

Estimate scaling has become one of the most effective methods to improve the quality and accuracy of answers in deployed LLMs.
The idea is simple. If we are willing to do a little more computation and spend more time at inference time (when we use the model to generate text), we can get the model to give better answers.
Every major LLM provider today relies on some flavor of estimate-time scaling. And the academic literature related to these methods has also increased greatly.
In March, I wrote an overview of the estimate scaling landscape and summarized some introductory techniques.
LLM Reasoning Model Estimation Status
In this article, I want to take that previous discussion a step further, group the different approaches into clear categories, and highlight the latest work that has emerged over the past few months.
Estimates as part of drafting a full book chapter on scaling Build a Reasoning Model (From Scratch)I ended up experimenting with several basic flavors of these recipes myself. With hyperparameter tuning, this quickly turned into thousands of runs and a lot of thought and work went into figuring out which approaches should be covered in more detail in the chapter. (The chapter grew so much that I eventually split it into two parts, and both are now available in the Early Access program.)
PS: I’m particularly happy with the outcome of the chapter. This takes the base model from about 15 percent to about 52 percent accuracy, making it one of the most rewarding pieces of the book so far.
What’s here is a collection of ideas, notes, and papers that didn’t quite fit into the story of the final chapter but are still worth sharing.
I also plan to add more code implementations to this Bonus Content on GitHub For longer periods of time.
Table of Contents (Overview)
-
estimation-time scaling overview
-
Chain-of-thought prompting
-
self stability
-
Best-of-n ranking
-
Rejection sampling with a validator
-
self-refinement
-
Search on solution paths
-
Conclusion, Categories and Combinations
-
Bonus: What do proprietary LLMs use?
You can use the navigation bar on the left in the web view of the article to jump to any section.
estimation-time scaling (also called heuristic scaling, test-time scalingor bus estimate scaling) is a broad term for methods that allocate more computation and time during inference to improve model performance.
This idea has been around for a long time, and one can think of combinatorial methods in classic machine learning as an early example of estimation-time scaling. That is, using multiple models requires more computing resources but may yield better results.
Even in LLM contexts, this idea has been around for a long time. However, I remember it became especially popular (again) when OpenAI showed an inference-time scaling and training plot in one of their o1 announcement blog articles last year (Learning to Reason with LLM).
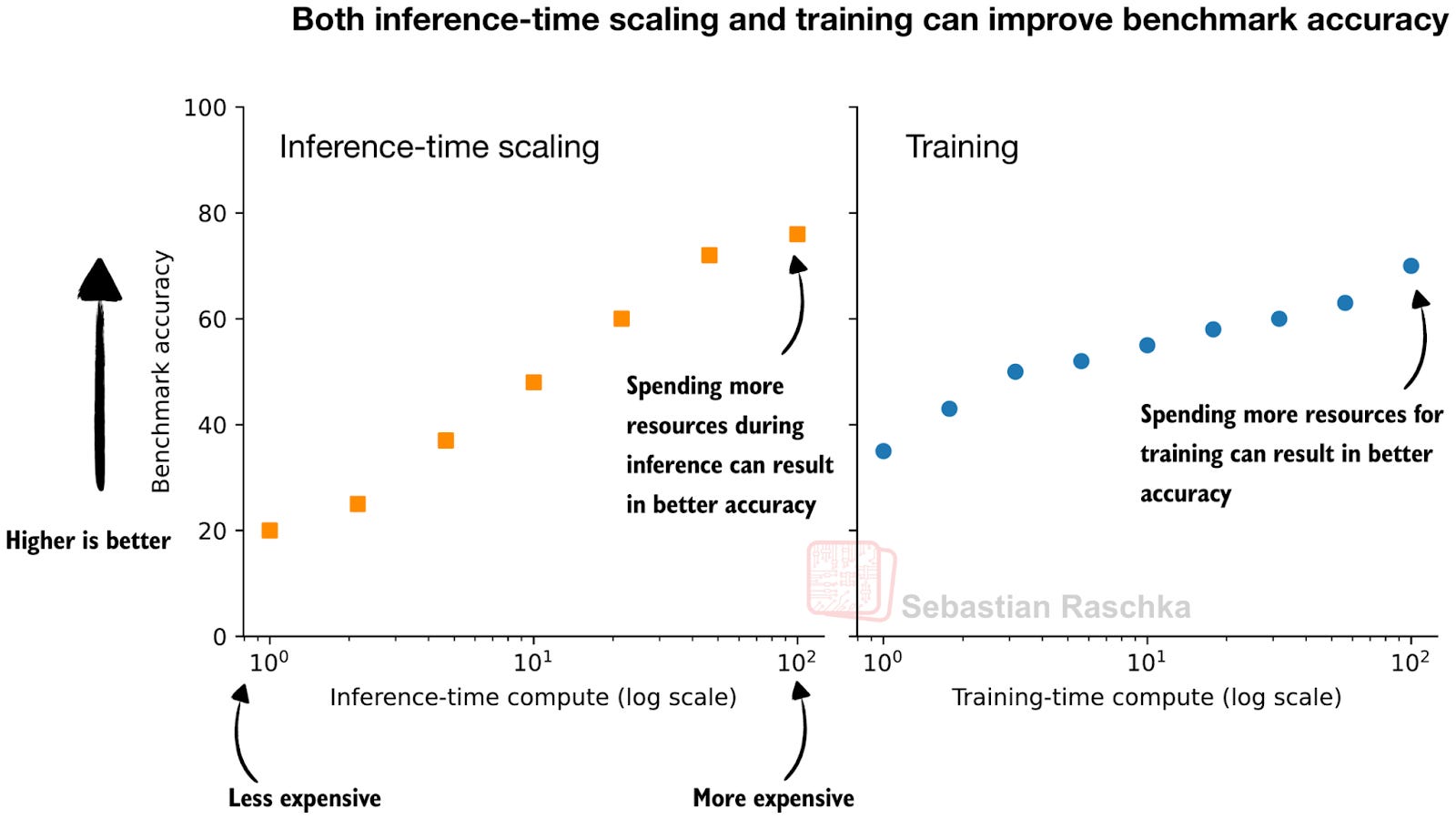
This figure, I think, is adapted from OpenAI blog postWell illustrates the idea behind the two knobs that we can use to improve LLM. We can spend more resources (more data, larger models, more or longer training steps) or inference during training.
In fact, in practice, it is even better to do both at the same time: train a stronger model and use additional inference scaling to make it even better.
In this article, I focus only on the left part of the figure, inference-time scaling techniques, that is, on training-free techniques that do not change the model weights.