

Data engineers are becoming frustrated with the number of disjointed tools and solutions required to build production-ready pipelines. Without a centralized data intelligence platform or unified governance, teams deal with a number of issues, including:
- Inefficient performance and long startup
- Disjointed UI and constant context-switching
- Lack of comprehensive security and controls
- complex CI/CD
- limited data lineage visibility
- etc.
outcome? Slower teams and less trust in your data.
with lake flow But Azure DatabricksYou can solve these issues by centralizing all of your data engineering efforts on a single Azure-native platform.
An integrated data engineering solution for Azure Databricks
Lakeflow is a complete modern data engineering solution built on Databricks Data Intelligence Platform On Azure that integrates all the necessary data engineering functions. With Lakeflow, you get:
- Built-in data ingestion, transformation, and orchestration in one place
- Managed Intake Connectors
- declarative etl For fast and simple development
- Incremental and Streaming Processing For faster SLAs and fresh insights
- Native governance system and genealogy Through Unity Catalog, Databricks’ integrated governance solution
- built-in observability For data quality and pipeline reliability
And much more! All in a flexible and modular interface that can meet the needs of all users, whether they want to code or use a point-and-click interface.
Consolidate, transform and organize all workloads in one place
Lakeflow unifies data engineering experience so you can move faster and more reliably.
Simple and efficient data ingestion with Lakeflow Connect
