

Users can conduct machine learning (ML) data experiments in data environments like Snowflake using Snowpark LibraryHowever, tracking these experiments across diverse environments can be challenging due to the difficulty in maintaining a central repository for monitoring experiment metadata, parameters, hyperparameters, models, results, and other relevant information, In this post, we demonstrate how to integrate Amazon SageMaker Managed MLflow as a central repository to provide a unified system for logging these experiments and monitoring their progress,
Amazon SageMaker Managed MLFlow provides fully managed services for experiment tracking, model packaging, and model registry. The SageMaker Model Registry streamlines model versioning and deployment, facilitating a seamless transition from development to production. Additionally, integration with Amazon S3, AWS Glue, and SageMaker Feature Store enhances data management and model traceability. The main benefit of using MLflow with SageMaker is that it allows organizations to standardize ML workflows, improve collaboration, and accelerate artificial intelligence (AI)/ML adoption with a more secure and scalable infrastructure. In this post, we show how to integrate Amazon SageMaker Managed MLFlow with Snowflake.
Snowpark allows creating custom data pipelines in Python, Scala or Java for efficient data manipulation and preparation when storing training data in Snowflake. Users can run experiments in Snowpark and track them in Amazon SageMaker managed MLflow, This integration allows data scientists to run change and feature engineering in Snowflake and use the managed infrastructure within SageMaker for training and deployment, facilitating more seamless workflow orchestration and more secure data handling.
solution overview
The integration leverages Snowflake for Python, a client-side library that allows Python code from the Python kernel to interact with Snowflake, such as SageMaker’s Jupyter notebooks. A workflow may include data preparation in Snowflake as well as feature engineering and model training within Snowpark. Amazon SageMaker Managed MLflow can be used for experiment tracking and model registry integrated with the capabilities of SageMaker.
Figure 1: Architecture diagram
Capture key details with MLflow tracking
mlflow tracking is important in integration between Sagemaker, Snowpark, And snowflake By providing a centralized environment for logging and managing the entire machine learning lifecycle. As Snowpark processes data from Snowflake and trains the model, MLflow tracking can be used to capture key details including model parameters, hyperparameters, metrics, and artifacts. This data allows scientists to monitor experiments, compare different model versions, and verify reproducibility. with Versioning and logging capabilities of MLflowTeams can intuitively explore results based on the specific dataset used and transformations, making it easier to track the performance of models over time and maintain transparent and efficient ML workflows.
This approach offers several benefits. It allows scalable and managed MLflow tracker sagemakerUsing the processing capabilities of snowpark Creating an integrated data system,for model estimation within the Snowflake environment. Workflows live in the Snowflake environment, which enhances data security and governance. Additionally, this setup helps reduce costs by using Snowflake’s elastic compute power for inference without maintaining a separate infrastructure for model serving.
Prerequisites
Create/configure the following resources and verify access to the above resources before installing Amazon SageMaker MLflow:
- A snowflake account
- An S3 bucket to track experiments in MLflow
- An Amazon SageMaker Studio account
- An AWS Identity and Access Management (IAM) role that is an Amazon SageMaker domain execution role in an AWS account.
- A new user with permission to access the S3 bucket created above; follow these steps.
- Confirm access to the AWS account through the AWS Management Console and the AWS Command Line Interface (AWS CLI). An AWS Identity and Access Management (IAM) user must have permissions to make the required AWS service calls and manage the AWS resources mentioned in this post. When granting permissions to an IAM user, follow the principle of least-privilege.
- Configure access to the Amazon S3 bucket above This step.
- to follow these steps To set up external access to the Snowflake notebook.
Steps to call SageMaker’s MLflow tracking server from Snowflake
Now we set up the Snowflake environment and connect it to the Amazon SageMaker MLFlow tracking server we set up earlier.
- Follow these steps to create an Amazon SageMaker managed MLflow tracking server in Amazon SageMaker Studio.
- Log in to Snowflake as an administrator user.
- Create a new notebook in snowflake
- Project > Notebook > +Notebook
- Change role to non-admin role
- Give a name, choose a database (DB), schema, warehouse and select ‘Run on container’

- Notebook Settings > External Access > Turn on to allow all integrations
- install library
!pip install sagemaker-mlflow
- Run the MLflow code by replacing the arn value with the code below:

Figure 3: Install sagemaker-mlflow library

Figure 4: Configure and use MLflow.
