
GPUs power today’s most advanced AI workloads – from predictions and recommendations to multimodal foundation models. However, teams struggle to procure and manage GPU infrastructure, configure distributed training environments, and overcome data loading bottlenecks. Deep learning researchers prefer to focus on modeling, not problem-solving infrastructure.
We’re excited to announce the public preview of AI Runtime (AIR)A new training stack that enables on demand Distributed GPU training on A10s and H100s. The AI runtime includes all the technologies used for large-scale training of LLMs like MPT dbrx. Even in beta, hundreds of customers, including Rivian, FactSet, and Ypitdata, have used AIR to train deep learning models and send them into production. Use cases span from computer vision models to recommender systems and refining LLMs for agentic tasks. Our own Databricks AI research team used AIR for reinforcement learning of our recent models carl paper.
with AI RuntimeDatabricks users now have:
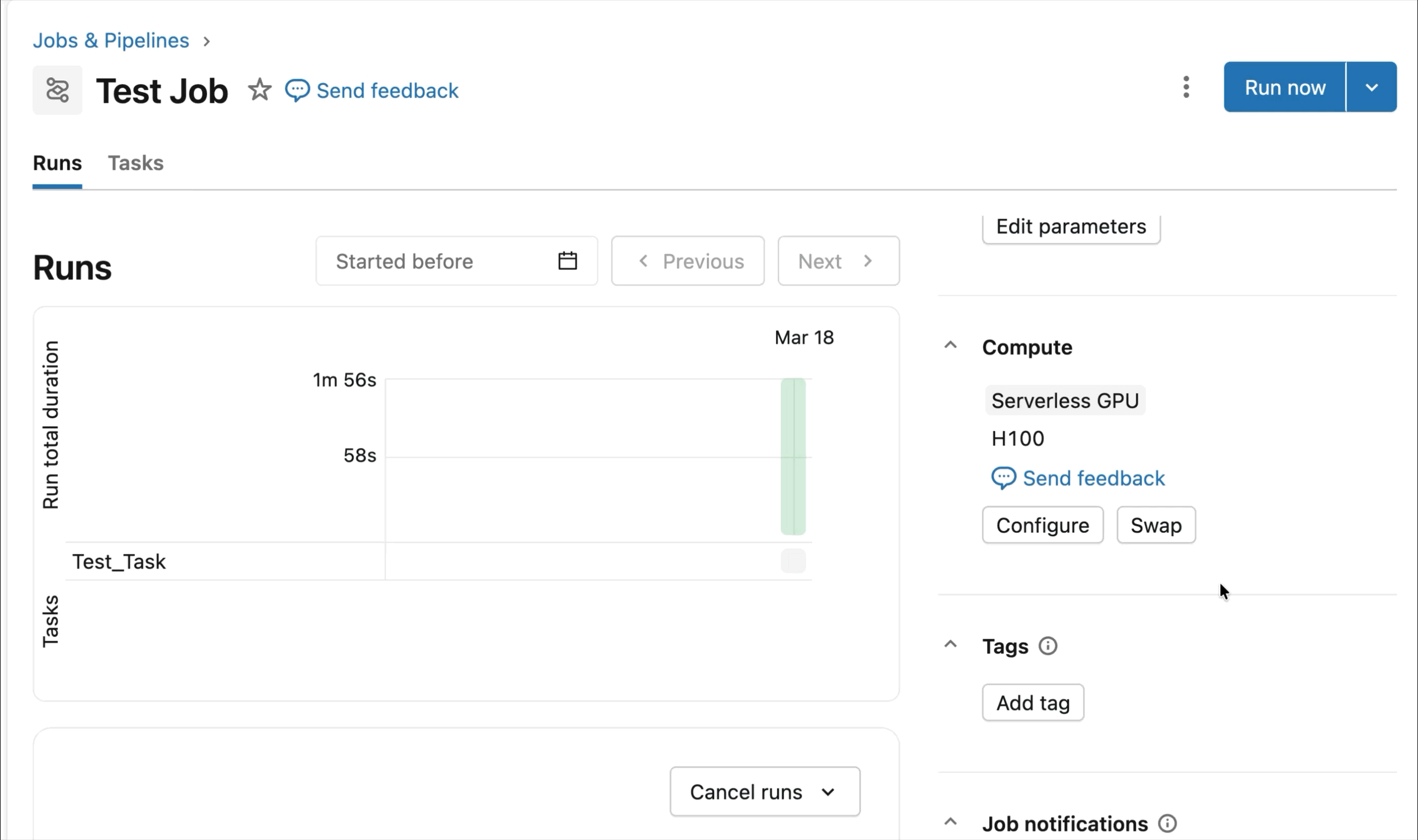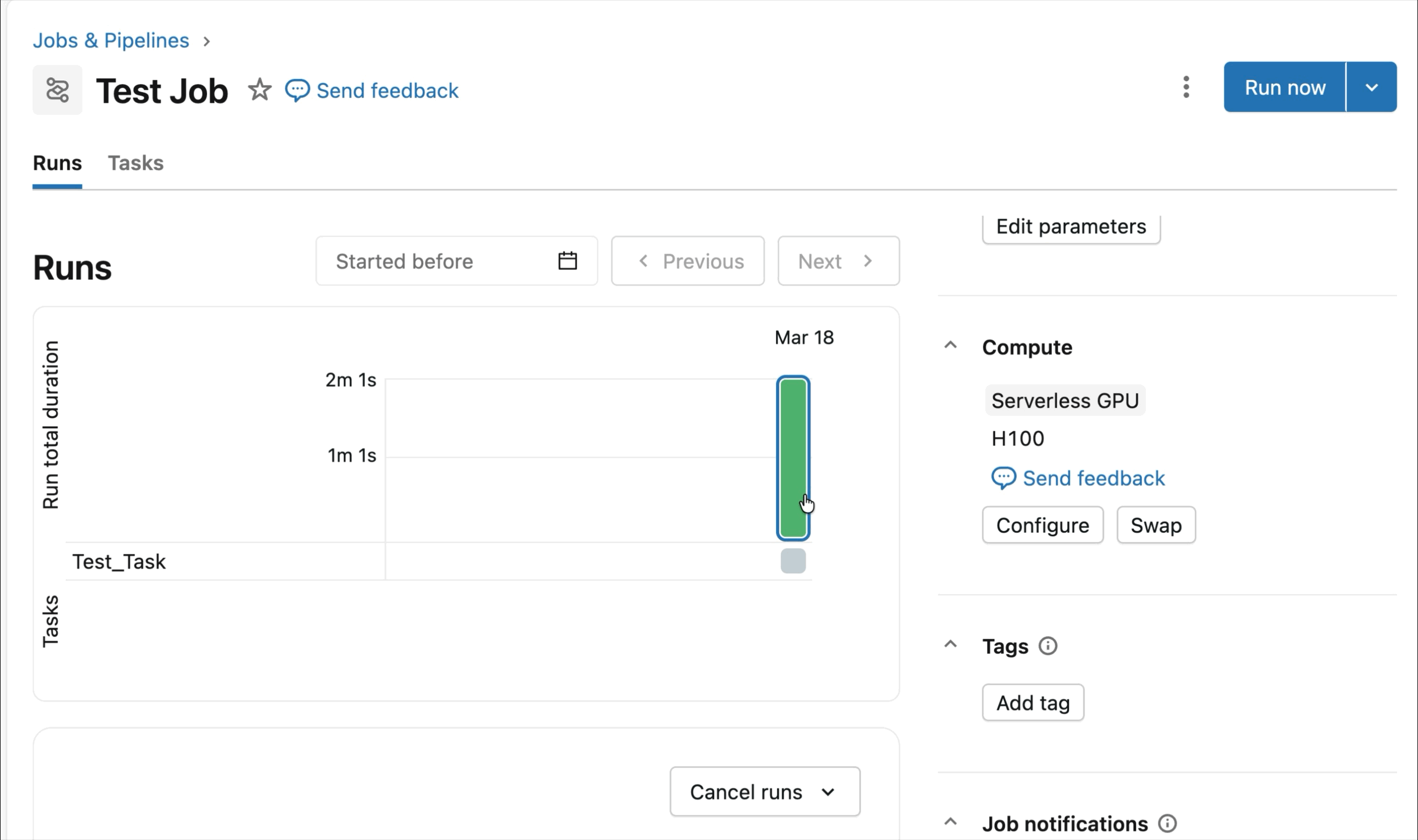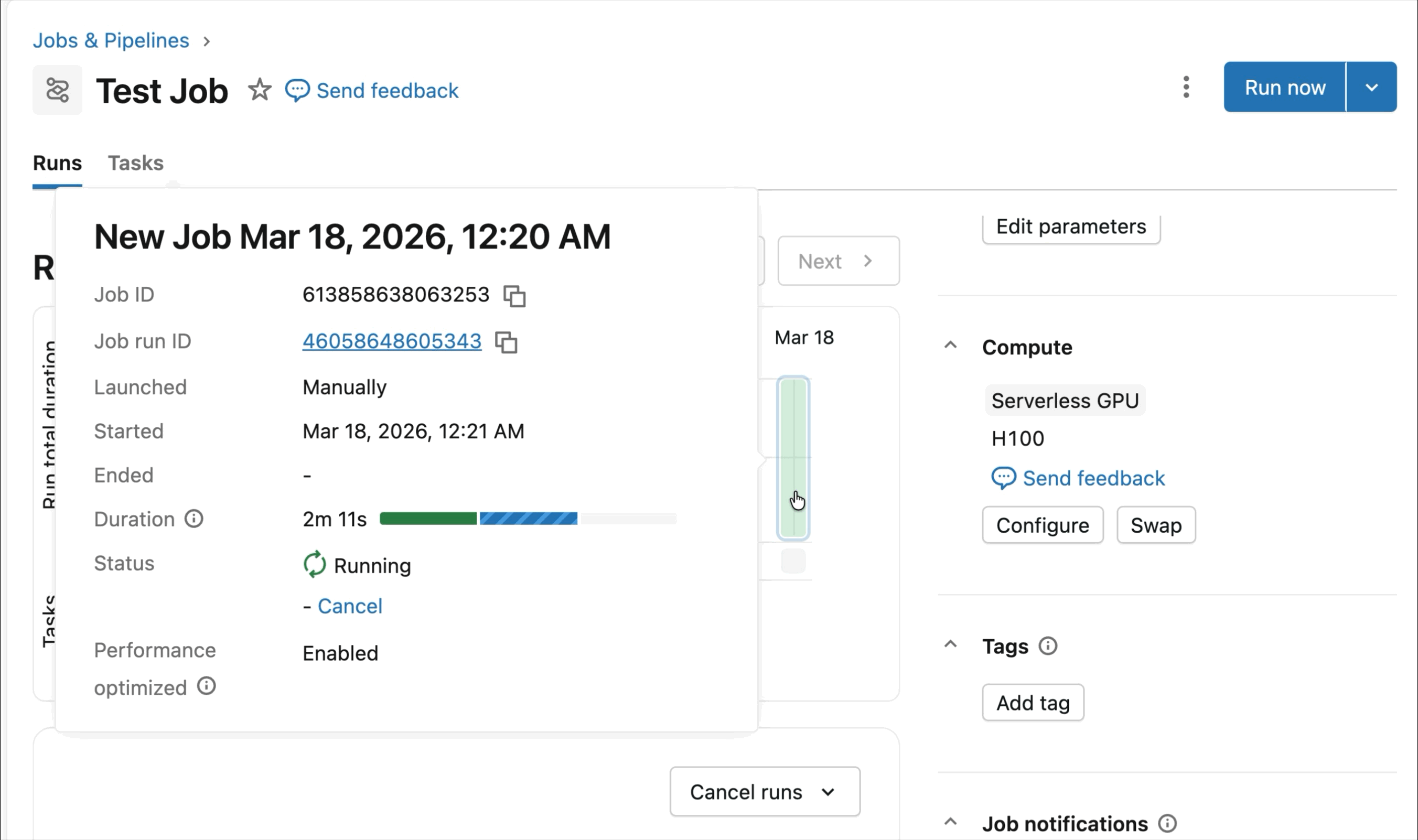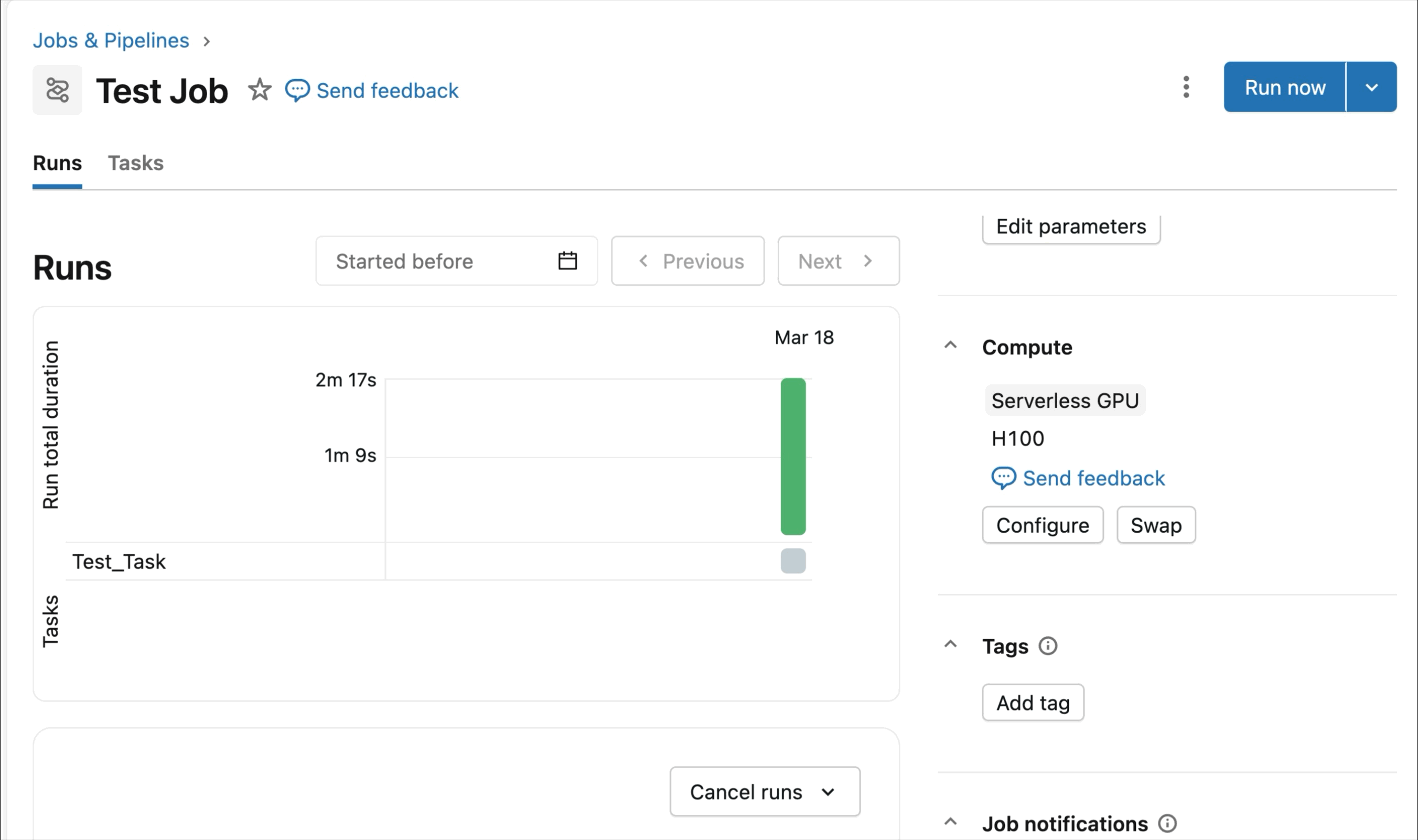
