

Liquid AI has introduced LFM2-2.6b-XP, an experimental checkpoint of its LFM2-2.6b language model trained with pure reinforcement learning on top of the existing LFM2 stack. The goal is simple, to improve instruction following, knowledge tasks and mathematics for a small 3B class model that is still targeted at device and edge deployments.
Where LFM2-2.6B-Exp fits into the LFM2 family,
The LFM2 is the second generation of liquid foundation models. It is designed for efficient deployment on phones, laptops, and other edge devices. Liquid AI describes LFM2 as a hybrid model that combines short-range LIV convolution blocks with grouped query attention blocks controlled by multiplier gates.
The family consists of 4 compact sizes, LFM2-350M, LFM2-700M, LFM2-1.2B, and LFM2-2.6B. All have a reference length of 32,768 tokens, a vocabulary size of 65,536 and bfloat16 precision. The 2.6B model uses 30 layers, including 22 convolution layers and 8 attention layers. Each size is trained on a 10 trillion token budget.
LFM2-2.6B is already positioned as a high efficiency model. It reaches 82.41 percent on GSM8K and 79.56 percent on IFEval. This puts it ahead of many 3B class models such as the Llama 3.2 3B Instruct, Gemma 3 4B IT and SMOLM3 3B on these benchmarks.
LFM2-2.6B-Exp maintains this architecture. It reuses the same tokenization, context window, and hardware profile. Checkpoint focuses only on changing behavior through a reinforcement learning phase.
Pure RL on top of a pre-trained, aligned base
This checkpoint is built on LFM2-2.6B using pure reinforcement learning. It is specifically trained on following instructions, knowledge and mathematics.
The underlying LFM2 training stack combines several stages. This includes very large-scale supervised fine tuning on a mix of downstream tasks and general domains, custom direct preference optimization with length normalization, iterative model merging, and reinforcement learning with verifiable rewards.
But what exactly does ‘pure reinforcement learning’ mean? LFM2-2.6B-Exp starts with an existing LFM2-2.6B checkpoint and then goes through a sequential RL training program. It starts with following instructions, then in that final step the RL training is expanded to the use of knowledge-oriented signals, mathematics, and a small amount of tools, without additional SFT warm up or distillation steps.
Importantly, LFM2-2.6B-Exp does not change the base architecture or pre-training. It transforms the policy through an RL stage that uses verifiable rewards on a target set of domains, on top of an already supervised and preference aligned model.
Benchmark signals, exclusively on IFbench
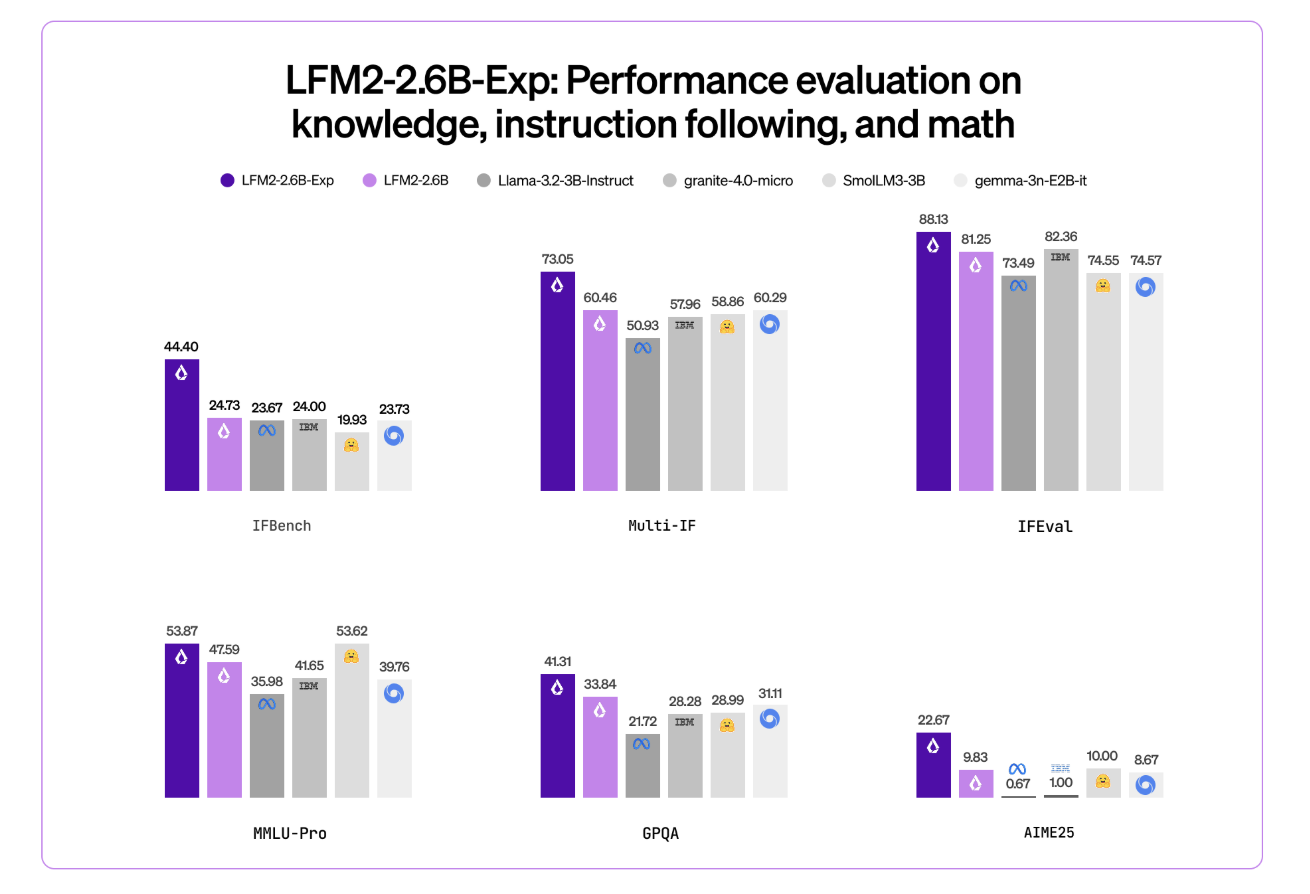
The Liquid AI team highlights IFBench as the main headline metric. IFBench is a benchmark that tests how reliably a model follows complex, constrained instructions. On this benchmark, LFM2-2.6B-Exp outperforms DeepSeek R1-0528, which is reported to be 263 times larger in parameter count.
LFM2 models deliver strong performance across a standard set of benchmarks such as MMLU, GPQA, IFEval, GSM8K and related suites. The 2.6B base model already competes well in the 3B segment. The RL checkpoint then follows the instruction and proceeds with the mathematics while remaining within the same 3B parameter budget.