Upon successful testing, the experiment can be tracked on Amazon SageMaker:
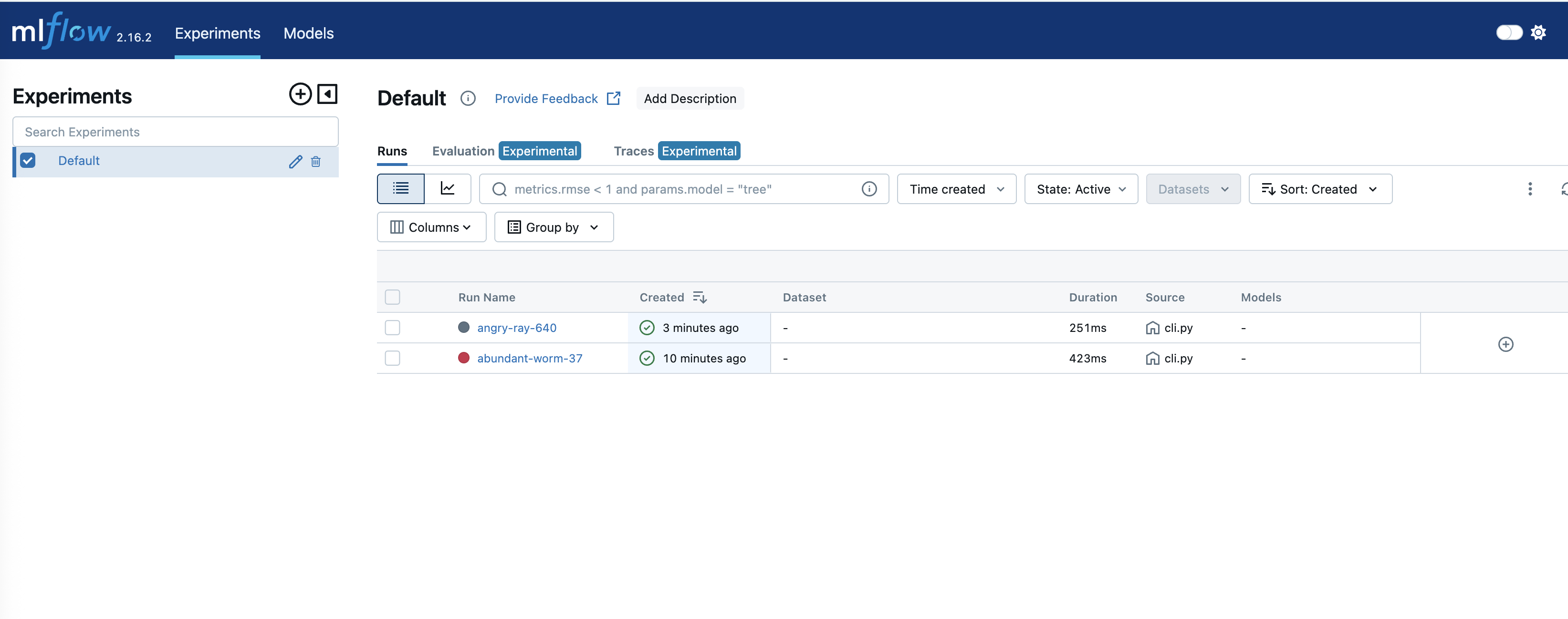
Figure 5: Track experiments in SageMaker MLflow
To get details of an experiment, click on the corresponding “Run Name:”.
