

The fundamental tension in conversational AI has always been a binary choice: respond fast or respond smart. Real-time speech-to-speech (S2S) models – the kind that power natural-feeling voice assistants – start talking almost immediately, but their answers are shallow. Cascade systems that route speech through large language models (LLMs) are far more knowledgeable, but the delays in the pipeline are long enough to make the conversation slow and robotic. Sakana AI researchers, Tokyo-based AI lab introduces Chem (Knowledge-Access Model Extension), a hybrid architecture that keeps the near-zero response latency of a direct S2S system while injecting rich knowledge of the back-end LLM in real time.
Problem: Two Paradigms, Two Businesses
To understand why KAME is important, it helps to understand the two major designs it connects.
A direct S2S model like Moshi (developed by KyutAI) is a monolithic transformer that takes audio tokens and generates audio tokens in a continuous loop. Because it does not need to synchronize with external systems, its response latency is exceptionally low – for many queries, the model begins speaking even before the user has completed his question. But because acoustic signals are far more information-dense than text, models have to spend significant capacity modeling paralinguistic features such as intonation, emotion, and rhythm. This leaves less room for factual knowledge and deeper reasoning.
A cascade system, in contrast, routes the user’s speech through an automatic speech recognition (ASR) model, feeds the resulting text into a powerful LLM, and then converts the LLM’s response to speech through a text-to-speech (TTS) engine. The knowledge quality is excellent – you can plug in any marginal LLM – but the system has to wait for the user to speak before it can begin processing ASR and LLM. This results in an average latency of about 2.1 seconds, which is enough to noticeably disrupt the flow of natural conversation.
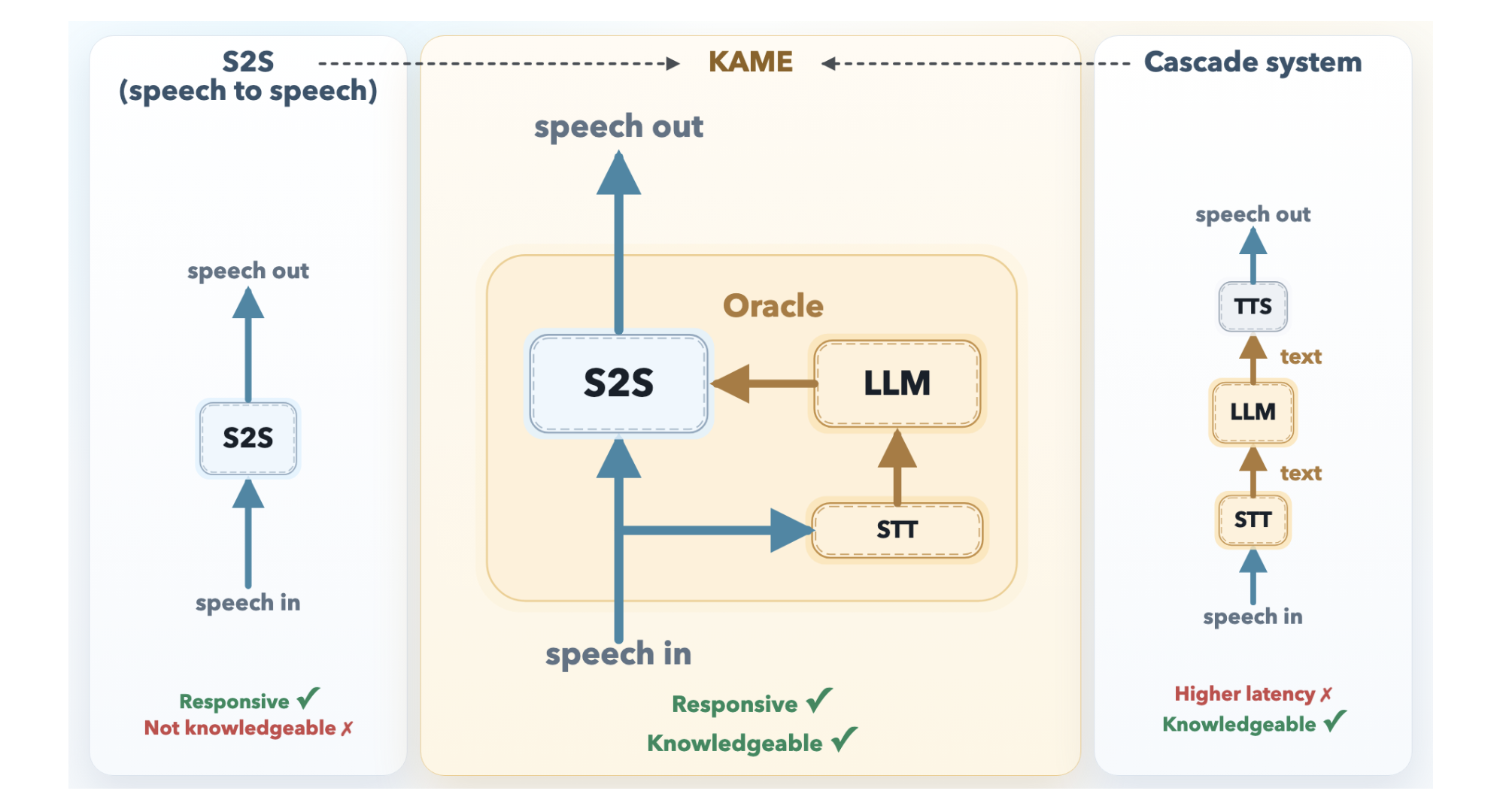
KAME Architecture: Thinking and Speaking
KAME operates as a tandem system in which two asynchronous components run in parallel.