You can get started by easily ingesting data into your platform Lakeflow Connect Using a point-and-click interface or simple API.
you can have both structured and unstructured data From a wide range of sources supported in Azure Databricks, including popular SaaS applications (e.g. sales force, weekday, service now), databases (e.g., SQL Server), cloud storage, message buses, and more. Lakeflow Connect also supports Azure networking patterns, such as private links and deployment of ingestion gateways in a VNet for the database.
For real-time ingestion, check Zerobus IngestA serverless direct-write API in Lakeflow on Azure Databricks. It pushes event data directly into the data platform, eliminating the need for a message bus for simple, low-latency ingestion.
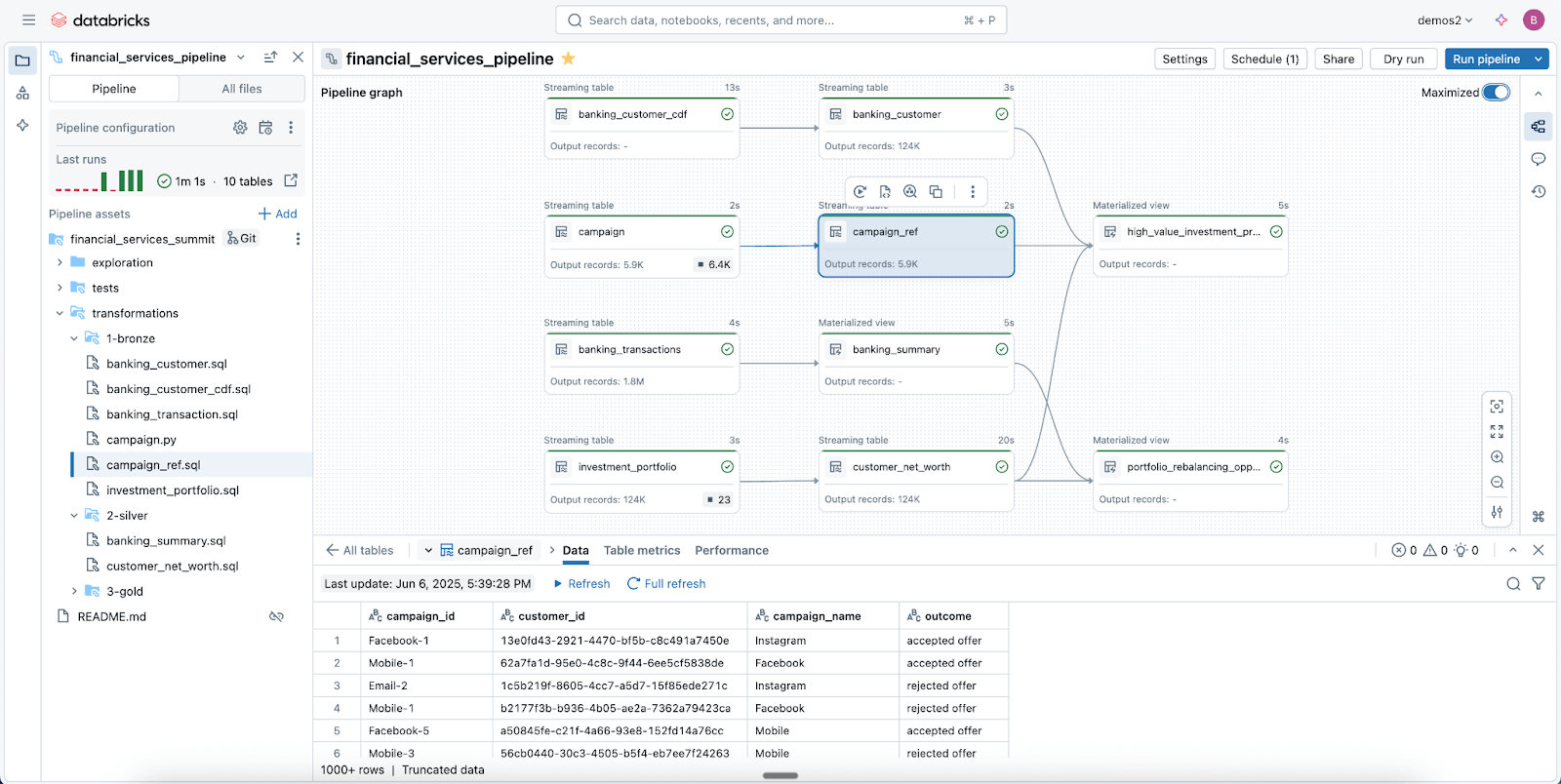
Reliable data pipelines made easy with Spark Declarative Pipelines
leverage lakeflow spark declarative pipeline (SDP) to easily clean, shape and transform your data as your business requires.
sdp Lets you create reliable batch and streaming ETL with a few lines of Python (or SQL). Simply declare the changes you need, and SDP handles the rest – including dependency mapping, deployment infrastructure, and data quality.
SDP reduces development time and operational overhead by codifying data engineering best practices out of the box, making it easy to implement incrementalization or complex patterns like SCD types 1 and 2 through a few lines of code. This is all the power of Spark Structured Streaming, made incredibly simple.
And because Lakeflow is integrated into Azure Databricks, you can use the Azure Databricks tools Databricks Asset Bundle (DAB), lakehouse monitoring, and more, to deploy production-ready, controlled pipelines in minutes.