Architecture and capabilities that matter
The architecture uses 10 double gated short range LIV convolution blocks and 6 grouped query attention blocks arranged in a hybrid stack. This design reduces KV cache costs and enables faster inference on consumer GPUs and NPUs.
The pre-training mix uses approximately 75 percent English, 20 percent multilingual data, and 5 percent code. Supported languages include English, Arabic, Chinese, French, German, Japanese, Korean, and Spanish.
LFM2 models expose a ChatML-like template and native tool usage tokens. The tool is described as JSON between dedicated tool list markers. The model then emits Python-like calls between tool call markers and reads tool responses between tool response markers. This structure makes the model suitable as an agent core for a tool calling stack without custom prompt engineering.
The LFM2-2.6b, and by extension the LFM2-2.6b-XP, is the only model in the family that enables dynamic hybrid reasoning via special think tokens for complex or multilingual input. That capability remains available because RL does not change checkpoint tokenization or architecture.
key takeaways
- LFM2-2.6b-XP is an experimental checkpoint of LFM2-2.6b that adds a pure reinforcement learning stage on top of a pre-trained, supervised, and priority aligned base targeted at following instructions, knowledge tasks, and mathematics.
- The LFM2-2.6B backbone uses a hybrid architecture that combines double gated short range LIV convolution block and grouped query attention block, with 30 layers, 22 convolution layers and 8 attention layers, 32,768 token context length and 10 trillion token training budget on 2.6B parameters.
- LFM2-2.6B already achieves strong benchmark scores in the 3B class, approximately 82.41 percent on GSM8K and 79.56 percent on IFEval, and LFM2-2.6B-Exp RL further improves instruction adherence and math performance without changing the checkpoint architecture or memory profile.
- Liquid AI reports that on IFBench, one instruction after the benchmark, LFM2-2.6B-Exp, outperforms DeepSeek R1-0528, even though the latter has many more parameters, showing a stronger performance per parameter for restricted deployment settings.
- LFM2-2.6B-Exp is released under the LFM Open License v1.0 with open weights on hugging faces and is supported via Transformer, vLLM, llama.cpp GGUF quantization and ONNXRuntime, making it suitable for agentic systems, structured data extraction, retrieval augmented generation and device assistants where a compact 3B model is required.
check it out model hereAlso, feel free to follow us Twitter And don’t forget to join us 100k+ ml subreddit and subscribe our newsletterwait! Are you on Telegram? Now you can also connect with us on Telegram.
Max is an AI analyst at Silicon Valley-based MarkTechPost, actively shaping the future of technology. He teaches robotics at Brainvine, fights spam with ComplyMail, and leverages AI daily to translate complex technological advancements into clear, understandable insights.