

Microsoft has released fi-4-logic-vision-15bA 15 Billion Parameter Open-Weight Multimodal Reasoning Model Designed for image and text tasks that require both perception and selective reasoning. It is a compact model designed to balance logic quality, computation efficiency, and training-data requirements with particular strengths. scientific and mathematical reasoning And Understanding User Interface.

What is the model based on?
Phi-4-Logic-Vision-15B combines fi-4-logic language with spine SIGLIP-2 Using Vision Encoder mid fusion architecture. In this setup, the vision encoder first converts images into visual tokens, then those tokens are projected into the language model embedding space and processed by the pre-trained language model. This design serves as a practical trade-off: it preserves strong cross-modal reasoning while keeping training and inference costs manageable compared to bulky initial-fusion designs.
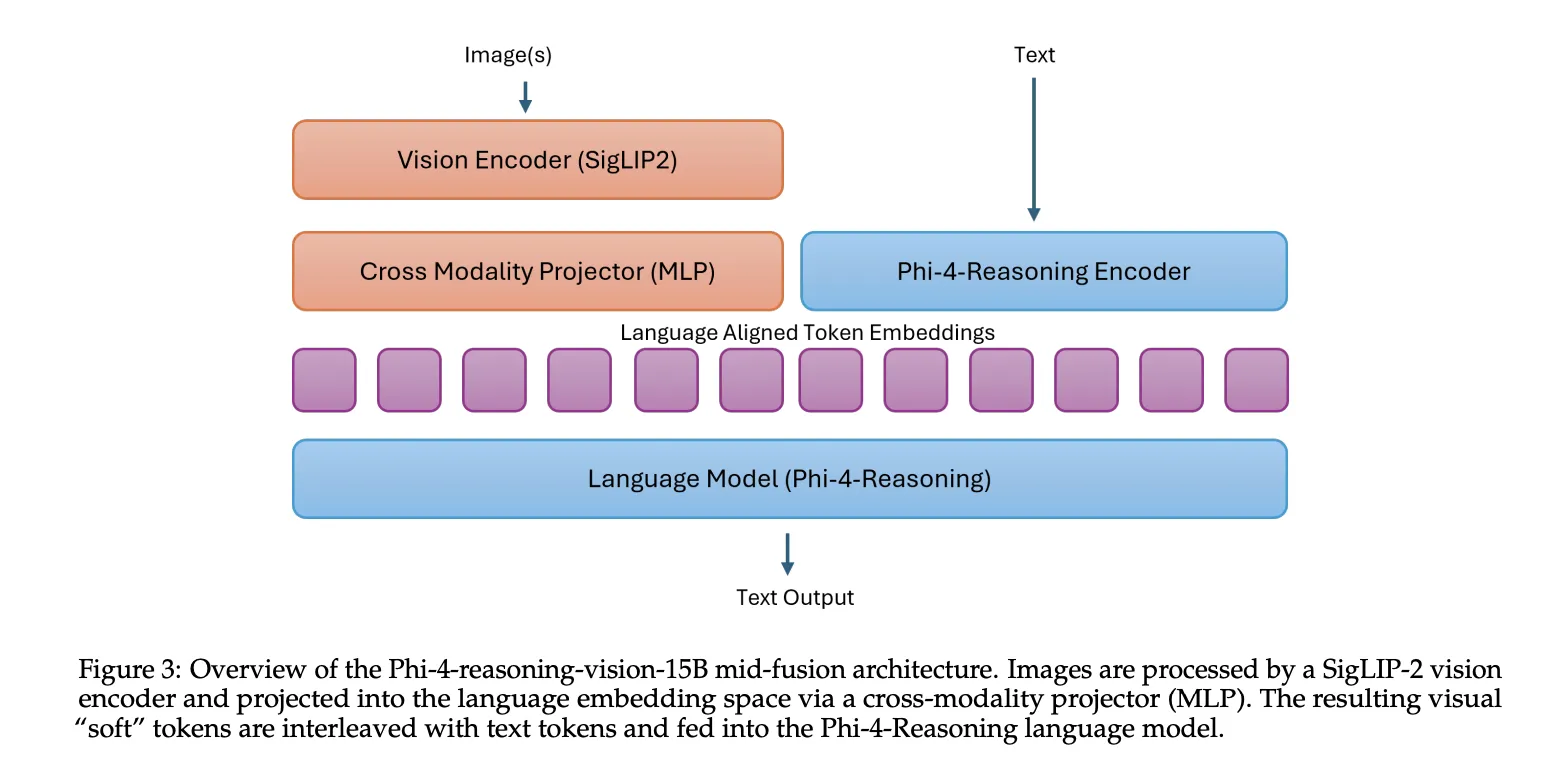
Why did Microsoft go the small-model route??