Front-end S2S module It is based on the Moshi architecture and processes audio in real time on a cycle of discrete audio tokens (approximately every 80 milliseconds). It starts generating verbal responses immediately. Internally, Moshi’s basic three-stream design – input audio, internal monologue (text), and output audio – has been expanded in KAME with the addition of a fourth stream: oracle stream. This is the key innovation point.
Back-end LLM module It includes a streaming speech-to-text (STT) component paired with full-scale LLM. As the user speaks, the STT component continuously creates a partial transcript and periodically sends it to the back-end LLM. For each partial transcript received, the LLM generates a candidate text response – called an oracle – and streams it back to the front-end. Because the user’s speech is still coming in, these oracles start out as educated guesses and become progressively more accurate as the transcript becomes more complete.
The front-end S2S transformer then conditions its ongoing speech output on both its internal context and these incoming oracle tokens. When a new, better oracle comes along, the model can correct course – effectively updating its response in mid-sentence, the same way a human can. Because both modules run asynchronously and independently, the initial response latency remains close to zero.
Training on Fake Predictions
One challenge is that no naturally occurring datasets contain oracle signals. The Sakana AI research team addresses this with a technique called Simulated Oracle Augmentation. Using a ‘simulator’ LLM and a standard conversational dataset (user utterances + ground-truth feedback), the research team generates synthetic oracle sequences that will produce real-time LLMs at various levels of imitation completeness. They define six signal levels (0-5), ranging from a completely vague estimate at signal level 0 to a verbatim ground truth response at signal level 5. The training data for KAME was created from 56,582 synthetic dialogues taken from MMLU-Pro, GSM8K and HSSBench, converted to audio via TTS and augmented with these progressive oracle sequences.
The result: near-cascade quality, near-zero latency
Evaluations on the speech-synthesized subset of the MT-Bench multi-turn Q&A benchmark – particularly the logic, STEM, and humanities categories (coding, extraction, mathematics, roleplay, and writing were excluded as unsuitable for speech interaction) – show a dramatic improvement. Moshi alone has an average score of 2.05. KAME’s back-end score with GPT-4.1 is 6.43, and KAME’s back-end score with cloud-opus-4-1 is 6.23 – both are essentially at the same latency as Moshi. The leading cascade system, Unmute (also supported by GPT-4.1), scores 7.70, but with an average latency of 2.1 seconds, compared to almost zero for KAME.
To isolate back-end capacity from timing effects, the research team evaluated the text responses of back-end LLMs directly from the last oracle injection in each KAME session – completely bypassing the problem of premature generation. The average of those scores was 7.79 (Logic 6.48, STEM 8.34, Humanities 8.56), which is comparable to Unmute’s 7.70. This confirms that KAME’s difference with the cascade system is not the extent of the back-end LLM’s knowledge, but the result of starting to speak before hearing the full user query.
Importantly, KAME is completely back-end agnostic. The front-end was trained using gpt-4.1-nano as the primary back-end, but swapping to cloud-opus-4-1 or gemini-2.5-flash at the estimated time requires no retraining. In Sakana AI’s experiments, Cloud-Opus-4-1 outperformed GPT-4.1 on reasoning tasks, while GPT-4.1 scored higher on humanities questions – suggesting that practitioners can route questions to the most task-appropriate LLM without touching the front-end model.
key takeaways
- KAME connects the speed-versus-knowledge tradeoff in conversational AI By running the front-end speech-to-speech model and the back-end LLM asynchronously in parallel – the S2S model responds instantly while the LLM continuously injects progressively sophisticated ‘oracle’ signals in real time, changing the paradigm from ‘think, then speak’ to ‘speak while you think’.
- Performance gains are substantial without any latency cost – KAME has increased the MT-Bench score from 2.05 (Moshi baseline) to 6.43, getting close to Cascade System Unmute’s 7.70, while maintaining near-zero average response latency versus Unmute’s 2.1 seconds.
- The architecture is completely back-end agnostic – The front-end was trained using GPT-4.1-nano, but supports plug-and-play swapping of any Frontier LLM (GPT-4.1, Cloud-Opus-4-1, Gemini-2.5-Flash) without any retraining, enabling task-specific LLM selection based on domain strengths.
check it out model weight, paper, guess code And technical details. Also, feel free to follow us Twitter And don’t forget to join us 130k+ ML subreddit and subscribe our newsletter. wait! Are you on Telegram? Now you can also connect with us on Telegram.
Do you need to partner with us to promote your GitHub repo or Hugging Face page or product release or webinar, etc? join us