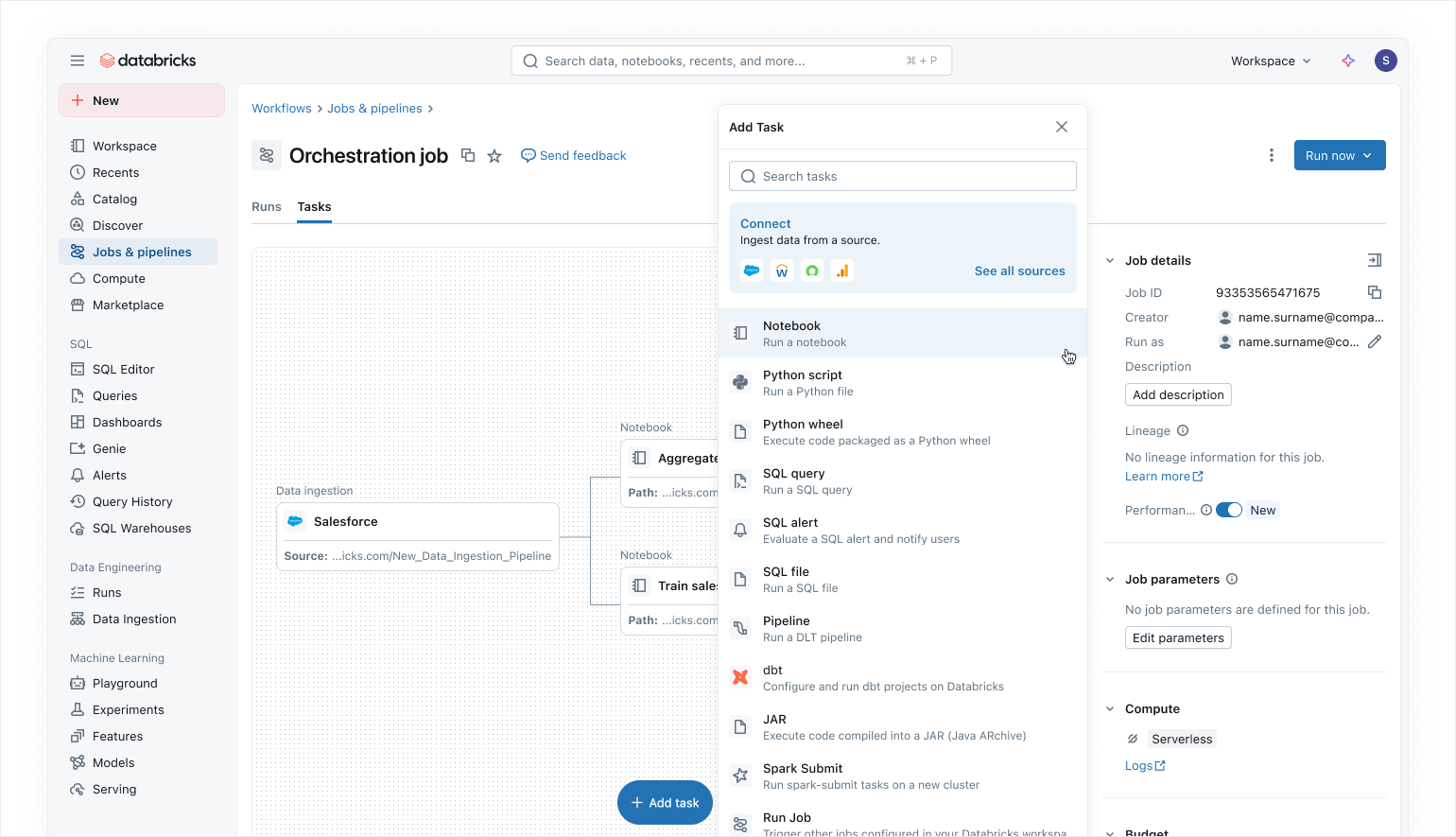
Modern data-first orchestration with Lakeflow Jobs
Use lakeflow jobs To orchestrate your data and AI workloads on Azure Databricks. With a modern, simplified data-first approach, Lakeflow Jobs is the most trusted orchestrator for Databricks, supporting large-scale data and AI processing and real-time analytics with 99.9% reliability.
In Lakeflow Jobs, you can visualize all your dependencies by syncing SQL workloads, Python code, dashboards, pipelines, and external systems into one. single integrated dag. Workflow execution is simple and flexible data-aware trigger Such as table updates or file arrivals, and control-flow tasks. thanks for doing no code backfill runs and inherent observability, Lakeflow Jobs makes it easy to keep your downstream data fresh, accessible and accurate.
As Azure Databricks users, you can also automatically update and refresh Power BI semantic models using Power BI Work at Lakeflow Jobs (Read more Here), making Lakeflow Jobs a seamless orchestrator for Azure workloads.
Built-in security and integrated governance
with unity listLakeflow inherits centralized identity, security, and governance controls over ingestion, transformation, and orchestration. Connections store credentials securely, access policies are applied consistently across all workloads, and granular permissions ensure only the right users and systems can read or write data.