- Serverless, on-demand NVIDIA GPU: Configure your notebook in just 2-3 clicks, and connect to serverless fast A10 and H100 GPU To start training – no cluster required. Pay only for the GPUs you use without worrying about idle time usage.
- Strong orchestration tools: Harness the full power of Databricks’ orchestration suite with Lakeflow Jobs and DAB support for long-running GPU workloads
- Customized Delivered Training: AIR bundles deliver GPU performance enhancements such as RDMA and high-performance data loading
- Centralized governance and oversight: Run, inspect, and control GPU workloads where your data lives, with built-in experiment management through MLflow, access management with Unity Catalog, and agent-assisted debugging.
On-demand NVIDIA H100 and A10 GPUs in notebooks
Connect on-demand A10s and H100s to Databricks notebooks with just a few clicks, for interactive development and debugging. From there, take advantage of all the developer ergonomics that Databricks is known for, from environment management to agent-driven authoring and debugging for common Python packages. genie code. Easily mount data from Lakehouse to train deep learning models, or even deploy a fleet of remote CPUs to Spark data processing workloads from your GPU-powered notebook to prepare your data.
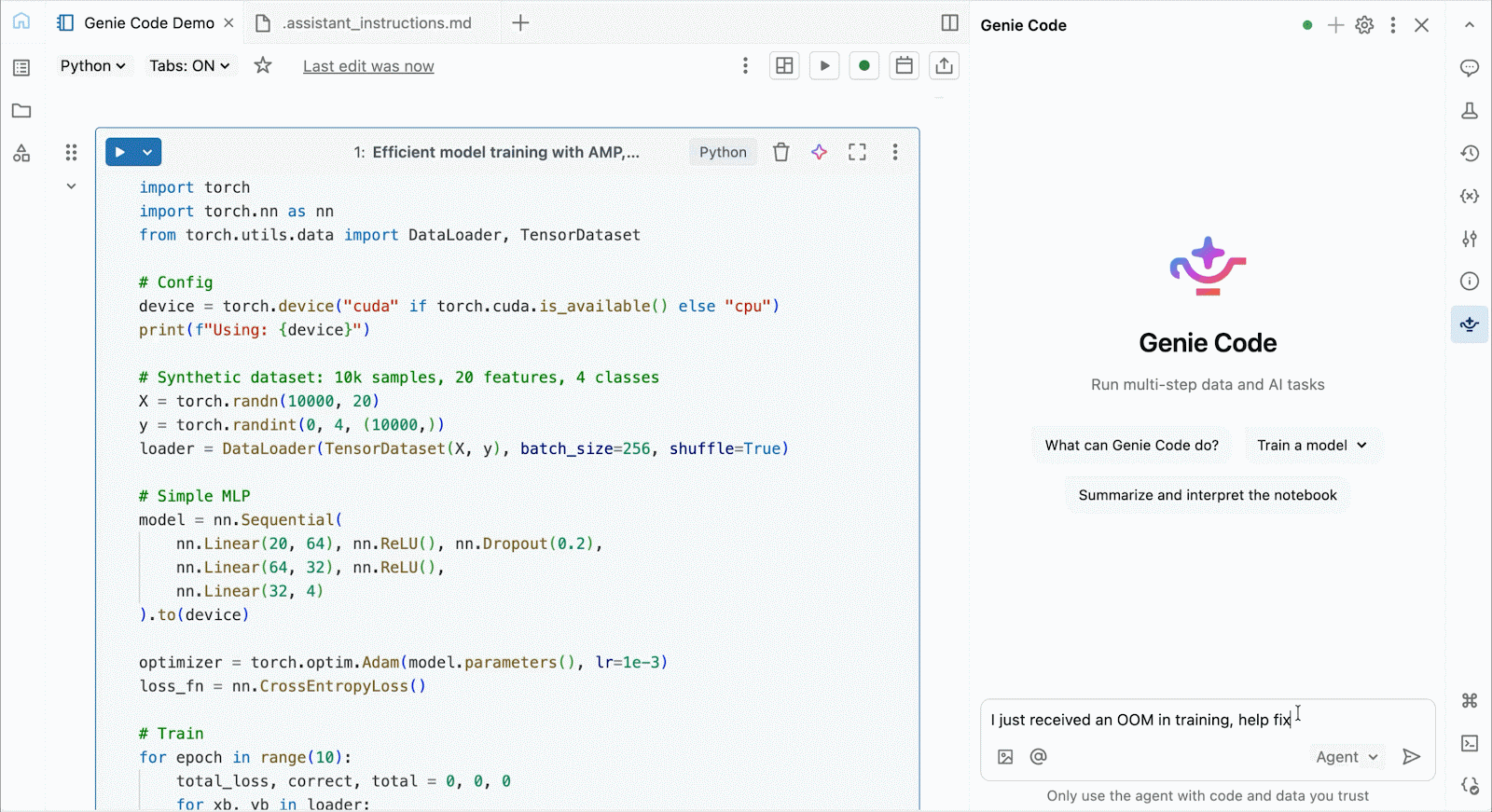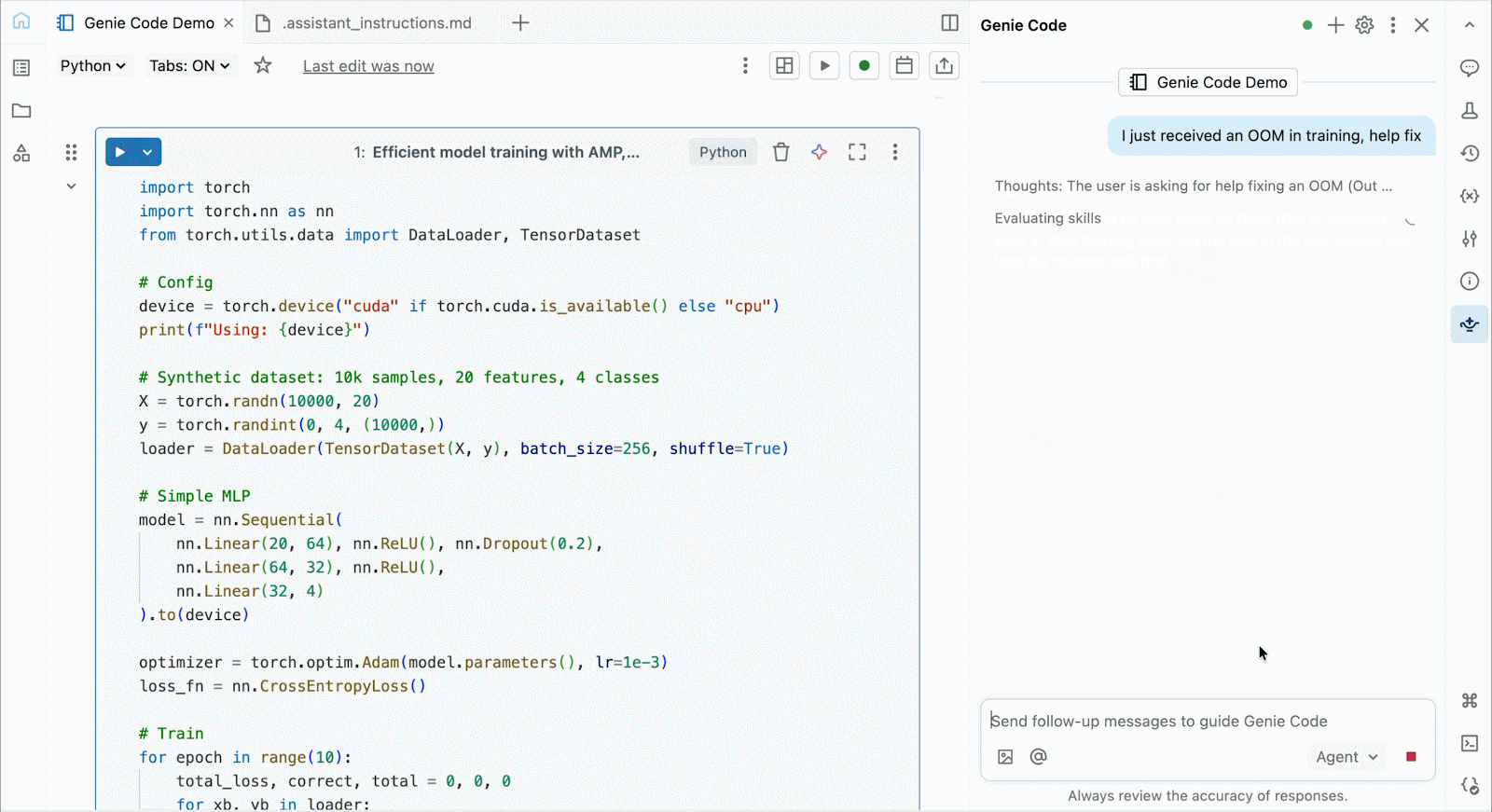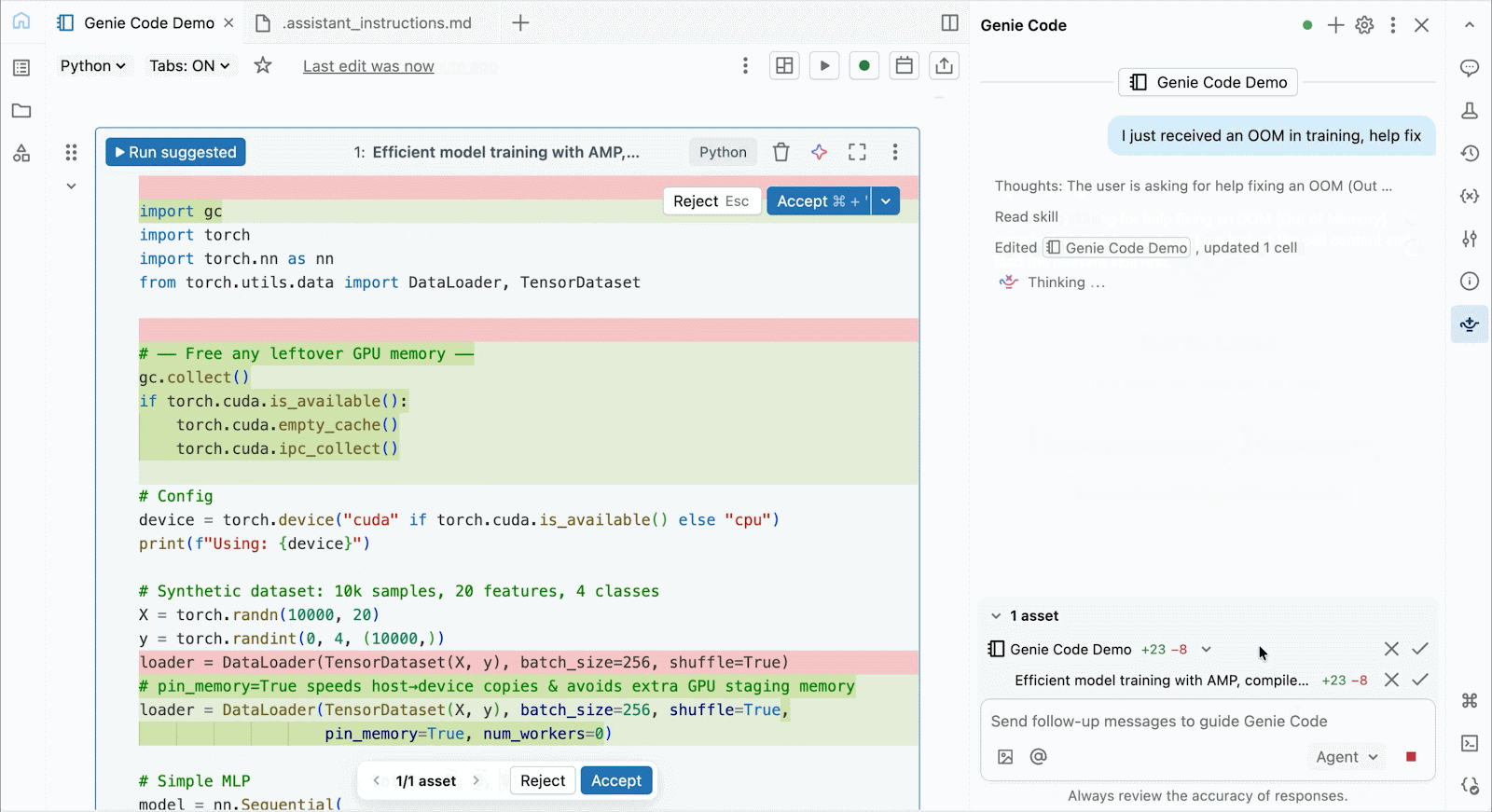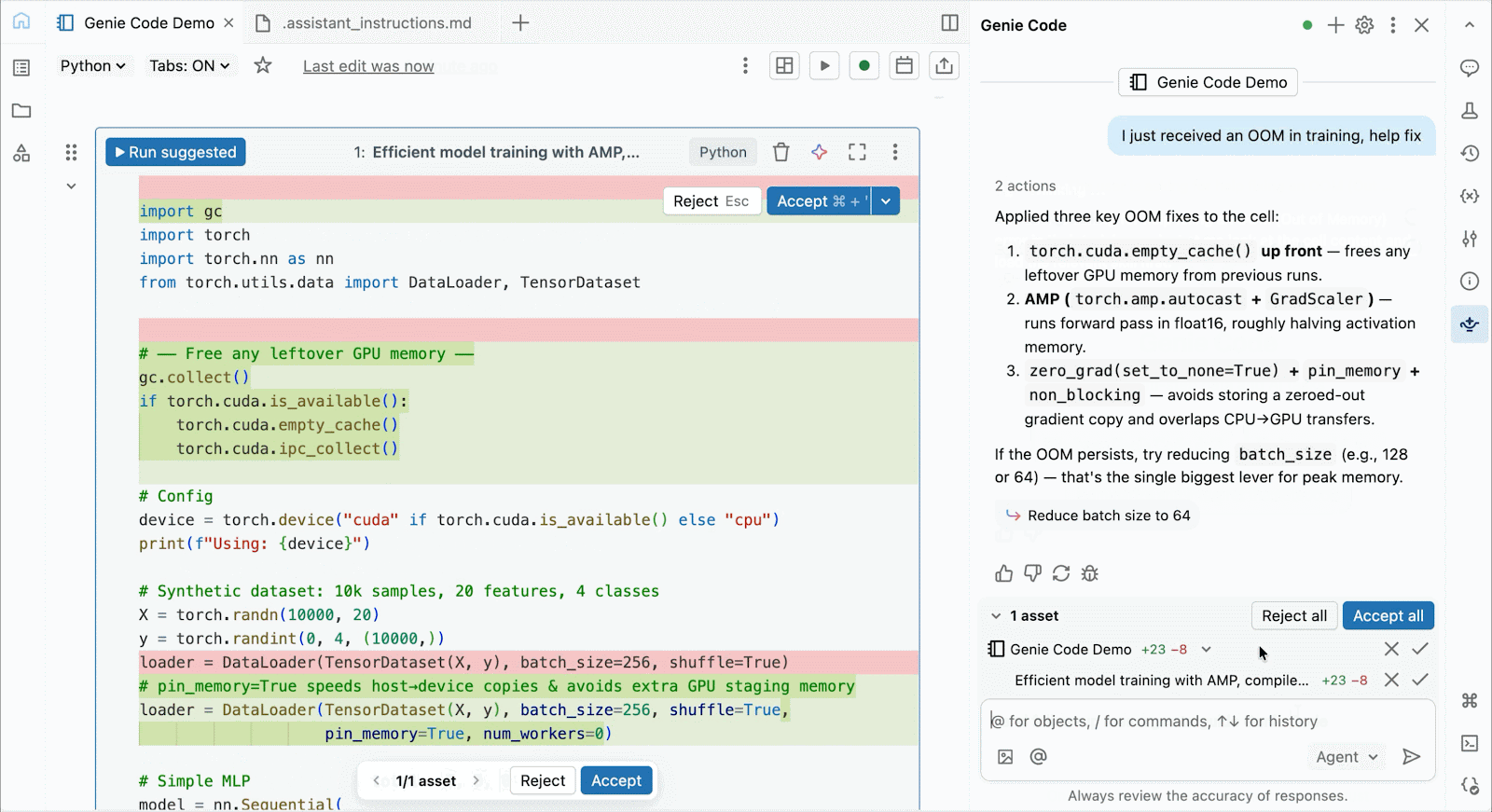
Use Genie code to help solve performance bottlenecks, experiment with new architectures, or debug tricky bugs around model convergence or cryptic framework errors.
