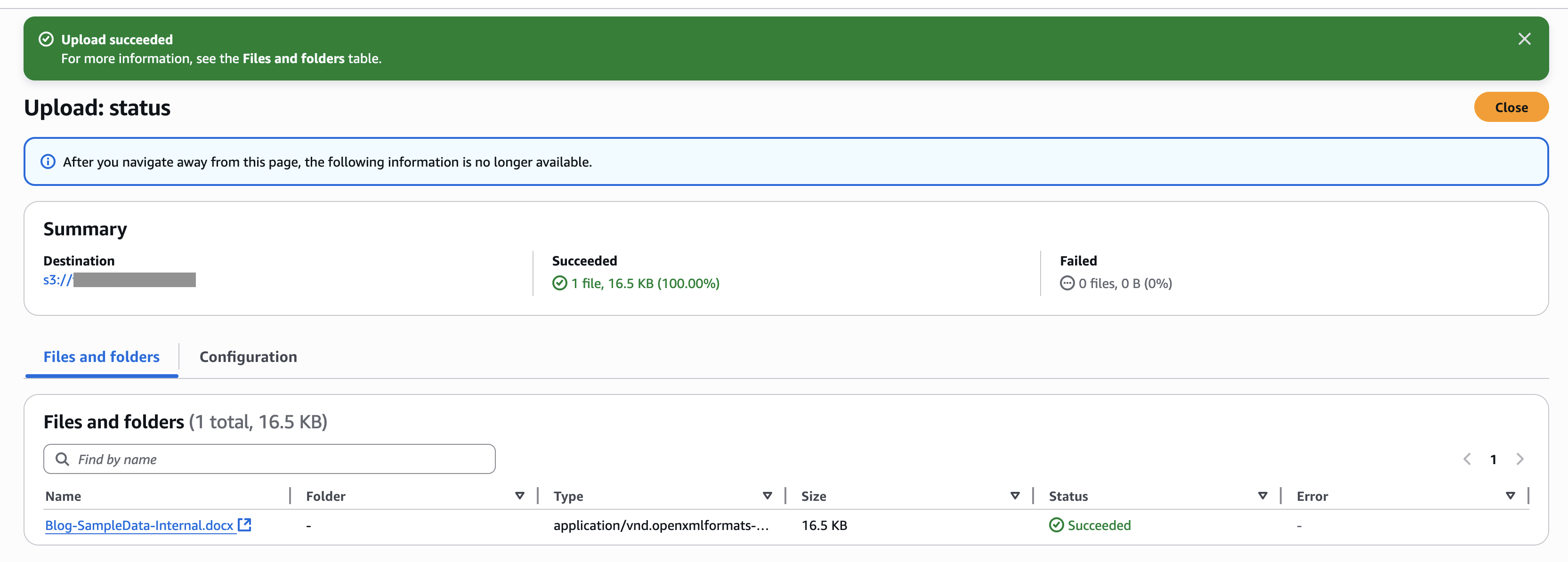
For this example, we upload a document to the new S3 bucket data source. The following screenshot shows an example of our document.

Complete the following steps to upload documents:
- On the Amazon S3 console, select Bucket In the navigation pane.
- Select the bucket you created and choose upload To upload documents.
- On the Amazon Bedrock console, go to the knowledge base you created.
- Select the internal data source you created and select to do together To sync the uploaded document with the Vector Store.
