

Topic modeling uncovers hidden topics in large document collections. Traditional methods such as latent Dirichlet allocation rely on word frequency and treat text as a bag of words, often missing deeper context and meaning.
BERTopic takes a different approach by combining Transformer embeddings, clustering, and C-TF-IDF to capture the semantic relationships between documents. This produces more meaningful, context-aware topics suitable for real-world data. In this article, we will explain how BERTopic works and how you can implement it step by step.
What is Burtopic?
BERTopic is a modular topic modeling framework that treats topic discovery as a pipeline of independent but connected steps. It integrates deep learning and classical natural language processing techniques to produce coherent and explainable topics.
The main idea is to transform documents into semantic embeddings, cluster them based on similarity, and then extract representative words for each cluster. This approach allows BERTopic to capture both meaning and structure within text data.
At a high level, BERTopic follows this process:
Every component of this pipeline can be modified or replaced, making BERTopic highly flexible for different applications.
Key components of the BERTopic pipeline
1. Preprocessing
The first step involves preparing the raw text data. Unlike traditional NLP pipelines, BERTopic does not require heavy preprocessing. Minimal cleanup, such as lowercasing, removing extra spaces, and filtering out very small documents, is usually sufficient.
2. Document Embedding
Each document is transformed into a dense vector using a transformer-based model such as SentenceTransformers. This allows the model to capture semantic relationships between documents.
Mathematically:
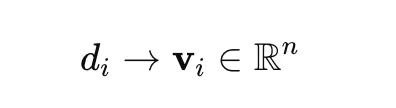
where dI is a document and vI Its vector representation is.
3. Dimensionality Reduction
High-dimensional embeddings are difficult to cluster effectively. BERTopic uses UMAP to reduce dimensionality while preserving the structure of the data.
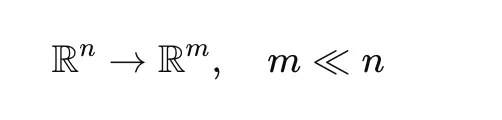
This step improves clustering performance and computational efficiency.
4. Clustering
After dimensionality reduction, clustering is done using HDBSCAN. This algorithm groups similar documents into groups and identifies outliers.
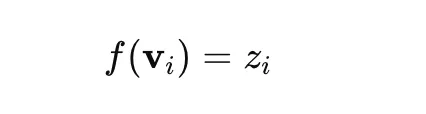
where zI The specified topic is labeled. Documents labeled as -1 Are considered outliers.
5. C-TF-IDF Subject Representation
Once the clusters are created, BERTopic generates topic representations using c-TF-IDF.
Period Frequency:
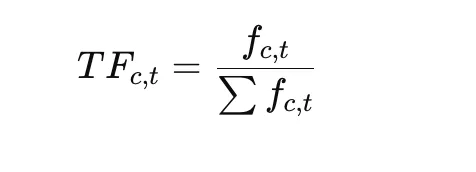
Inverse square frequency:
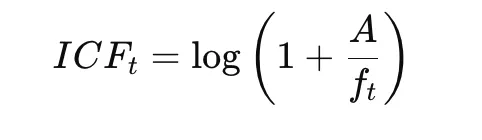
Final C-TF-IDF:
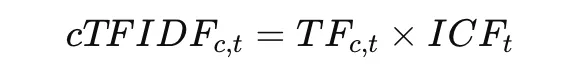
This method highlights words that are specific within a group while downplaying the importance of words common across groups.
hands-on implementation
This section demonstrates a simple implementation of BERTopic using a very small dataset. The goal here is not to create production-level topic models, but to understand how BERTopic works step by step. In this example, we preprocess the text, configure UMAP and HDBSCAN, train the BERTopic model, and inspect the generated topics.
Step 1: Import the Library and Prepare the Dataset
import re
import umap
import hdbscan
from bertopic import BERTopic
docs = (
"NASA launched a satellite",
"Philosophy and religion are related",
"Space exploration is growing"
) In this first step, the required libraries are imported. The re module is used for basic text preprocessing, while umap and hdbscan are used for dimensionality reduction and clustering. BERTopic is the main library that connects these components into a topic modeling pipeline.
A short list of sample documents is also created. These documents relate to different topics, such as space and philosophy, which makes them useful for demonstrating how BERTopic attempts to separate text into different topics.
Step 2: Preprocess the text
def preprocess(text):
text = text.lower()
text = re.sub(r"s+", " ", text)
return text.strip()
docs = (preprocess(doc) for doc in docs)This step performs basic text cleaning. Each document is converted to lowercase so that words like “NASA” and “NASA” are treated as a single token. Extra spaces are also removed to standardize the formatting.
Preprocessing is important because it reduces the noise in the input. Although BERTopic uses Transformer embeddings that rely less on heavy text cleaning, simple normalization still improves stability and makes the input cleaner for downstream processing.