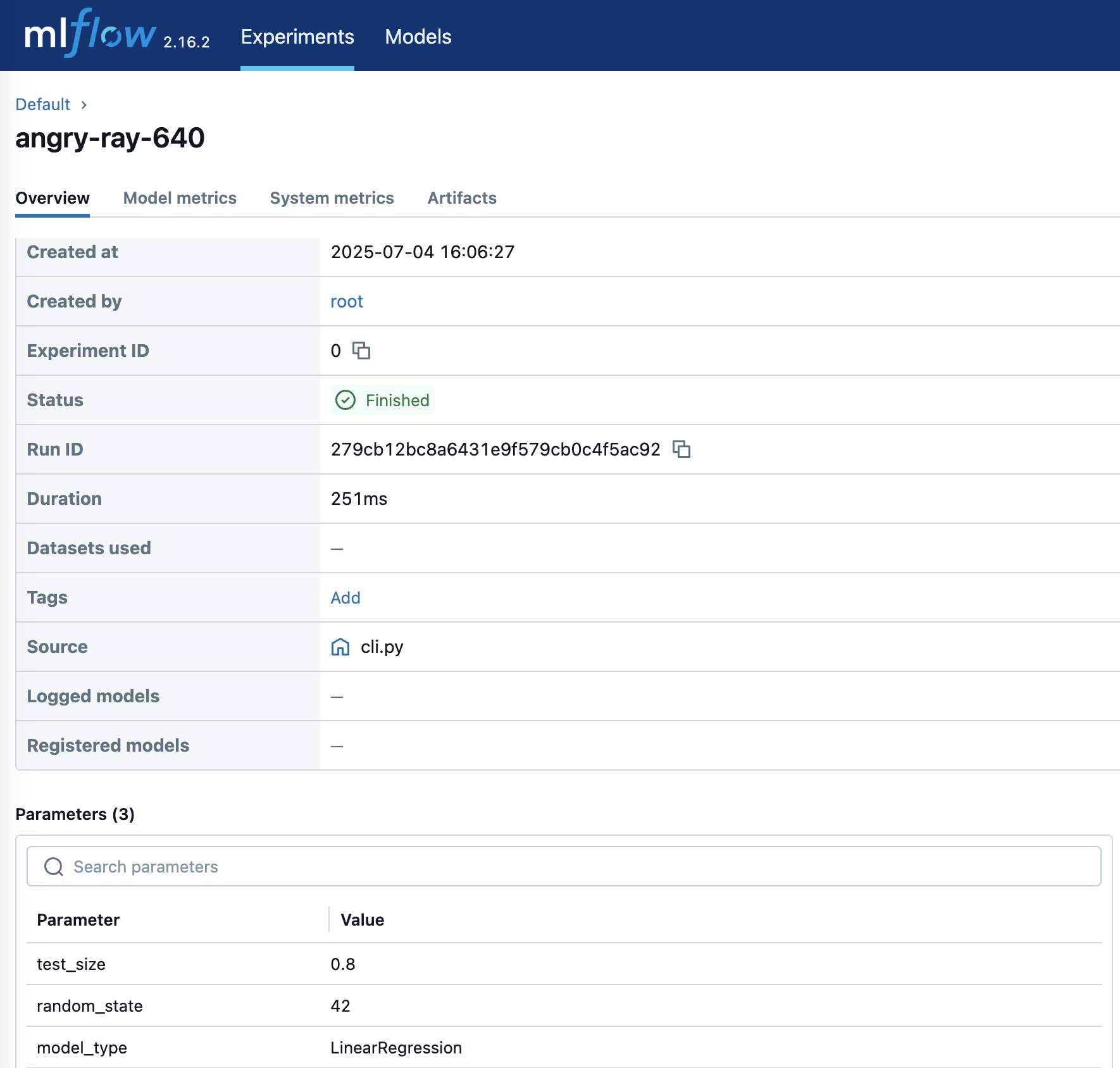
Figure 6: Experience detailed experiment insights
cleanliness
Follow these steps to clean up the resources we have configured in this post to help avoid ongoing costs.
- Delete the SageMaker Studio account by following these steps, this also removes the MLFlow tracking server
- Delete the S3 bucket along with its contents
- drop ice cubes notebook
- Verify that the Amazon SageMaker account has been deleted
conclusion
In this post, we explored how Amazon SageMaker Managed MLflow can provide a comprehensive solution for managing the machine learning lifecycle. Integration with Snowflake through Snowpark further enhances this solution, helping to enable seamless data processing and model deployment workflows.
To get started, follow the step-by-step instructions above to set up MLflow Tracking Server in Amazon SageMaker Studio and integrate it with Snowflake. Remember to follow AWS security best practices by implementing appropriate IAM roles and permissions and securing all credentials appropriately.
The code samples and instructions in this post serve as a starting point – they can be adapted to match specific use cases and requirements while maintaining security and scalability best practices.
About the authors
 Ankit Mathur A solution architect at AWS focused on modern data platforms, AI-powered analytics, and AWS-partner integrations. He helps customers and partners design secure, scalable architectures that deliver measurable business results.
Ankit Mathur A solution architect at AWS focused on modern data platforms, AI-powered analytics, and AWS-partner integrations. He helps customers and partners design secure, scalable architectures that deliver measurable business results.
 mark hoover is a Senior Solutions Architect at AWS where he focuses on helping customers build their ideas in the cloud. He has partnered with numerous enterprise clients to transform complex business strategies into innovative solutions that drive long-term growth.
mark hoover is a Senior Solutions Architect at AWS where he focuses on helping customers build their ideas in the cloud. He has partnered with numerous enterprise clients to transform complex business strategies into innovative solutions that drive long-term growth.