Many recent vision-language models have increased parameter counts and token usage, increasing both latency and deployment cost. Phi-4-Reasoning-Vision-15B was created as a smaller alternative that still handles general multimodel workloads without relying on very large training datasets or excessive inference-time token generation. trained on the model 200 billion multimodal tokensconstruction on fi-4-logicon which training was given 16 billion tokensand finally on fi-4 Base model on which training was performed 400 billion unique tokens. Microsoft compares it to Over 1 Trillion Tokens are used to train many recent multimodal models such as QUEEN 2.5 VL, QUEEN 3 VL, km-vlAnd Gemma 3.
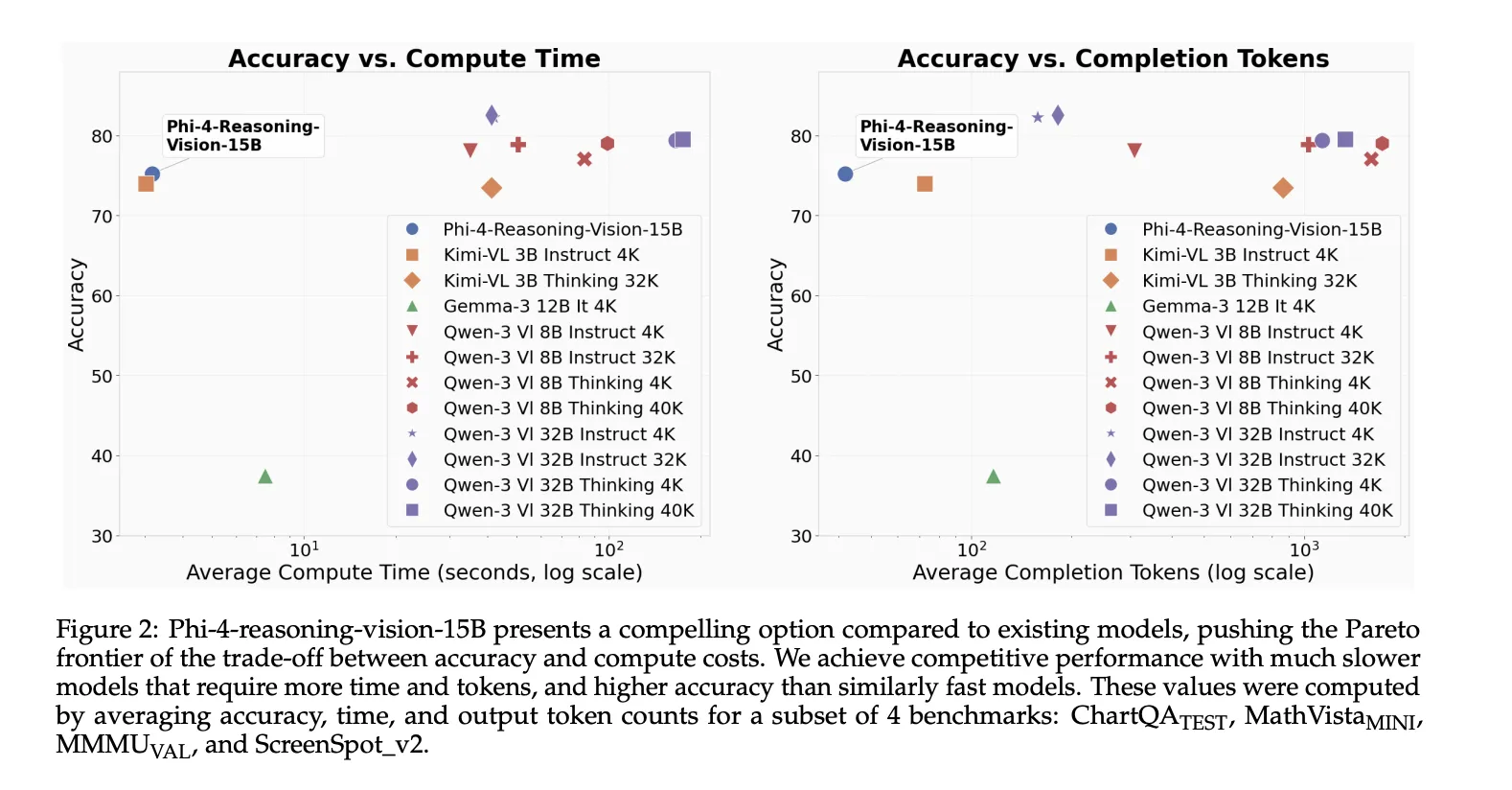
High-resolution perception was a key design choice
One of the more useful technical lessons the Microsoft team explains in their technical report is that multimodal reasoning often fails because the assumption fails in the first place. Models may miss answers, not because they lack the ability to reason, but because they fail to extract relevant visual details from dense images such as screenshots, documents, or interfaces with small interactive elements.
Uses Phi-4-Logic-Vision-15B Dynamic resolution vision encoder with up to 3,600 visual tokenswhich aims to support high-resolution understanding for tasks such as gui grounding And micro document analysis. Microsoft team says that High-resolution, dynamic-resolution encoders drive continuous improvementsand notes it clearly Accurate perception is a prerequisite for high-quality reasoning.
Mixed logic instead of forcing logic everywhere
The second important design decision is that of the model. Mixed logic and non-logical training strategy. Instead of forcing chain-of-thought-style reasoning for all tasks, the Microsoft team trained the model to switch between the two modes. Contains logic samples
The goal of this hybrid setup is to let the model respond directly to tasks where longer reasoning adds latency without improving accuracy, while still applying structured reasoning to tasks like math and science. The Microsoft team also notes an important limitation: the range between these modes is learned implicitly, so switching is not always optimal. Users can override default behavior through explicit prompts
Which areas are stronger?
Microsoft Teams highlights 2 main application areas. is the first Scientific and mathematical reasoning on visual inputIncluding handwritten equations, diagrams, charts, tables, and quantitative documents. the second one is computer-use agent tasksWhere the model interprets screen content, localizes GUI elements, and supports interactions with desktop, web, or mobile interfaces.