Step 3: Configure UMAP
umap_model = umap.UMAP(
n_neighbors=2,
n_components=2,
min_dist=0.0,
metric="cosine",
random_state=42,
init="random"
)UMAP is used here to reduce the dimensionality of document embeddings before clustering. Since embeddings are usually high-dimensional, it is often difficult to cluster them directly. UMAP helps by projecting them into a lower-dimensional space while preserving their semantic relationships.
The parameter init=”random” is especially important in this example because the dataset is extremely small. With only three documents, UMAP’s default spectral initialization may fail, so random initialization is used to avoid that error. The settings n_neighbors=2 and n_components=2 are chosen to suit this small dataset.
Step 4: Configure HDBSCAN
hdbscan_model = hdbscan.HDBSCAN(
min_cluster_size=2,
metric="euclidean",
cluster_selection_method="eom",
prediction_data=True
)HDBSCAN is the clustering algorithm used by BERTopic. Its role is to group similar documents together after dimensionality reduction. Unlike methods such as K-means, HDBSCAN does not need to specify the number of clusters in advance.
Here, minimum_cluster_size=2 This means that at least two documents are required to form a cluster. This is appropriate for such a small example. prediction_data = true The logic allows the model to retain useful information for later inference and probability estimation.
Step 5: Create BERTopic Model
topic_model = BERTopic(
umap_model=umap_model,
hdbscan_model=hdbscan_model,
calculate_probabilities=True,
verbose=True
) In this step, the BERTopic model is built by passing the custom UMAP and HDBSCAN configuration. This reflects one of the strengths of BERTopic: it is modular, so individual components can be customized according to the dataset and use case.
The option Calcul_probability=True enables the model to estimate topic probabilities for each document. The Verbose=True option is useful during experimentation because it displays the progress and internal processing steps while the model is running.
Step 6: Fit the BERTopic Model
topics, probs = topic_model.fit_transform(docs) This is the main training phase. BERTopic now executes the entire pipeline internally:
- It converts documents into embeddings
- It reduces embedding dimensions using UMAP
- It clusters reduced embeddings using HDBSCAN
- It extracts topic words using C-TF-IDF
The result is stored in two outputs:
- Subject, which contains the subject label specified for each document
- Probe, which contains probability distributions or confidence values for the assignment
This is the point where the raw documents are converted into a topic-based structure.
Step 7: View subject assignments and subject information
print("Topics:", topics)
print(topic_model.get_topic_info())
for topic_id in sorted(set(topics)):
if topic_id != -1:
print(f"nTopic {topic_id}:")
print(topic_model.get_topic(topic_id))
This last step is used to inspect the output of the model.
print("Topics:", topics)Shows the topic label assigned to each document.get_topic_info()Displays a summary table of all topics, including topic IDs and the number of documents in each topic.get_topic(topic_id)Returns the top representative words for a given topic.
The condition if subject_id != -1 excludes outliers. In BERTopic, a topic label of -1 means that the document was not assigned to any cluster with confidence. This is a common behavior in density-based clustering and helps to avoid putting unrelated documents into the wrong topics.
Benefits of BERTopic
Here are the main benefits of using BERTopic:
- Captures semantic meaning using embeddings
BERTopic uses transformer-based embeddings to understand the context of text rather than just word frequency. This allows it to group documents with similar meaning, even if they use different words. - Automatically determines the number of subjects
Using HDBSCAN, BERTopic does not require a predefined number of topics. It explores the natural structure of data, making it suitable for unknown or growing datasets. - Handles noise and outliers effectively
Documents that do not clearly belong to any cluster are labeled as outliers instead of being included in the wrong topics. This improves the overall quality and clarity of the topics. - Creates interpretable subject representations
With C-TF-IDF, BERTopic extracts keywords that clearly represent each topic. These terms are specific and easy to understand, making interpretation simple. - Highly modular and customizable
Each part of the pipeline can be adjusted or replaced, such as embeddings, clustering, or vectorization. This flexibility allows it to adapt to different datasets and use cases.
conclusion
BERTopic represents a significant advancement in topic modeling by combining semantic embeddings, dimensionality reduction, clustering, and class-based TF-IDF. This blended approach allows it to produce meaningful and interpretable themes that more closely match human understanding.
Instead of relying solely on word frequency, BERTopic takes advantage of the structure of the semantic space to identify patterns in text data. Its modular design makes it well suited for a wide range of applications, from analyzing customer feedback to organizing research documents.
In practice, the effectiveness of BERTopic depends on careful selection of embeddings, tuning of clustering parameters, and thoughtful evaluation of the results. When implemented correctly, this theme provides a powerful and practical solution to modern modeling tasks.
Frequently Asked Questions
A. It uses semantic embeddings rather than word frequency, allowing it to capture context and meaning more effectively.
A. It uses HDBSCAN clustering, which automatically detects the natural number of subjects without predefined inputs.
A. It is computationally expensive due to embedding generation, especially for large datasets.
![]()
Hi, I am Janvi, a passionate woman interested in Data Science currently working in Analytics Vidya. My journey into the world of data began with a deep curiosity about how we can extract meaningful insights from complex datasets.
Login to continue reading and enjoy expertly curated content.