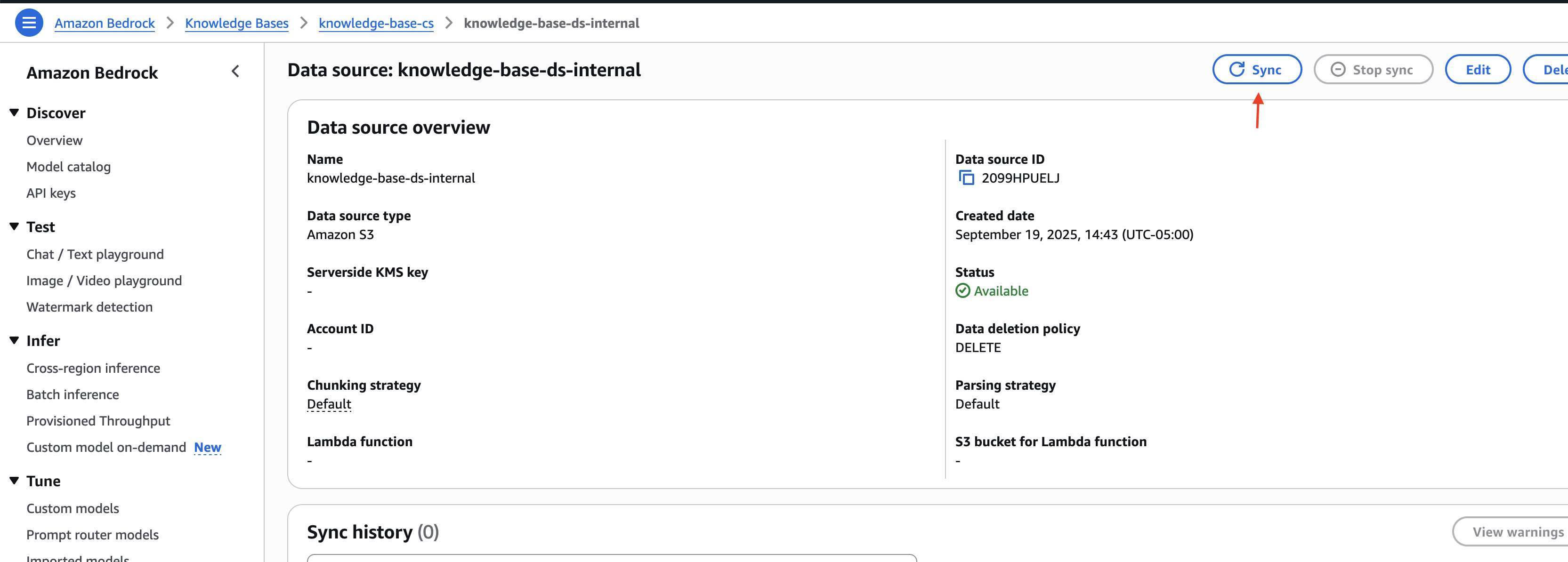
Note the knowledge base ID and data source ID for external and internal data sources. You use this information in the next step when deploying the solution infrastructure.
Deploy solution infrastructure
To deploy the solution infrastructure by using AWS CDK, complete the following steps:
- download code from code repository,
- Go to iac directory inside the downloaded project:
cd ./customer-support-ai/iac
- Open the parameters.json file and update the knowledge base and data source IDs with the values captured in the previous section:
- Follow the deployment instructions defined in the customer-support-ai/README.md file to install the solution infrastructure.
When the deployment is complete, you can find the Application Load Balancer (ALB) URL and demo user details in the script execution output.
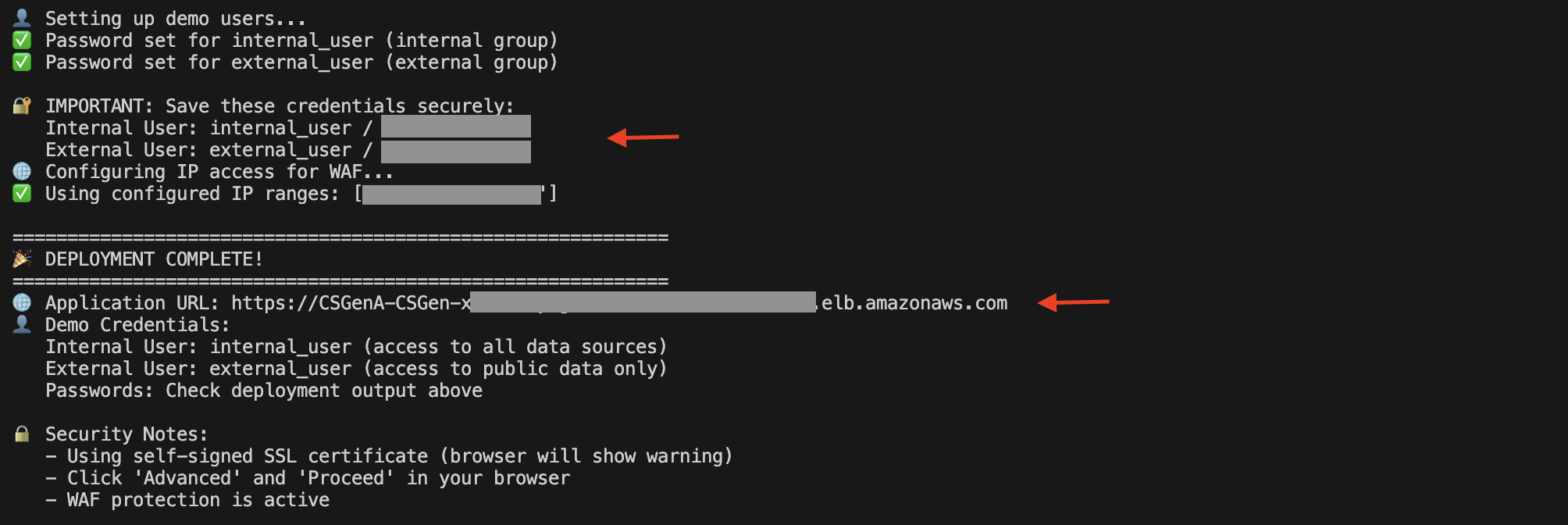
You can also open the Amazon EC2 console and select load balancers In the navigation pane to view the ALB.

On the ALB details page, copy the DNS name. You can use this to access the UI to try out the solution.

Submit Question