Lakeflow for production-ready workloads
AI Runtime is a production-grade platform for accelerated computing. Develop your deep learning code in an interactive notebook, and then harness its full power lake flow Submitting and organizing tasks on GPU compute. Both notebooks and custom code repositories can be executed by Lakeflow for long-running or scheduled tasks. For production requirements such as CI/CD (continuous integration and continuous deployment), the AI runtime is fully compatible with our Declarative Automation Bundle (DAB).
With our Lakeflow integration, customers can keep model training and fine-tuning tightly synchronized with upstream data pipelines and downstream production systems.
“Databricks’ AI Runtime greatly streamlined the process of training a custom Text to Formula (TTF) model. With no infrastructure setup or delays, it was easy to choose the right calculation based on instant size and output token generation. This allowed us to move forward quickly, maintain our Lakehouse workflow, and deliver a high quality model with full administration, reducing the time it took to setup, train, and deploy our model from days to hours. “Reduced to.”– Nikhil Sundarraj Principal Machine Learning Engineer, FactSet Research Systems, Inc.
Runtime optimized for distributed deep learning
Preparing, debugging, and inspecting distributed training workloads can be painful. From troubleshooting RDMA setup to tracking telemetry from multiple GPUs to proper software configuration, users can easily miss critical details that dramatically slow down model training.
Instead, the AI runtime is optimized for the entire deep learning lifecycle – and designed to save you time. Key dependencies like PyTorch and CUDA come pre-installed, as well as optimized support for distributed training frameworks like Ray, Hugging Face Transformer, Composer, and other libraries, so you can start training immediately without having to manage the environment. Customers are also welcome to bring their own library, from Unsloth to Torchrack to custom training loops.

Integrated SDK and observation tools simplify management of distributed training workloads. MLFflow enables deep observability of GPU workloads, with automated tracking of GPU usage and training experiments. Whether you’re fine-tuning foundation models or training prediction and personalization models, the runtime is optimized to accelerate the training workflow with minimal setup.
Today’s public preview of the AI runtime supports distributed training in 8x H100s in single-node, with multi-node support currently in private preview.
“Databricks’ AI runtime enables us to efficiently run LLM workloads (fine tuning and inference) without infrastructure directly in our lakehouse. This seamless integration simplifies our pipelines and provides efficient use of GPUs, allowing us to deliver high-quality AI insights to our customers and focus on innovation, not infrastructure.”-Lucas Froguel, Senior AI Platform Engineer, Ypitdata
Centralized data governance and observability
The AI Runtime seamlessly integrates with Databricks Lakehouse, enabling you to run GPU workloads and control where your data lives. This eliminates fragmented workflows and streamlines the path from experimentation to production.
- Centralized governance with unity list: Enforce consistent access controls, lineage, and governance policies across both data and AI workloads, enabling secure and compliant use of GPU resources.
- Integrated Observability: Track and monitor all workloads—CPU and GPU—in one place using native system tables for integrated auditing, usage tracking, and operational insights.
Your AI workloads run entirely within your enterprise data perimeter, providing strong governance and security without sacrificing flexibility for experimentation and scale.
“Leveraging Databricks’ serverless GPU support within our Lakehouse enables us to efficiently train advanced audio and multimodal models without the infrastructure overhead. This seamless integration simplifies workflows and provides efficient use of GPU resources, ensuring we deliver high-performance systems and focus on innovation.”– Arjun Shiva, Vice President of Infotainment and Connectivity, Rivian and Volkswagen Group Technologies
Integrating next-generation GPU innovation from NVIDIA
There is an increasing demand for accelerated computation in AI workloads and agentic systems. AI Runtime enables more Databricks customers to leverage NVIDIA hardware to accelerate their AI workloads and advance their business. We’re excited to continue partnering with NVIDIA to bring this Latest NVIDIA TechnologyLike the RTX Pro 4500 Blackwell Server Edition, announced at GTC 2026 for our customers.
“As AI adoption accelerates across industries, organizations need scalable, high-performance infrastructure to power their data and AI workloads. NVIDIA technologies bring accelerated performance to the AI runtime offering for the Databricks Lakehouse platform.”-Pat Lee, Vice President, Strategic Partnerships at NVIDIA.
Get started with AI Runtime today
To help you get started, we’ve put together several template notebooks and starter guides:
- please see our documentation For detailed instructions on setup and daily use.
- starter templates For training recommender systems, classic ML models, fine-tuning LLM and more!
- migration guide From classic compute GPU workloads to serverless.
To learn more or if you have any questions, please contact your account team!