Unity Catalog also provides end to end lineage Lakeflow makes it easy to trace dependencies and ensure compliance, from ingestion through jobs to downstream analytics and Power BI. system tables Provide operational and security visibility into jobs, users, and data usage to help teams monitor quality and implement best practices without tying together external logs.
Together, Lakeflow and Unity Catalog provide Azure Databricks users with controlled pipelines by default, resulting in secure, auditable, and production-ready data delivery teams can trust.
Read our blog about how Unity Catalog supports OneLake.
Flexible user experience and writing for everyone
In addition to all these features, Lakeflow is incredibly flexible and easy to use, making it a great fit for anyone in your organization, especially developers.
Code-first users love Lakeflow because of its powerful execution engine and advanced developer-centric tools. with lakeflow pipeline editorDevelopers can leverage an IDE and use robust dev tooling to build their pipelines. Lakeflow Jobs also comes with code-first authoring and dev tooling db python sdk And DAB for repeatable CI/CD patterns.
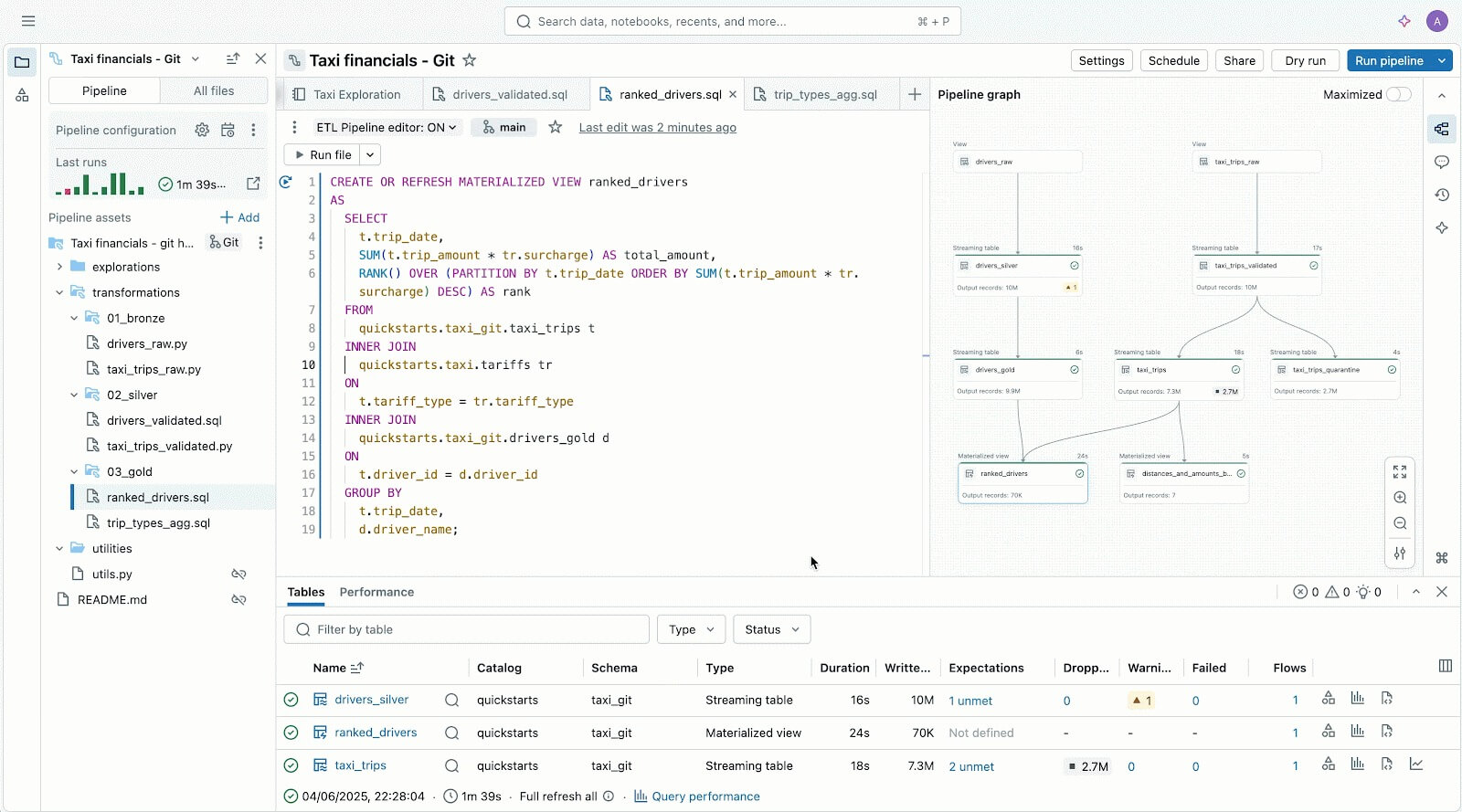
The Lakeflow Pipeline Editor helps you author and test data pipelines – all in one place.
