
Question:
Imagine that your company’s LLM API costs suddenly doubled in the last month. In-depth analysis reveals that while user inputs appear different at the text level, many of them are semantically similar. As an engineer, how do you identify and reduce this redundancy without impacting response quality?
What is prompt caching?
Prompt caching is an optimization technique used in AI systems to improve speed and reduce costs. Instead of sending the same long instructions, documents or examples to the model again and again, the system reuses previously processed prompt content such as static instructions, prompt prefixes or shared references. This helps save both input and output tokens while keeping responses consistent.
Consider a travel planning assistant where users frequently ask questions like “Create a 5-day itinerary for Paris focused on museums and food.” Even though different users express it slightly differently, the basic purpose and structure of the request remains the same. Without any optimization, the model has to read and process the full signal every time, repeating the same calculations and increasing both latency and cost.
With prompt caching, once the assistant processes this request for the first time, repeated parts of the prompt – such as itinerary structure, constraints, and general instructions – are stored. When a similar request is sent again, the system reuses the previously processed content instead of starting from the beginning. This results in faster responses and lower API costs, as well as accurate and consistent outputs.

What is cached and where is it stored
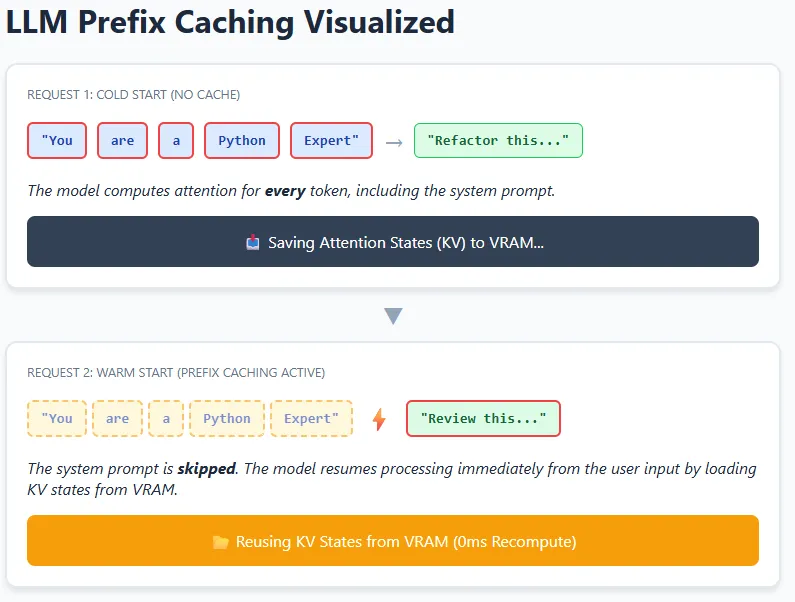
At a high level, caching in LLM systems can occur at different layers – from simple token-level reuse to more advanced reuse of internal model states. In practice, modern LLMs rely primarily on key-value (KV) caching, where the model stores intermediate attention states in GPU memory (VRAM) so that it does not have to recompute them again.
Think of a coding assistant with a fixed system directive like “You are an expert Python code reviewer.” This instruction appears in every request. When the model processes it once, the attention relationships (keys and values) between its tokens are stored. For future requests, the model can reuse these stored KV states and calculate attention only for new user inputs, such as real code snippets.
This idea is extended to requests using prefix caching. If multiple signals start with exactly the same prefix – the same text, formatting, and spacing – the model can skip recalculating that entire prefix and start again from the cached point. This is especially effective in chatbots, agents, and RAG pipelines where system prompts and long instructions rarely change. The result is lower latency and lower computation costs, while still allowing the model to fully understand and respond to the new context.

structure pointers for high cache efficiency
- Place system instructions, roles, and shared context at the beginning of the prompt, and move user-specific or changing content to the end.
- Avoid adding dynamic elements such as timestamps, request IDs, or random formatting to the prefix, as even small changes reduce reuse.
- Ensure that structured data (for example, JSON references) is serialized in a consistent order and format to prevent unnecessary cache misses.
- Regularly monitor cache hit rates and group similar requests together to maximize efficiency at scale.
conclusion
In this case, the goal is to reduce repeated calculations while preserving response quality. An effective approach is to analyze incoming requests to identify shared structure, intent, or common prefixes, and then restructure the signals so that the reusable context remains consistent across all calls. This allows the system to avoid reprocessing the same information repeatedly, leading to lower latency and lower API costs without changing the final output.
For applications with long and repetitive signals, prefix-based reuse can provide significant savings, but it also presents practical constraints – KV caches consume GPU memory, which is limited. As usage scales, cache eviction strategies or memory tiering become necessary to balance performance gains with resource limitations.

I am a Civil Engineering graduate (2022) from Jamia Millia Islamia, New Delhi, and I have a keen interest in Data Science, especially Neural Networks and their application in various fields.