Let’s look at an example of Amazon S3 service support. This solution supports a variety of users to help resolve their queries by using Amazon Bedrock Knowledge Base to manage specific data sources (such as website content, documentation, and support tickets) with built-in filtering controls that separate internal operational documents from publicly accessible information. For example, internal users can access both company-specific operational guides and public documentation, while external users are limited to only publicly available content.
Open the DNS URL in the browser. Enter and select external user credentials log in,

After you are successfully authenticated, you will be redirected to the home page.
choose Support AI Assistant In the navigation pane to ask questions related to Amazon S3. The Assistant can provide relevant responses based on the information available in the Getting Started with Amazon S3 guide. However, if an external user asks a question that pertains to information available only to internal users, the AI assistant will not provide internal information to the user and will only respond with information available to external users.
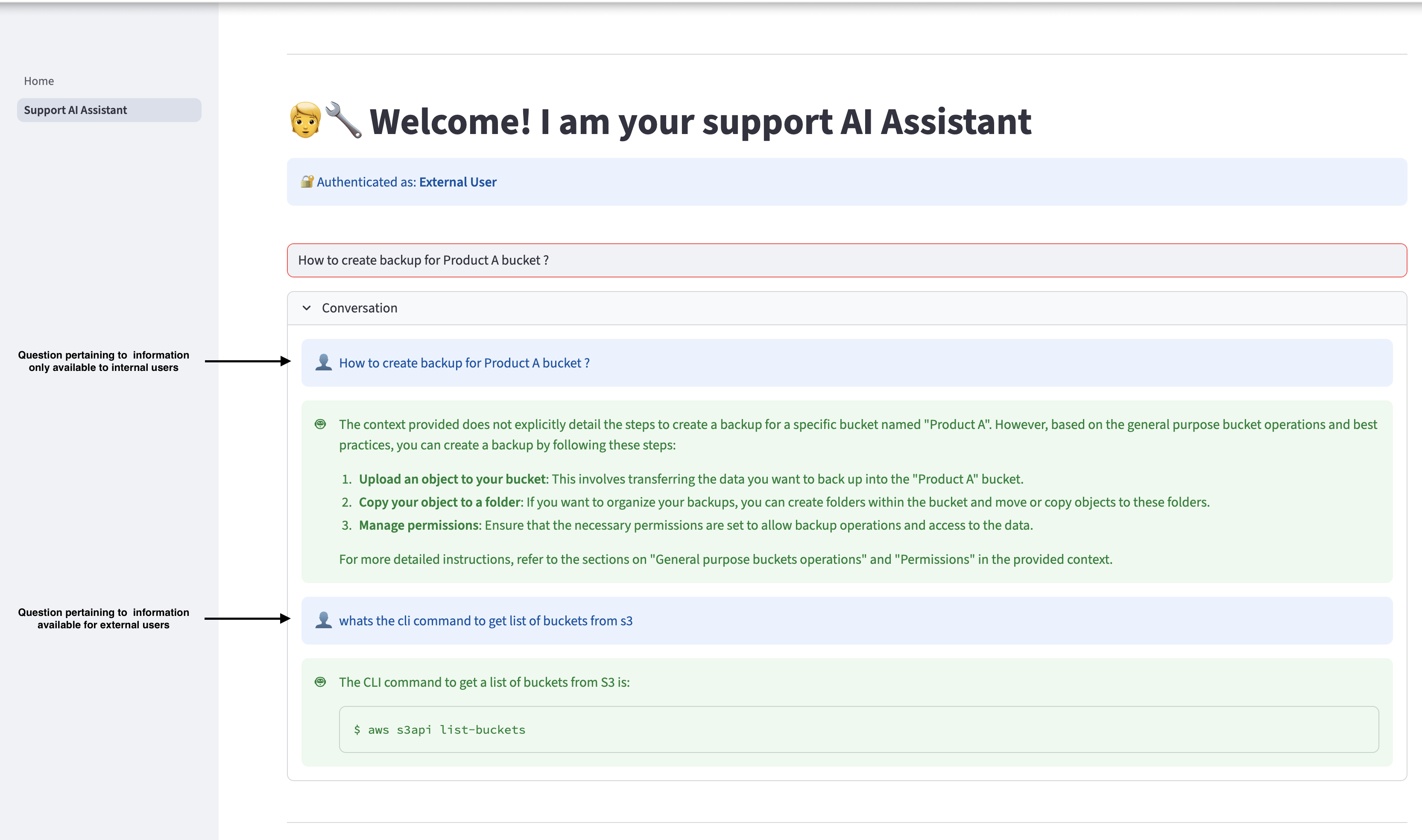
Log out and log in again as an internal user, and ask the same question. Internal users can access relevant information available in internal documents.