For newcomers and business users, Lakeflow is very intuitive and easy to use, with a simple point-and-click interface and an API for data ingestion through Lakeflow Connect.
Less guessing, more accurate troubleshooting with basic observations
Monitoring solutions are often hidden from your data platform, making observations harder to implement and putting your pipelines at greater risk of breaking.
Lakeflow Jobs on Azure Databricks gives data engineers the deep, end-to-end visibility they need to quickly understand and resolve issues in their pipelines. With Lakeflow’s overview capabilities, you can quickly see performance issues, dependency bottlenecks, and failed tasks in a single UI with our integrated run list.
Lakeflow System Tables and Built-ins data lineage The Unity Catalog also provides full context on datasets, workspaces, queries, and downstream impacts, making root-cause analysis faster. with new ga System Tables in JobsYou can create custom dashboards across all your jobs and centrally monitor the health of your jobs.
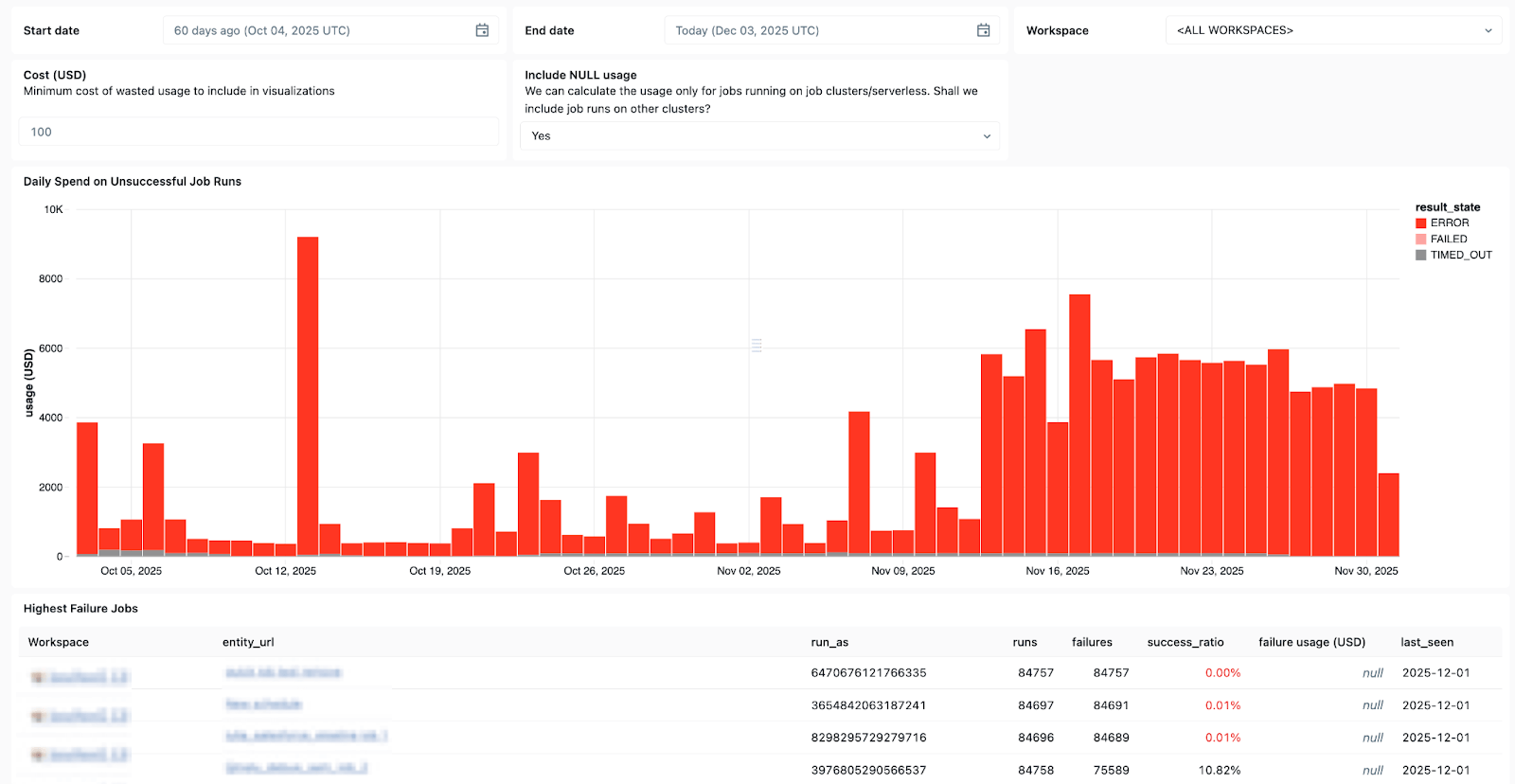
Use System Tables in Lakeflow to see which jobs fail most often, overall error trends, and common error messages.
And when issues come up, Databricks Assistant Here to help.
Databricks Assistant is a context-aware AI copilot embedded in Azure Databricks that helps you recover faster from failures by letting you quickly create and troubleshoot notebooks, SQL queries, jobs, and dashboards using natural language.
But the Assistant does more than just debugging. It can also generate PySpark/SQL code and explain it with all the features based in the Unity Catalog, so it understands your context. It can also be used to generate suggestions, surface patterns and perform data searches etc. edaWhich makes it a great companion for all your data engineering needs.
Your costs and consumption are under control