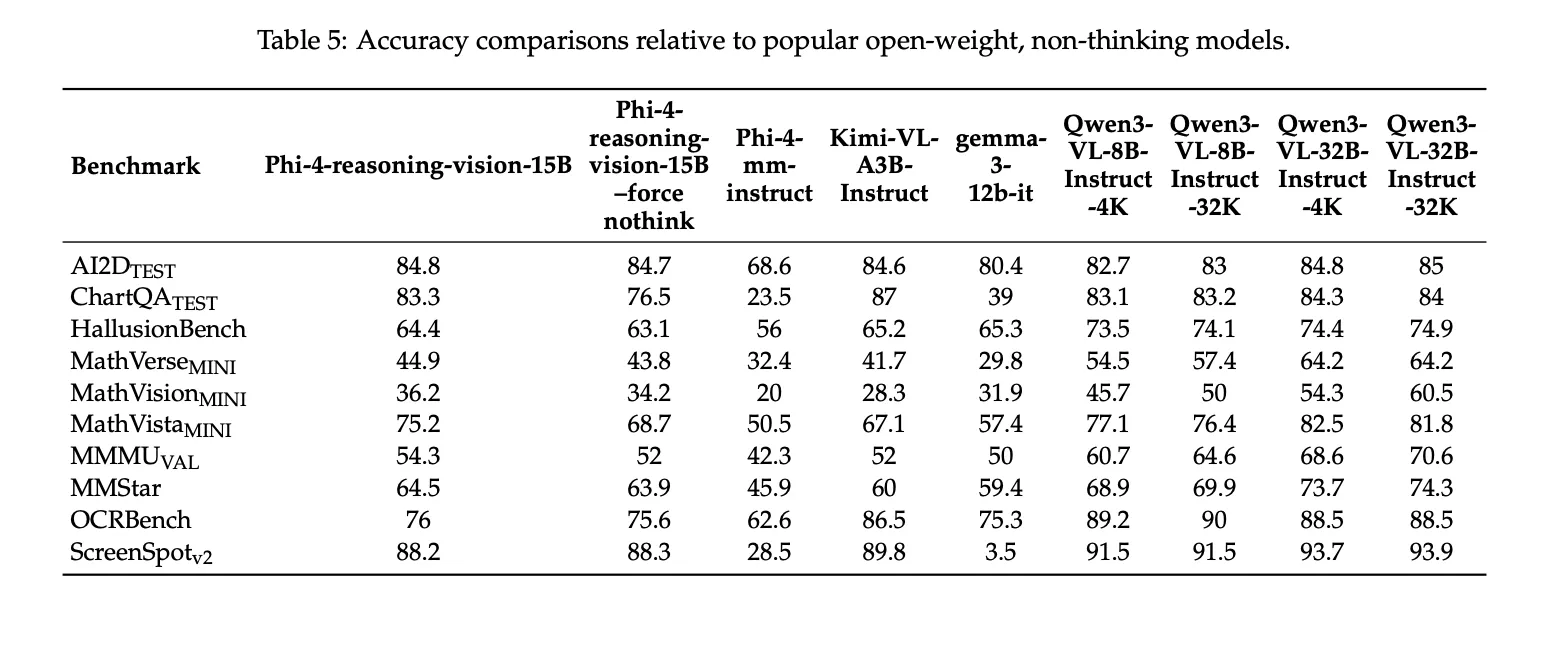
benchmark results
The Microsoft team reports the following benchmark scores for the Phi-4-Reasoning-Vision-15B: 84.8 on AI2DTEST, 83.3 on ChartQASTEST, 44.9 on MathVerseMINI, MathVisionMINI at 36.2, 75.2 on MathVistaMINI, 54.3 on MMMUval, 64.5 on mmstar, 76.0 on OCRBenchAnd 88.2 on ScreenSpotv2. The technical report also notes that these results were prepared using Eureka ML Insights And VLMEWallKitWith fixed assessment settings, and the Microsoft team presents them as comparative results rather than leaderboard claims.
key takeaways
- Phi-4-Reasoning-Vision-15B is a 15B open-weight multimodal model made by mixing fi-4-logic with SIGLIP-2 Vision Encoder in A mid fusion architecture.
- Microsoft team designs model for compact multimodal reasoningwith focus on Math, Science, Document Understanding, and GUI GroundingInstead of scaling very large parameter calculations.
- High-resolution visual perception is a core part of the systemwith the support of Dynamic resolution encoding and up to 3,600 visual tokensWhich helps in intensive screenshots, documents and interface-heavy tasks.
- Model uses mixed logic and non-logic trainingallows it to switch between
- Microsoft’s reported benchmarks show strong performance for its sizeincluding results AI2DTEST, ChartQATEST, MathVistaMINI, OCRBench, and ScreenSpotv2Which supports its status as a compact but capable visual-language reasoning model.
check it out paper, repo And model weight. Also, feel free to follow us Twitter And don’t forget to join us 120k+ ml subreddit and subscribe our newsletter. wait! Are you on Telegram? Now you can also connect with us on Telegram.