cleanliness
If you decide to stop using this solution, complete the following steps to remove its associated resources:
- Go to the iac directory inside the project code and run the following command from the terminal:
- To run the cleanup script, use the following command:
- To perform this operation manually, use the following command:
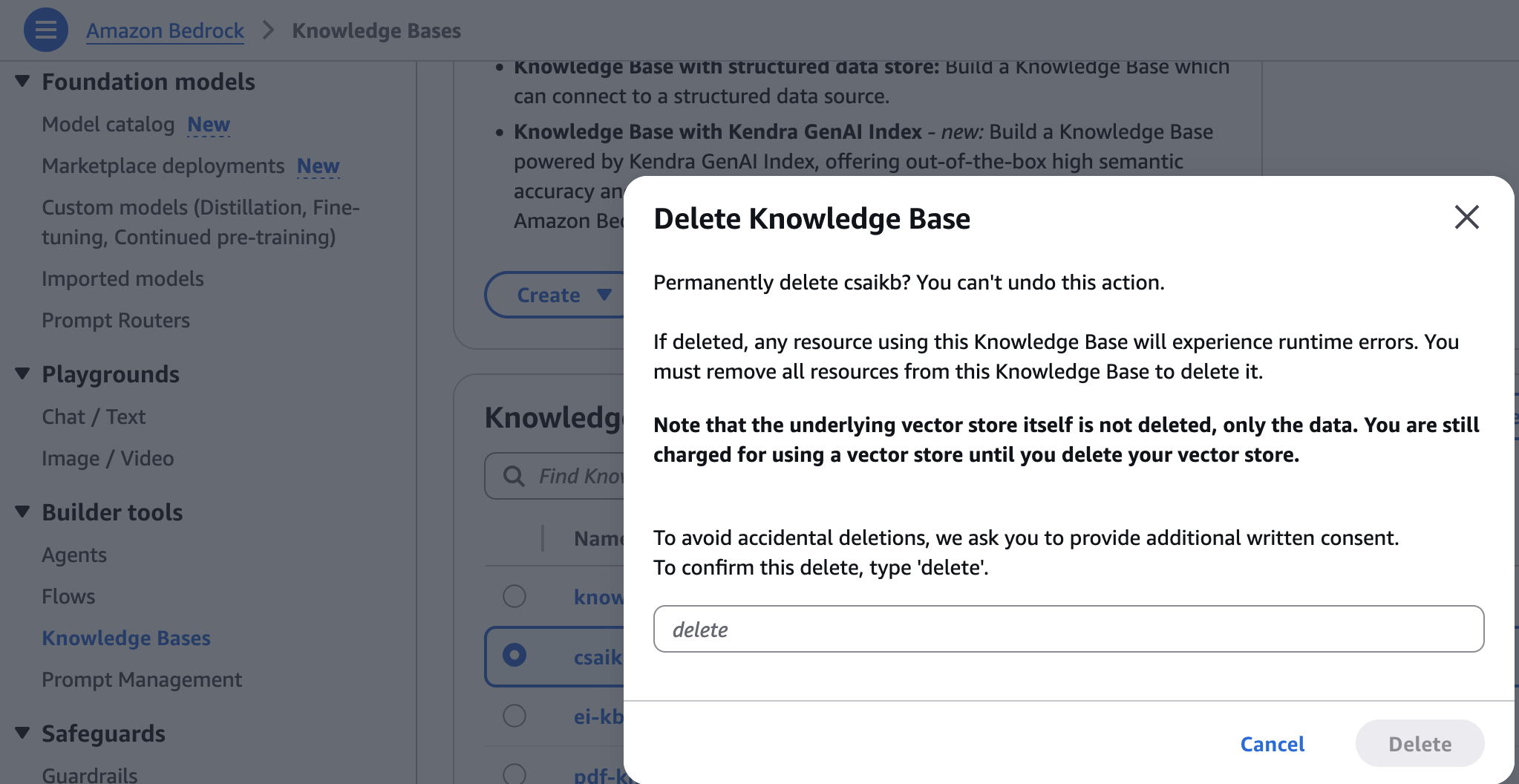
- On the Amazon Bedrock console, select knowledge base under builder tools In the navigation pane.
- Select the knowledge base you created, then select delete,
- Enter and select delete delete To confirm.
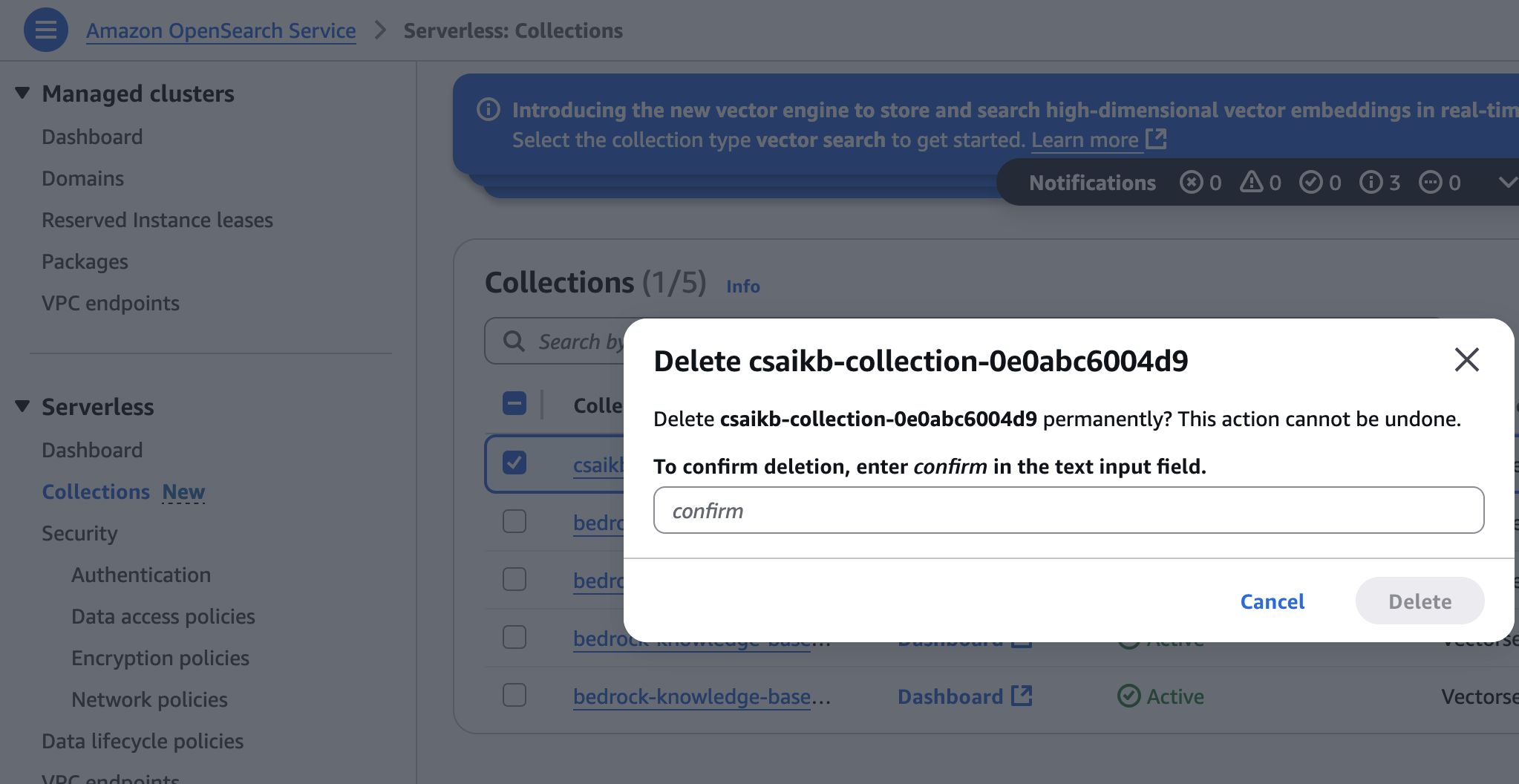
- On the OpenSearch service console, select Collection under serverless In the navigation pane.
- Select the archive created during infrastructure provisioning, then select delete,
- Enter and select Confirm delete To confirm.
conclusion
This post shows how to create an AI-powered website assistant to quickly find information by building a knowledge base through web crawling and document uploading. You can use the same approach to develop other generative AI prototypes and applications.