The larger your pipelines, the more difficult it will be to right-size resource utilization and keep costs under control.
with lakeflow Serverless Data ProcessingCalculations are automatically and continuously optimized by Databricks to reduce idle waste and resource usage. Data engineers can decide whether to run serverless in performance mode for mission-critical workloads or in standard mode for greater flexibility where cost is more important.
Lakeflow also allows reuse of jobs clusters, so multiple tasks can run in a workflow Same job cluster, eliminating cold start delay, And supports fine controlSo each job can target either a reusable job cluster or its own dedicated cluster. With serverless compute, cluster reuse reduces spin-up so data engineers can cut operational overhead and gain greater control over their data costs.
Microsoft Azure + Databricks Lakeflow – a proven winning combination
Databricks Lakeflow enables data teams to move faster and more reliably without compromising governance, scalability, or performance. With data engineering seamlessly embedded in Azure Databricks, teams can benefit from a single end-to-end platform that meets all data and AI needs at scale.
Customers on Azure have already seen positive results from integrating Lakeflow into their stack, including:
- Faster Pipeline Development: Teams can build and deploy production-ready data pipelines up to 25 times faster, and cut build time by 70%.
- High performance and reliability: Some customers are seeing up to 90x improvement in performance and reducing processing time from hours to minutes.
- Greater efficiency and cost savings: Automation and optimized processing dramatically reduce operational overhead. Customers have reported savings of up to millions of dollars annually and reductions in ETL costs of up to 83%.
Read successful Azure and Lakeflow customer stories on our Databricks blog.
Curious about lakeflow? Effort databricks free To see what a data engineering platform is.