If you’re interested in working with FM, including the fundamentals of Generative AI and advanced prompting techniques, check out the hands-on course. Generative AI with LLMThis on-demand, 3-week course is for data scientists and engineers who want to learn how to build generative AI applications with an LLM, This is a good foundation to start building with Amazon Bedrock, Sign up To learn more about Amazon Bedrock.
About the authors
 Shashank Jain is a Cloud Application Architect at Amazon Web Services (AWS), specializing in generative AI solutions, cloud-native application architecture, and sustainability. He works with clients to design and implement secure, scalable AI-powered applications using serverless technologies, modern DevSecOps practices, infrastructure as code, and event-driven architectures that deliver measurable business value.
Shashank Jain is a Cloud Application Architect at Amazon Web Services (AWS), specializing in generative AI solutions, cloud-native application architecture, and sustainability. He works with clients to design and implement secure, scalable AI-powered applications using serverless technologies, modern DevSecOps practices, infrastructure as code, and event-driven architectures that deliver measurable business value.
 jeff lee is a Senior Cloud Applications Architect with the Professional Services team at AWS. He is passionate about connecting deeply with customers to create solutions and modernize applications that support business innovations. In his free time, he enjoys playing tennis, listening to music, and reading.
jeff lee is a Senior Cloud Applications Architect with the Professional Services team at AWS. He is passionate about connecting deeply with customers to create solutions and modernize applications that support business innovations. In his free time, he enjoys playing tennis, listening to music, and reading.
 Ranjith Kurumbaru Kandiyil Data and AI/ML Architect at Amazon Web Services (AWS), based in Toronto. He specializes in collaborating with clients to design and implement cutting-edge AI/ML solutions. His current focus is on leveraging cutting-edge artificial intelligence technologies to solve complex business challenges.
Ranjith Kurumbaru Kandiyil Data and AI/ML Architect at Amazon Web Services (AWS), based in Toronto. He specializes in collaborating with clients to design and implement cutting-edge AI/ML solutions. His current focus is on leveraging cutting-edge artificial intelligence technologies to solve complex business challenges.